
![]() Bài viết được ghim
Bài viết được ghim

Đóng góp của bài báo
Kết quả training có độ chính xác cao là rất tốt tuy nhiên việc tối ưu thời gian, tài nguyên training và inference của model cũng quan trọng không kém  Được giới thiệu lần đầu vào năm 2020, EfficientNet là một họ các mô hình hiệu suất cao được tối ưu hóa cho việc huấn luyện hiệu quả trên các tác vụ liên quan đến hình ảnh. Với việc kết hợp phương pháp scaling và compound s...
Được giới thiệu lần đầu vào năm 2020, EfficientNet là một họ các mô hình hiệu suất cao được tối ưu hóa cho việc huấn luyện hiệu quả trên các tác vụ liên quan đến hình ảnh. Với việc kết hợp phương pháp scaling và compound s...





Tất cả bài viết

Đóng góp của bài báo
Các bài toán OCR luôn được sự quan tâm trong giới AI nhờ khả năng ứng dụng rộng rãi 😀 Một thách thức lớn mà các model hiện tại gặp phải khi giải quyết bài toán này đó là các scene image được chụp từ nhiều điều kiện môi trường khác nhau, do đó text có thể bị che khuất, mờ, nhiễu,... điều này rất khó để model có thể nhận biết được nội dung text trong ảnh.
Cũng như con người...

Động lực và đóng góp
Real-time object detection là một chủ đề nghiên cứu chưa bao giờ là hết hot do tính ứng dụng thực tiễn cao, một số ứng dụng có thể kể đến đó là object tracking, xe tự hành,... Các mô hình real-time detector hiện tại chủ yếu xây dựng từ kiến trúc CNN có tốc độ inference nhanh nhưng lại là một sự đánh đổi giữa tốc độ và chính xác. Đặc biệt, các mô hình real-time detector này...

Đóng góp của bài báo
Bài báo đóng góp một phương pháp để có thể học biểu diễn video (Video representation learning) một cách hiệu quả. Do lượng video data được gán nhãn còn hạn chế nên việc có một phương pháp có thể tận dụng nguồn data không gán nhãn này là một điều cần thiết.Những năm gần đây trong các bài toán computer vision, có rất nhiều nghiên cứu ứng dụng self-supervised learning để học ...

Abstract Thành công gần đây của deep learning trong việc giải quyết các vấn đề về thị giác máy tính và học máy khác nhau không được thể hiện tốt trong phân tích cấu trúc tài liệu vì mạng nơ-ron thông thường không phù hợp với cấu trúc đầu vào của bài toán. Trong bài báo, nhóm tác giả đề xuất một cấu trúc dựa trên mạng đồ thị là một thay thế tốt hơn so với các mạng neural tiêu chuẩn cho table rec...

Giới thiệu chung
Airflow là gì?
Airflow là một hệ thống mã nguồn mở phát triển bởi Airbnb và sau đó được chuyển giao cho cộng đồng Apache. Được giới thiệu lần đầu vào năm 2014, Airflow trở thành một trong những công cụ quản lý công việc lập lịch và quản lý quy trình hàng đầu trong cộng đồng phân tích dữ liệu và khoa học dữ liệu.
Airflow cho phép người dùng định nghĩa (define), lập lịch (sche...

Giới thiệu
Các bạn tìm hiểu về LLM chắc không còn lạ gì với RLHF (Reinforcement learning with Human Feedback). Đây là kĩ thuật giúp bạn căn chỉnh (align) LLM sử dụng human preference data, giúp tăng chất lượng của pretrained model. Cách tiếp cận của RLHF khá cơ bản như sau:
- Train 1 reward model từ human preference. Human preference ở đây các bạn có thể hiểu là nhãn feedback của con người. Ví...

Giới thiệu
Các mô hình Nhận dạng giọng nói tự động (ASR) đóng một vai trò quan trọng trong cuộc sống và công nghệ hiện đại. Chúng giúp cải thiện khả năng tiếp cận cho người khuyết tật, đặc biệt là những người khiếm thị, bằng cách cho phép họ sử dụng các thiết bị công nghệ thông qua giọng nói. Trong môi trường doanh nghiệp, ASR tiết kiệm thời gian và tăng cường hiệu quả làm việc bằng cách hỗ tr...

Đóng góp của bài báo
Hãy tưởng tượng bạn đang cố gắng đọc một cuốn sách rất dài mà chỉ có thể nhớ được một số trang gần nhất bạn vừa đọc. Điều này giống như vấn đề của các mô hình ngôn ngữ lớn (LLM), các mô hình này khó có thể "nhớ" hoặc xử lý thông tin từ những cuộc trò chuyện hoặc tài liệu dài vì chúng chỉ có khả năng xem xét một lượng thông tin giới hạn tại một thời điểm. Đây chính là vấn đ...

Giới thiệu DVC (Data Version Control) là một công cụ quản lý phiên bản cho dữ liệu (Data Version Control) được sử dụng để quản lý các phiên bản của dữ liệu và các tập tin liên quan đến dữ liệu trong các dự án Machine Learning.
Giống như Git, DVC cũng sử dụng hệ thống quản lý phiên bản (version control) để lưu trữ và quản lý các phiên bản của dữ liệu và các tập tin liên quan đến dữ liệu. DVC ch...
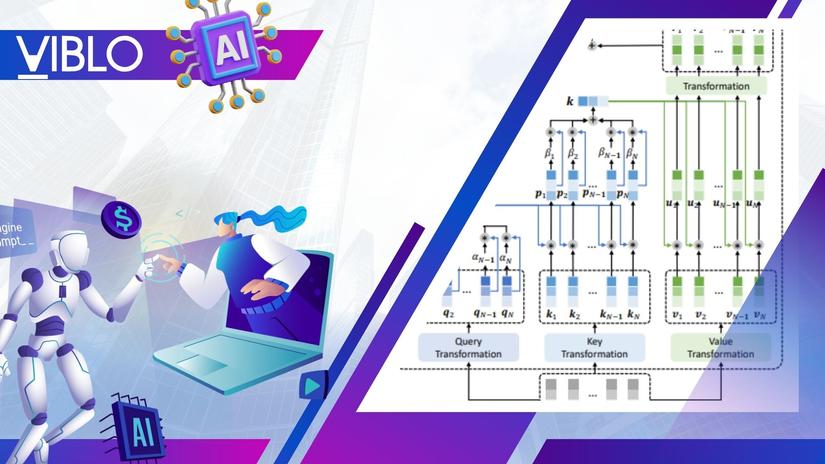
1. Động lực
Transformer là model nổi tiếng với khả năng xử lý trên dữ liệu dạng văn bản một cách mạnh mẽ. Tuy nhiên, điểm trừ lớn của Transformer là độ phức tạp bậc hai với độ dài của chuỗi đầu vào. Trong bài báo, nhóm tác giả đề xuất model Fastformer với mục tiêu tăng độ hiệu quả của model Transformer dựa trên cơ chế additive attention.
2. Đóng góp
Trong Fastformer thay vì modeling tương ...

Giới thiệu chung
Visual Question Answering (VQA) là một bài toán thú vị mô phỏng gần nhất khả năng của con người. Nói một cách ngắn gọn, ta cần huấn luyện máy để có thể thực hiện tương tác hỏi đáp giữa người và máy về một hình ảnh trực quan. Hiện tại, bái toán này chủ yếu thực hiện trên tiếng Anh vì có sẵn các VQA benchmark.
Trong bài báo, nhóm tác giả có 3 đóng góp chính như sau:
- Nhóm tác...

Giới thiệu chung
Việc tăng dung lượng mạng neural đã đạt những thành tựu nhất định với các tác vụ liên quan đến NLP và Computer Vision. Ý tưởng cơ bản là ta "nhồi" thêm dữ liệu và tăng độ phức tạp mô hình để thu về một model khủng có độ chính xác cao. Trong các bài toán NLP, các mô hình như T5, GPT-3, Megatron-Turing, GLAM, Chinchilla, và PaLM đã cho thấy những lợi thế đáng kể từ việc traini...

Tóm tắt Mục tiêu của Few-shot learning là tận dụng tri thức học được từ 1 hoặc nhiều model deep learning để đạt hiệu suất tốt trên một bài toán mới. Bài toán này có đặc điểm là chỉ có một vài mẫu được gán nhãn trong mỗi class. Vấn đề đặt ra là việc sử dụng model trích xuất tri thức chưa thật sự tối ưu, điều này dẫn đến một câu hỏi là cách tiếp cận mới có thật sự mang lại độ chính xác cao hơn so...

Giới thiệu chung
Một vấn đề khi sử dụng các model Deep Learning là không phải lúc nào ta cũng có đủ lượng dữ liệu để train. Khi làm việc với các tác vụ Computer Vision, bạn thỉnh thoảng (hoặc thường xuyên ) gặp vấn đề đó là chỉ có 1-2 mẫu trên một class. Đây là một vấn đề ảnh hưởng rất nhiều tới độ chính xác của model. Với một đứa trẻ, chỉ cần chỉ cho chúng 1 hình ảnh con mèo thì các lần sau...

Giới thiệu
Các mô hình học máy đã bắt đầu thâm nhập vào các lĩnh vực quan trọng, yêu cầu về tính bảo mật và độ chính xác cao như y tế, hệ thống tư pháp và ngành tài chính. Do đó, việc giải thích tại sao mô hình lại đưa ra dự đoán như vậy là một điều cần thiết, nó giúp ta đảm bảo sự tin tưởng khi áp dụng mô hình vào thực tế. 
Trong khi đó, sự tăng trưởng nhanh chóng của các mô hình học sâu l...

Feature selection là một bước cơ bản trong các Machine learning pipeline. Ta có trong tay một đống "thập cẩm" các feature, công việc bây giờ là chọn những feature quan trọng và bỏ những feature không cần thiết đi. Mục tiêu là đơn giản hóa vấn đề bằng cách xóa đi các feature có thể dẫn đến nhiễu không cần thiết.
Boruta là một thuật toán hiệu quả được thiết kế để tự động thực hiện feature select...

Giới thiệu chung
Ngoài các model CNN thì các model họ Transformer cũng đạt những kết quả ấn tượng khi sử dụng trong các task về Computer Vision như object detection, image classification, semantic segmentation,... Mô hình Transformer đầu tiên được sử dụng trong Computer Vision là ViT (Vision Transformer) đã cho những kết quả SOTA tại thời điểm ra mắt. Các mô hình Transformer cải tiến khác cho ...

Đa phần trong chúng ta khi thực hiện feature-selection đều sử dụng "SelectFromModel" (một module của Scikit-learn). Thường thì công việc ta sẽ làm như sau:
- Bạn chọn một mô hình dự đoán (ta sẽ gọi nó là WhatevBoost)
- Thực hiện fit WhatevBoost với tất cả feature
- Trích xuất những feature quan trọng từ WhatevBoost
- Loại bỏ tất cả những feature có threshold thấp hơn mong muốn và giữ lại nh...

Nếu từng tham gia các cuộc thi trên Kaggle, bạn sẽ thấy rằng, chỉ cần chênh lệch 0.01% kết quả cũng sẽ làm bạn thằng $100.000 hoặc không có gì trong tay Lấy ví dụ về cuộc thi Data Science Bowl 2017 Giải thưởng $500.000 cho đội được giải nhất, 200.000 cho đội đứng thứ hai và 100.000 cho đội đứng thứ ba. Metric dùng để đánh giá là log-loss. Dưới đây là bảng xếp hạng của cuộc thi
Nhìn thử vào...

Giới thiệu chung
Một vấn đề khi sử dụng các model Deep Learning là không phải lúc nào ta cũng có đủ lượng dữ liệu để train. Khi làm việc với các tác vụ Computer Vision, bạn thỉnh thoảng (hoặc thường xuyên ) gặp vấn đề đó là chỉ có 1-2 mẫu trên một class. Đây là một vấn đề ảnh hưởng rất nhiều tới độ chính xác của model. Với một đứa trẻ, chỉ cần chỉ cho chúng 1 hình ảnh con mèo thì các lần sau...
