Paper reading | VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Việc sử dụng một model pretrained tốt là rất cần thiết để giải quyết những bài toán yêu cầu độ chính xác cao mà không phải train lại từ đầu. Các model pretrained này cần có khả năng tổng quát hóa tốt để có thể áp dụng vào các downstream task khác nhau. Trong xử lý ngôn ngữ tự nhiên, ta đã nghe rất nhiều tới mô hình ngôn ngữ lớn (large language model - LLM), việc mở rộng kích thước mô hình và lượng dữ liệu training là rất quan trọng để cải thiện hiệu suất model. Trong các model hình ảnh, ta có một số mô hình self-supervised pretraining ấn tượng như BEiT, MAE, VideoMAE,... sử dụng Transformer với masked autoencoding. Tuy nhiên, với các model pretraining hình ảnh, rất ít nghiên cứu về việc scale up masked autoencoder pretraining, một phần là do dữ liệu nhiều chiều và chi phí tính toán lớn. Vấn đề này đặc biệt khó khăn để giải quyết đối với dữ liệu là video do có thêm chiều thời gian và độ dài thời gian video khác nhau.
Do đó, mục tiêu của bài báo là thực hiện nghiên cứu việc scale model VideoMAE và tăng hiệu suất của mô hình trên nhiều video downstream task khác nhau. Việc scale model Video MAE được thực hiện trên cả model và data. Với model, VideoMAE được khởi tạo với model ViT gồm hàng tỷ tham số. Với data, nhóm tác giả tăng lượng dữ liệu data training lên hàng triệu để phát huy tối đa sức mạnh của model ViT lớn  Tuy nhiên, việc scale này có nhiều thách thức:
Tuy nhiên, việc scale này có nhiều thách thức:
- Chi phí tính toán và bộ nhớ là rất lớn. Mặc dù VideoMAE đã có cơ chế drop một lượng lớn token nhưng thời gian train vẫn rất lâu và cần sử dụng nhiều GPU mạnh.
- Lượng video data ít hơn rất nhiều so với data ảnh.
- Khó khăn về việc sử dụng các model pretrained lớn cho VideoMAE. Lý do, việc finetuning từ model pretrained lớn trên tập dữ liệu video ít là chưa tối ưu, lượng video được gán nhãn ít có thể làm cho model bị overfit.
Nhóm tác giả đề xuất model VideoMAE V2 nhằm giải quyết các vấn đề train. Với model này, ta có thể train video transformer model với hàng tỷ tham số và đạt các kết quả SOTA trên nhiều downstream task bao gồm action recognition, spatial action detection và temporal action detection.
Phương pháp
Sơ lược VideoMAE
Nhóm tác giả lựu chọn scale model VideoMAE do model này đơn giản mà hiệu suất vẫn cao VideoMAE sẽ xử lý các frame được downsample từ một video clip với stride và sử dụng cube embedding để biến đổi các frame thành một chuỗi các token. Sau đó, ta sẽ thực hiện drop một số token với tỉ lệ drop cao (90%). Cuối cùng, các unmasked token sẽ được đưa vào một video autoencoder (, ) để tái tạo lại các masked pixel.
Cụ thể, VideoMAE gồm 3 thành phần chính:
- Cube embedding có nhiệm vụ encode các local spatiotemporal feature và xây dựng danh sách token , trong đó là chuỗi các token, là token được tạo bởi lớp embedding và sau đó được cộng positional embedding, là số lượng token.
- Encoder có nhiệm vụ thực hiện các thao tác trên các unmasked token sử dụng model ViT kết hợp joint space-time attention: trong đó là các unmasked token, , là masking map và token có độ dài tương đương
- Decoder có nhiệm vụ nhận token làm đầu vào và thực hiện tái tạo token bị mask thông qua ViT: , trong đó token là concat các chuỗi encoded token feature với các learnable masked token
[MASK], lưu ý rằng[MASK]vẫn được cộng với postion embedding. Token có độ dài tương đương với số lượng token . Hàm loss được sử dụng là MSE tính loss giữa các masked pixel đã được chuẩn hóa với các pixel được tái tạo .
Dual Masking cho VideoMAE
Nhóm tác giả đề xuất một cơ chế dual masking để có thể scale VideoMAE pretraining trong điều kiện hạn chế về tài nguyên tính toán.
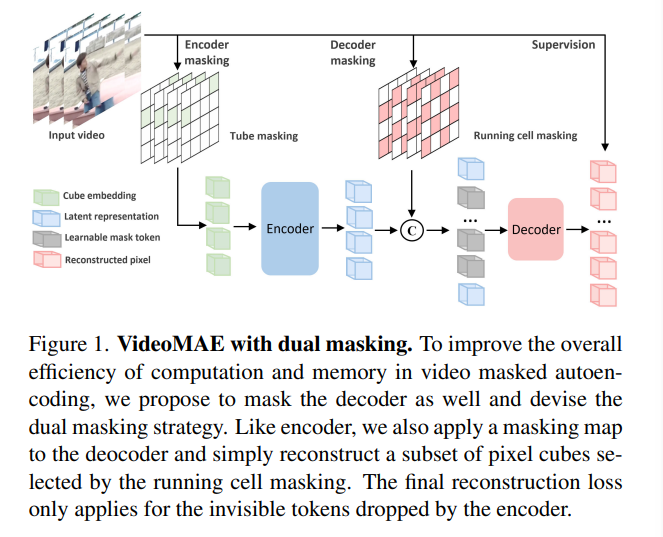
Cơ chế dual masking này sẽ gồm 2 masking map và với chiến lược masking và tỉ lệ masking khác nhau. Masking map cho encoder và cho decoder. Giống như VideoMAE, đầu vào cho encoder là các unmasked token sau khi đi qua encoder
mask . Nhưng khác với VideoMAE, phần decoder nhận đầu vào là các unmasked token sau khi đi qua encoder và các token bị mask sau khi đi qua decoder mask . Trong phần này, nhóm tác giả sử dụng decoder mask để giảm độ dài đầu vào cho decoder, hướng tới mục tiêu giảm lượng tính toán nhưng vẫn duy trì được lượng thông tin như quá trình reconstruction toàn bộ
VideoMAEv2 sử dụng cube embedding và encoder giống như VideoMAE. Tuy nhiên, decoder trong VideoMAEv2 có đầu vào là sự kết hợp giữa các token là output của encoder và một phần các masked token sau khi đi qua decoder mask . Cụ thể, sự kết hợp các token này được định nghĩa như sau:

trong đó là biểu diễn ẩn từ encoder, là learnable masking token với positional embedding tương ứng.
Cài đặt cho Tube Masking và Running Cell Masking (như trong sơ đồ tổng quan của mô hình) như sau:
class TubeMaskingGenerator:
def __init__(self, input_size, mask_ratio):
self.frames, self.height, self.width = input_size
self.num_patches_per_frame = self.height * self.width # 14x14
self.total_patches = self.frames * self.num_patches_per_frame
self.num_masks_per_frame = int(mask_ratio * self.num_patches_per_frame)
self.total_masks = self.frames * self.num_masks_per_frame
def __repr__(self):
repr_str = "Tube Masking: total patches {}, mask patches {}".format(
self.total_patches, self.total_masks)
return repr_str
def __call__(self):
mask_per_frame = np.hstack([
np.zeros(self.num_patches_per_frame - self.num_masks_per_frame),
np.ones(self.num_masks_per_frame),
])
np.random.shuffle(mask_per_frame)
mask = np.tile(mask_per_frame, (self.frames, 1))
return mask # [196*8]
class RunningCellMaskingGenerator:
def __init__(self, input_size, mask_ratio=0.5):
self.frames, self.height, self.width = input_size
self.mask_ratio = mask_ratio
num_masks_per_cell = int(4 * self.mask_ratio)
assert 0 < num_masks_per_cell < 4
num_patches_per_cell = 4 - num_masks_per_cell
self.cell = Cell(num_masks_per_cell, num_patches_per_cell)
self.cell_size = self.cell.size
mask_list = []
for ptr_pos in range(self.cell_size):
self.cell.set_ptr(ptr_pos)
mask = []
for _ in range(self.frames):
self.cell.run_cell()
mask_unit = self.cell.get_cell().reshape(2, 2)
mask_map = np.tile(mask_unit,
[self.height // 2, self.width // 2])
mask.append(mask_map.flatten())
mask = np.stack(mask, axis=0)
mask_list.append(mask)
self.all_mask_maps = np.stack(mask_list, axis=0)
def __repr__(self):
repr_str = f"Running Cell Masking with mask ratio {self.mask_ratio}"
return repr_str
def __call__(self):
mask = self.all_mask_maps[np.random.randint(self.cell_size)]
return np.copy(mask)
Cuối cùng, MSE loss được tính giữa các normalized masked pixel và các pixel được tái tạo .
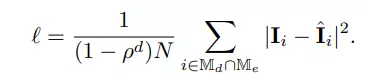
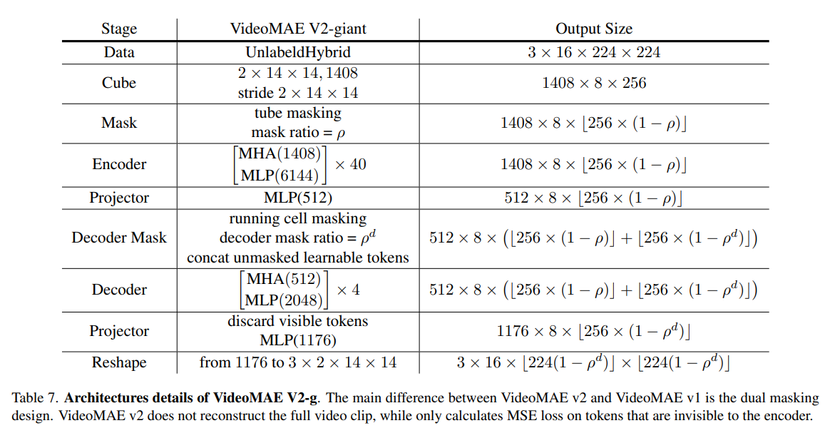
Tổng quan kiến trúc của model VideoMAE V2 như sau
Thực nghiệm
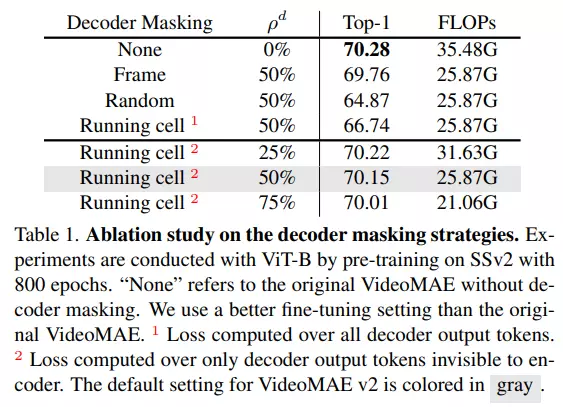
Nhóm tác giả thực hiện thí nghiệm để đánh giá tác động của việc decoder masking với chiến lược và tỉ lệ masking khác nhau. Kết quả được thể hiện trong bảng dưới. 1 thể hiện cho việc ta sẽ tính loss trên toàn bộ các token đầu ra của decoder. 2 thể hiện cho việc ta tính loss chỉ trên các token đầu ra của decoder mà không được nhìn thấy từ encoder. Mặc dù accuracy nhỏ hơn so với việc không masking nhưng chiến lược này là tradeoff giữa accuracy và độ phức tạp tính toán cụ thể FLOPs khi thực hiện masking ít hơn so với không thực hiện masking.
Bảng dưới so sánh kết quả giữa việc sử dụng dual masking với chỉ masking tại encoder. Nhận thấy rằng khi sử dụng dual masking thì tốc độ tăng lên lần lượt là 1,79 lần (khi sử dụng backbone là ViT-B) và 1,48 lần (khi sử dụng backbone là ViT-g).

Bảng dưới là kết quả trên tập dữ liệu Kinetics-400.

Bảng dưới là kết quả trên tập dữ liệu Something-Something V2.

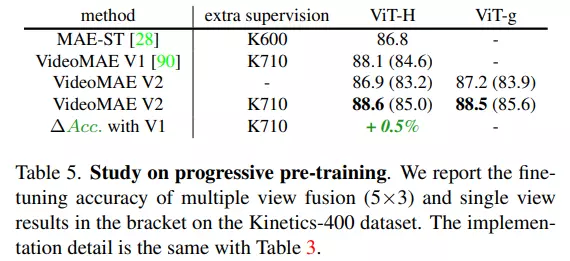
Bảng dưới là kết quả mô hình khi bổ sung thêm bước hậu xử lý để hạn chế overfitting. Việc hậu xử lý này đều làm tăng kết quả cho pretrained model với cả 2 backbone ViT-H và ViT-g.
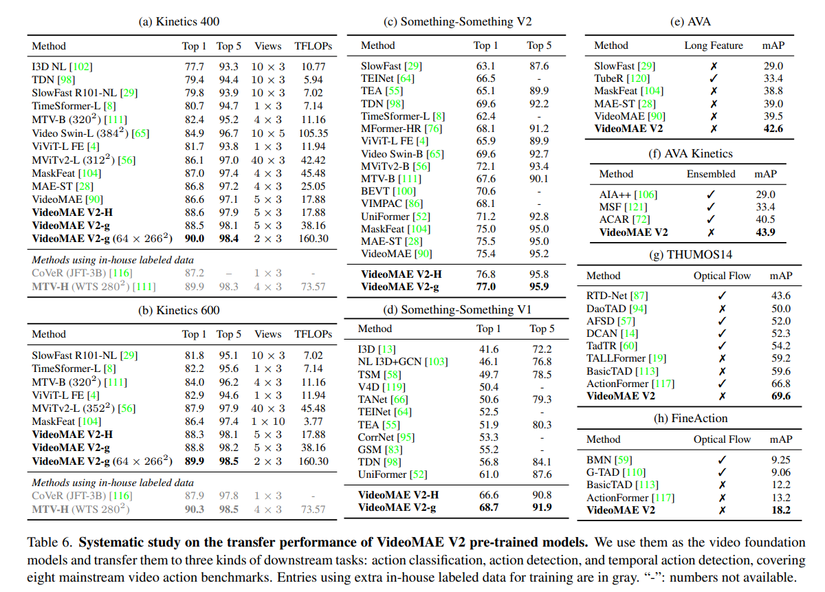
Bảng dưới là kết quả tổng hợp trên các downstream task khác nhau: action classification, action detection và temporal action detection.
Tham khảo
[1] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
All rights reserved
