Paper reading | EfficientNetV2: Smaller Models and Faster Training
This post hasn't been updated for 2 years
Đóng góp của bài báo
Kết quả training có độ chính xác cao là rất tốt tuy nhiên việc tối ưu thời gian, tài nguyên training và inference của model cũng quan trọng không kém  Được giới thiệu lần đầu vào năm 2020, EfficientNet là một họ các mô hình hiệu suất cao được tối ưu hóa cho việc huấn luyện hiệu quả trên các tác vụ liên quan đến hình ảnh. Với việc kết hợp phương pháp scaling và compound scaling, EfficientNet đạt được một sự cân đối giữa hiệu suất và tài nguyên tính toán, giúp mô hình này trở thành một trong những mô hình phổ biến trong lĩnh vực thị giác máy tính.
Được giới thiệu lần đầu vào năm 2020, EfficientNet là một họ các mô hình hiệu suất cao được tối ưu hóa cho việc huấn luyện hiệu quả trên các tác vụ liên quan đến hình ảnh. Với việc kết hợp phương pháp scaling và compound scaling, EfficientNet đạt được một sự cân đối giữa hiệu suất và tài nguyên tính toán, giúp mô hình này trở thành một trong những mô hình phổ biến trong lĩnh vực thị giác máy tính.
Bài báo giới thiệu EfficientNetV2 là một phiên bản cải tiến của EfficientNet, đề xuất bởi nhóm nghiên cứu tại Google Brain. Phiên bản này tiếp tục tối ưu hóa kiến trúc mạng và thêm vào một số cải tiến để nâng cao hiệu suất. Một số điểm nổi bật của EfficientNetV2 bao gồm:
-
EfficientNetV2 sử dụng Fused-MBConv: Cấu trúc này kết hợp các phép tính trong các lớp MBConv (Mobile Inverted Residual Bottleneck) để tạo ra các lớp thứ cấp, giúp giảm tải tính toán và tăng tốc quá trình huấn luyện.
-
Multi-Scale Hidden Resolutions: EfficientNetV2 sử dụng nhiều kích thước độ phân giải ẩn, cho phép mô hình phát hiện đặc trưng ở nhiều tỷ lệ khác nhau trong cùng một lớp.
-
Stochastic Depth: Stochastic Depth cho phép mô hình huấn luyện một lớp với một xác suất dropout ngẫu nhiên, từ đó giảm hiện tượng vanishing gradient và cải thiện khả năng học của mô hình.
-
EfficientNetV2 cũng giữ lại các đặc điểm chính của EfficientNet như compound scaling: Mô hình vẫn tối ưu hóa các thông số quan trọng như chiều rộng, chiều sâu và độ phân giải để đạt được hiệu suất tốt với các tài nguyên tính toán nhất định.
EfficientNetV2 đã được thử nghiệm trên nhiều tập dữ liệu và tác vụ khác nhau trong lĩnh vực thị giác máy tính, bao gồm nhận dạng đối tượng, phân loại ảnh, phát hiện vật thể, và nhiều tác vụ khác. Hiệu suất của mô hình thể hiện kết quả ấn tượng trong việc đạt được độ chính xác cao với tài nguyên tính toán tương đối ít.
Thiết kế mô hình EfficientNetV2
Nhắc lại đôi chút về EfficientNet
EfficientNet là một họ các mô hình được tối ưu FLOPs (floating-point operations per second) và lượng tham số. Mô hình baseline EfficientNet-B0 được xây dựng từ NAS (Neural architecture search) và đạt được sự cân bằng tối ưu giữa độ chính xác và FLOPs . Từ baseline model, nhóm tác giả thực hiện scale up với chiến lược compound scaling để thu được một họ các model B1 tới B7. Bảng dưới so sánh các thông số của EfficientNet so với các mô hình SOTA trước đó.
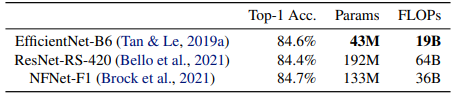
Nếu như bạn chưa biết thì Neural Architecture Search (NAS) là một phương pháp trong lĩnh vực học máy nhằm tự động tìm kiếm kiến trúc tốt nhất cho một mạng neural dựa trên các tiêu chí hoặc hàm mục tiêu đã cho trước. Mục tiêu của NAS là tối ưu hóa kiến trúc mạng để đạt được hiệu suất cao trên các tác vụ khác nhau.
Mục tiêu của bài báo là giới thiệu phiên bản cải tiến của EfficientNet giúp tăng tốc độ training trong khi vẫn duy trì lượng tham số tối ưu.
Các vấn đề với EfficientNet
Mặc dù nổi bật với độ chính xác cao và FLOPs thấp, EfficientNet (hay EfficientNetV1) vẫn tồn tại một số nhược điểm như sau:
Tốc độ training với ảnh có kích thước lớn rất chậm. Với input là ảnh có kích thước lớn dẫn đến việc cần sử dụng lượng bộ nhớ đáng kể. Vì tổng bộ nhớ trên GPU/TPU là cố định nên ta cần phải giảm batch size để có thể training được mô hình và điều này làm cho quá trình training trở nên chậm lại. Một cách đơn giản để khắc phục điều này là sử dụng kích thước ảnh nhỏ hơn cho quá trình training so với quá trình inference. Như mô tả trong bảng dưới, kích thước ảnh nhỏ hơn dẫn đến việc tính toán ít hơn và cho phép sử dụng kích thước batch lớn hơn, từ đó cải thiện tốc độ huấn luyện lên đến 2.2 lần. Đáng chú ý, việc sử dụng kích thước ảnh nhỏ hơn trong quá trình training cũng dẫn đến độ chính xác tốt hơn một chút .

Vấn đề về Depthwise convolutions. Một vấn đề khó khăn trong quá trình training EfficientNet xuất phát từ việc sử dụng depthwise convolutions. Depthwise convolution có ít tham số và FLOPs hơn so với convolutions thông thường, nhưng thường không thể tận dụng tối đa tốc độ tính toán trên các accelerator hiện đại. Fused-MBConv được đề xuất để tận dụng sức mạnh các accelerator dành cho di động hoặc server. Nó thay thế depthwise conv3x3 và expansion conv1x1 trong MBConv bằng một convolution thông thường conv3x3 duy nhất, như được mô tả trong hình dưới.
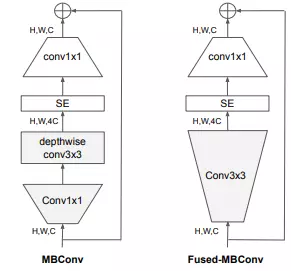
Kết quả sau khi thay đổi được thể hiện trong bảng dưới.
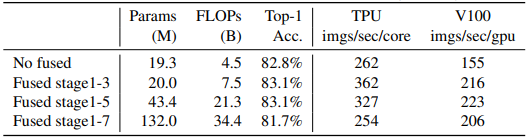
Khi áp dụng ở các giai đoạn đầu từ 1 tới 3, Fused-MBConv có thể cải thiện tốc độ huấn luyện với một overhead nhỏ về tham số và FLOPs, nhưng nếu chúng ta thay thế tất cả các khối bằng Fused-MBConv (giai đoạn 1-7), thì nó tăng đáng kể tham số và FLOPs và cũng làm chậm quá trình huấn luyện . Tìm sự kết hợp đúng đắn giữa block MBConv và Fused-MBConv không phải là điều dễ dàng, điều này thúc đẩy việc sử dụng NAS để tự động tìm kiếm sự kết hợp tối ưu nhất.
Việc scale như nhau ở mọi giai đoạn là không tối ưu. EfficientNet thực hiện scale up ở tất cả các giai đoạn bằng cách sử dụng compound scaling rule. Ví dụ, khi hệ số depth (độ sâu) là 2, thì tất cả các giai đoạn trong mạng sẽ tăng gấp đôi số lượng layer. Tuy nhiên, các giai đoạn này không đóng góp một cách đồng đều vào tốc độ huấn luyện và độ hiệu quả về tham số. Trong bài báo, ta sẽ xem xét một chiến lược scale up hiệu quả thay vì thực hiện scale up ở tất cả các giai đoạn như EfficientNetV1.
EfficientNetV2
EfficientNetV2 có những cải tiến giúp giải quyết các vấn đề đã nêu trong phần trên. Trong phần này ta sẽ cùng tìm hiểu những thay đổi và ảnh hưởng của nó đến chất lượng mô hình.
Kết hợp MBConv và Fused-MBConv
Như đề cập trong phần trên đó là việc sử dụng MBConv không tận dụng được tối đa sức mạnh phần cứng (GPU/TPU). Do đó, ta sử dụng các Fused-MBConv để có thể tận dụng tối đa tài nguyên phần cứng này. Nhóm tác giả thực hiện đưa cả MBConv và Fused-MBConv vào trong NAS, mục tiêu là để tự động tìm kiếm cách kết hợp các block này sao cho thu được hiệu suất tối ưu nhất cả về độ chính xác và tốc độ training.
Sử dụng NAS search để tối ưu độ chính xác, số lượng tham số và chất lượng training
NAS được sử dụng để cho ra kiến trúc mô hình tối ưu nhất. Ban đầu, mô hình EfficientNetV1 được sử dụng làm backbone. Sau đó, NAS thực hiện đưa ra các thiết kế khác nhau cho kiến trúc mô hình, bao gồm thay đổi các lớp Conv, số lượng layer, kích thước filter, expansion ratio,... Cuối cùng, mô hình có hiệu suất tối ưu nhất về độ chính xác, thời gian training và số lượng tham số được sử dụng làm base model của EfficientNetV2. Hình dưới là kiến trúc mô hình EfficientNetV2-S.
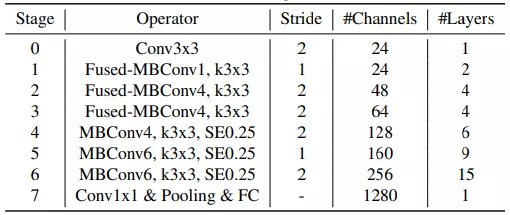
Nhận thấy rằng EfficientNetV2-S có expansion ratio nhỏ hơn so với EfficientNet-B0. Bên cạnh đó, EfficientNetV2 không sử dụng filter có kích thước 5x5 mà chỉ sử dụng filter có kích thước 3x3.
Model Scaling hiệu quả hơn
Sau khi xác định được kiến trúc cho mô hình EfficientNetV2-S, vấn đề bây giờ là ta sẽ thực hiện scale model như nào để cho ra các phiên bản EfficientNetV2-M và EfficientNetV2-L Chiến lược Compound scaling được sử dụng, ý tưởng thì tương tự như EfficientNet nhưng sẽ có một số thay đổi để làm cho mô hình nhỏ hơn và nhanh hơn, đó là:
- Kích thước ảnh tối đa là 480x480 pixel nhằm giảm lượng bộ nhớ sử dụng trên GPU/TPU, do đó làm tăng tốc độ training.
- Bổ sung nhiều layer ở các stage cuối (ở các stage 5 và 6) để tăng kích thước mô hình mà không làm tăng thời gian training.
Progressive learning
Kích thước ảnh càng lớn có xu hướng làm cho kết quả training trở nên tốt hơn nhưng điều này làm tăng thời gian training. Bài báo đề xuất việc thay đổi động kích thước ảnh trong quá trình training nhưng đồng thời cũng phải thay đổi regularization để tránh việc làm giảm độ chính xác của mô hình.
Để kiểm chứng giả thuyết trên, nhóm tác giả thực hiện các thí nghiệm thay đổi kích thước ảnh và các kĩ thuật augmentation khác nhau. Như trong bảng dưới, khi kích thước ảnh nhỏ, việc sử dụng augmentation yếu hơn cho kết quả tốt hơn. Tuy nhiên, với kích thước ảnh lớn, việc sử dụng augmentation mạnh hơn cũng cho kết quả tốt hơn.
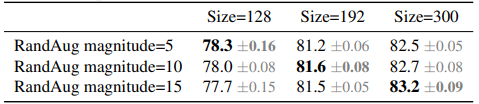
Từ giả thuyết trên, bài báo đề xuất một chiến lược có tên Progressive Learning with Adaptive Regularization. Chiến lược này được mô tả như sau, tại các step đầu tiên, mô hình được train trên ảnh có kích thước nhỏ với regularization yếu. Điều này cho phép mô hình học các feature một cách nhanh hơn. Sau đó, kích thước của ảnh dần dần được tăng lên, như đã thảo luận ở trên thì regularization cũng phải mạnh theo

Lúc này quá trình học của mô hình cũng trở nên khó hơn (học kĩ hơn ) Kết quả của chiến lược này là làm cho mô hình có độc chính xác cao hơn, training nhanh hơn và hạn chế overfitting. Hình dưới mô tả chiến lược này.

Các tham số như kích thước ảnh và regularization được định nghĩa từ đầu. Sau đó linear interpolation được sử dụng để tăng kích thước ảnh và thay đổi các regularization sau một stage cụ thể (M). Các loại regularization được sử dụng là Dropout, RandAugment và Mixup.
Thực nghiệm
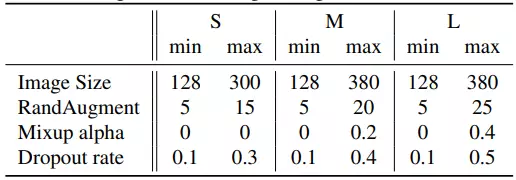
Bảng dưới là setting cho progressive training của EfficientNetV2.
Bảng dưới là hiệu suất của EfficientNetV2 trên tập dữ liệu ImageNet so sánh với các mô hình SOTA.
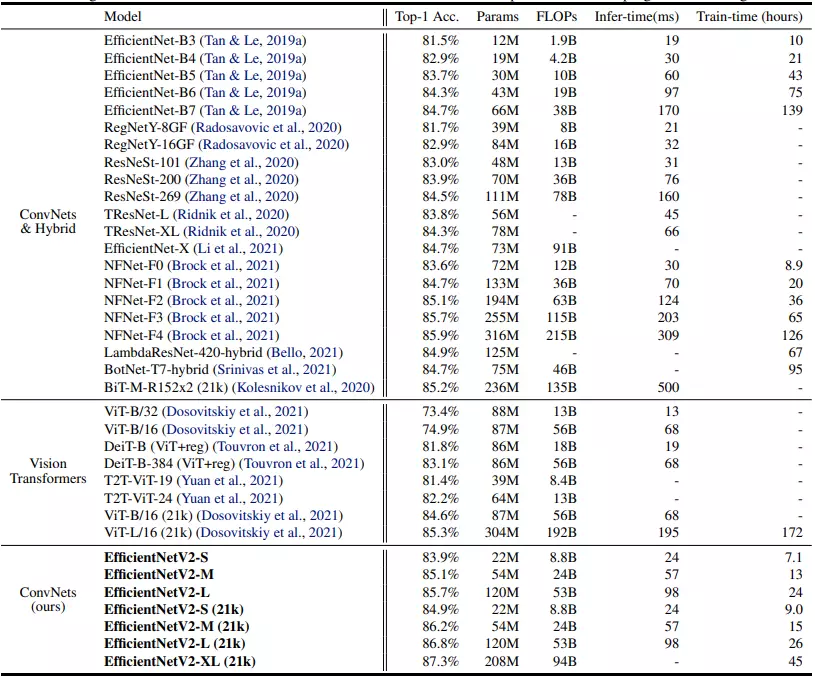
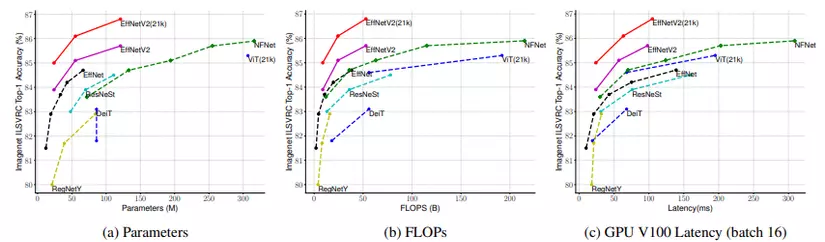
Mô hình EfficientNetV2 có lượng tham số gần gần với EfficientNet nhưng tốc độ inference nhanh hơn gấp 3 lần.
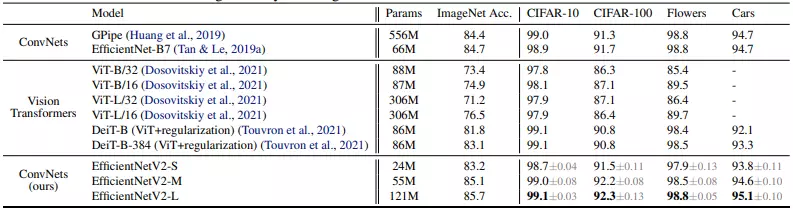
Bảng dưới so sánh kết quả khi thực hiện Transfer learning. Tất cả các model được pretrain trên ImageNet ILSVRC2012 và sau đó được finetune trên các tập dữ liệu downstream.
Coding
Bên dưới là cài đặt mô hình với các phiên bản khác nhau của EfficientNetV2.
import torch
import torch.nn as nn
import math
__all__ = ['effnetv2_s', 'effnetv2_m', 'effnetv2_l', 'effnetv2_xl']
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# SiLU (Swish) activation function
if hasattr(nn, 'SiLU'):
SiLU = nn.SiLU
else:
# For compatibility with old PyTorch versions
class SiLU(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, inp, oup, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, _make_divisible(inp // reduction, 8)),
SiLU(),
nn.Linear(_make_divisible(inp // reduction, 8), oup),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
SiLU()
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
SiLU()
)
class MBConv(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio, use_se):
super(MBConv, self).__init__()
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.identity = stride == 1 and inp == oup
if use_se:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
SELayer(inp, hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# fused
nn.Conv2d(inp, hidden_dim, 3, stride, 1, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.identity:
return x + self.conv(x)
else:
return self.conv(x)
class EffNetV2(nn.Module):
def __init__(self, cfgs, num_classes=1000, width_mult=1.):
super(EffNetV2, self).__init__()
self.cfgs = cfgs
# building first layer
input_channel = _make_divisible(24 * width_mult, 8)
layers = [conv_3x3_bn(3, input_channel, 2)]
# building inverted residual blocks
block = MBConv
for t, c, n, s, use_se in self.cfgs:
output_channel = _make_divisible(c * width_mult, 8)
for i in range(n):
layers.append(block(input_channel, output_channel, s if i == 0 else 1, t, use_se))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# building last several layers
output_channel = _make_divisible(1792 * width_mult, 8) if width_mult > 1.0 else 1792
self.conv = conv_1x1_bn(input_channel, output_channel)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Linear(output_channel, num_classes)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.001)
m.bias.data.zero_()
def effnetv2_s(**kwargs):
"""
Constructs a EfficientNetV2-S model
"""
cfgs = [
# t, c, n, s, SE
[1, 24, 2, 1, 0],
[4, 48, 4, 2, 0],
[4, 64, 4, 2, 0],
[4, 128, 6, 2, 1],
[6, 160, 9, 1, 1],
[6, 256, 15, 2, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_m(**kwargs):
"""
Constructs a EfficientNetV2-M model
"""
cfgs = [
# t, c, n, s, SE
[1, 24, 3, 1, 0],
[4, 48, 5, 2, 0],
[4, 80, 5, 2, 0],
[4, 160, 7, 2, 1],
[6, 176, 14, 1, 1],
[6, 304, 18, 2, 1],
[6, 512, 5, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_l(**kwargs):
"""
Constructs a EfficientNetV2-L model
"""
cfgs = [
# t, c, n, s, SE
[1, 32, 4, 1, 0],
[4, 64, 7, 2, 0],
[4, 96, 7, 2, 0],
[4, 192, 10, 2, 1],
[6, 224, 19, 1, 1],
[6, 384, 25, 2, 1],
[6, 640, 7, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_xl(**kwargs):
"""
Constructs a EfficientNetV2-XL model
"""
cfgs = [
# t, c, n, s, SE
[1, 32, 4, 1, 0],
[4, 64, 8, 2, 0],
[4, 96, 8, 2, 0],
[4, 192, 16, 2, 1],
[6, 256, 24, 1, 1],
[6, 512, 32, 2, 1],
[6, 640, 8, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
Tham khảo
[1] EfficientNetV2: Smaller Models and Faster Training
[2] https://github.com/google/automl/tree/master
All Rights Reserved
