Tìm hiểu về Swin Transformers
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung
Ngoài các model CNN thì các model họ Transformer cũng đạt những kết quả ấn tượng khi sử dụng trong các task về Computer Vision như object detection, image classification, semantic segmentation,... Mô hình Transformer đầu tiên được sử dụng trong Computer Vision là ViT (Vision Transformer) đã cho những kết quả SOTA tại thời điểm ra mắt. Các mô hình Transformer cải tiến khác cho Computer Vision cũng lần lượt ra đời. Trong bài báo Swin Transformer: Hierarchical Vision Transformer using Shifted Windows đề xuất mô hình Swin Transformer có thể mô hình hóa sự khác biệt giữa sự thay đổi về tỷ lệ của đối tượng và độ phân giải của ảnh đầu vào hiệu quả hơn, cũng như có thể đóng vai trò là một pipeline tổng quát cho các bài toán Computer Vision.
Trong bài viết này ta sẽ review qua một số ý tưởng quan trọng của Swin Transformers và tìm hiểu xem tại sao model này lại hoạt động tốt ở các task Computer Vision.
Tại sao CNN lại phù hợp với các task trong Computer Vision
Bài báo đưa ra quan sát dựa trên nền tảng lý thuyết về lý do tại sao CNNs lại hiệu quả để mô hình hóa các miền trong tầm nhìn. Một số nhược điểm của Transformers đối với dữ liệu hình ảnh bao gồm:
- Không như word token trong NLP, các phần tử visual có kích thước, độ phân giải khác nhau. Đặc biệt trong object detection.
- Với ảnh có độ phân giải cao và các task Computer Vision yêu cầu dự đoán ở pixel-level là không thể thực hiện được với transformer vì độ phức tạp tính toán và bộ nhớ sử dụng của self-attention là bình phương của kích thước ảnh. Nếu đã thử so sánh việc train các model CNN và các model Transformers, đa phần bạn sẽ nhận thấy một điều rằng việc train các model Transformers thường rất lâu và yêu cầu nhiều bộ nhớ sử dụng, dễ xảy ra tình trạng OOM (out of memory).
Kiến trúc mô hình
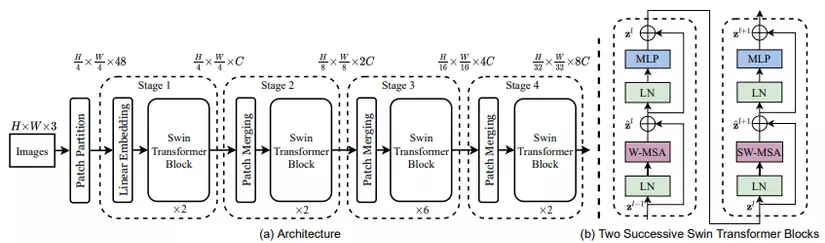
Quan sát kiến trúc, bạn sẽ thấy có 4 block đặc biệt trong mô hình trên. Đầu tiên, ảnh input RGB được chia thành các patch bởi Patch Partition layer. Mỗi patch có kích thước (3 là kênh màu RGB) và được coi như là một token. Các patch này được đi qua Linear embedding layer và được chiếu thành 1 không gian chiều giống như trong ViT.
Kiến trúc mô hình bao gồm nhiều stage (4 stage cho Swin-T). Các stage này được xây dựng bằng cách kết nối Patch merging layer với Swin Transformer block.
Swin Transformer block được xây dựng dựa trên việc chỉnh sửa self-attention. Một block bao gồm multi-head self-attention (MSA), layer normalization và 2 layer MLP. Block này có vai trò là computational backbone trong mạng. Số token được duy trì xuyên suốt qua các Transformer block.
Hierarchical representation (biểu diễn phân cấp) được thực hiện thông qua các Patch merging layer. Lớp Patch Merging có nhiệm vụ làm giảm số lượng các token bằng cách gộp 4 patch (4 hàng xóm 2x2) thành 1 patch duy nhất (ảnh minh họa trên), như vậy số lượng token khi đi qua Stage 2 sẽ là H/8 x W/8 và độ dài của 1 token là 4C chiều (do gộp 4 path làm 1). Sau đó, các token sẽ được đưa qua 1 lớp Linear để giảm số chiều thành 2C và tiếp tục đưa qua một vài các Swin Transformer Block. Tương tự với các Stage 3 và 4, output của từng Stage lần lượt là H/16 x H/16 x 4C và H/32 x W/32 x 8C.
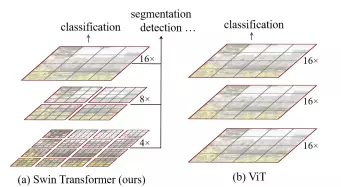
Nếu nhìn dưới góc độ như một mạng CNN thì ta có thể coi Merging layer là pooling layer và transformer block là conv layer. Cách tiếp cận này cho phép mạng có thể detect các object với các kích thước khác nhau một cách hiệu quả.
Shifted Windows
Vì Vision Transformer sử dụng self attention trên toàn bộ ảnh gây ra vấn đề là độ phức tạp của thuật toán sẽ tăng theo số patch. Mà số patch thì phụ thuộc vào kích cỡ ảnh đầu vào cũng như phụ thuộc vào bài toán mà chúng ta cần giải quyết (VD: những bài toán như segmentation yêu cầu dense prediction hoặc yêu cầu phải duy trì high resolution của ảnh thì chúng ta không thể để patch ảnh có kích thước quá lớn dẫn đến việc số lượng patch nhiều và làm tăng chi phí tính toán theo bậc 2 của ảnh đầu vào). Shifted window giúp giải quyết vấn đề này.
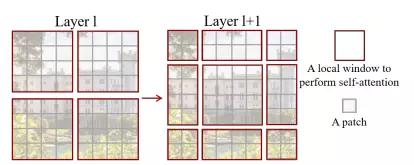
Sử dụng Shifted window với mục tiêu là tính self-attention trong local window. Một local window bao gồm patch không overlap () và self attention được tính toán giữa các patch trên cùng 1 cửa sổ thay vì tính self-attention giữa các path trên toàn bộ bức ảnh. Kết quả là MSA ban đầu có độ phức tạp bình phương của trong khi Window-based MSA là tuyến tính.
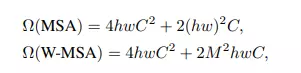
Theo paper, việc thêm relative position bias cho tính toán self-attention làm tăng độ hiệu quả, sử dụng công thức bên dưới
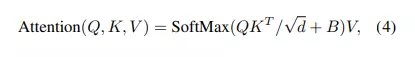
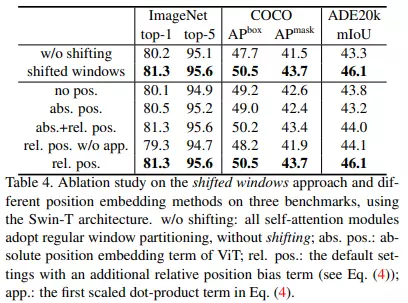
Kết quả thực nghiệm cho thấy sự hiệu quả được thể hiện trong bảng dưới
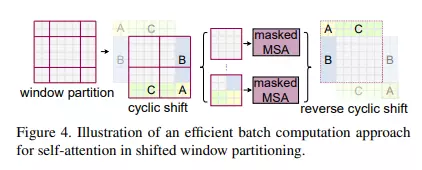
Efficient shifting
Để xử lý hiệu quả cho các window ở viền có kích thước nhỏ hơn , paper đề xuất ý tưởng là dịch chuyển theo tính chu kỳ, việc tính self attention sẽ được thực hiện trên 4 vùng cửa số giống với lúc chưa dịch và điều này tiết kiệm chi phí tính toán.
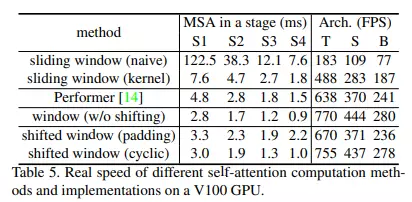
Nhóm tác giả xác nhận cách tiếp cận làm giảm độ trễ của mạng từ Performer, một trong những kiến trúc Transformer nhanh nhất. Giảm thời gian infer là rất quan trọng vì sau này nó có thể được đánh đổi với độ chính xác bằng cách sử dụng các mạng lớn hơn.
Cài đặt
Ta thử implement model Swin Transformer với bộ dữ liệu CIFAR-100 sử dụng Tensorflow
Import library
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow import keras
from tensorflow.keras import layers
Chuẩn bị dữ liệu
num_classes = 100
input_shape = (32, 32, 3)
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar100.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print(f"x_train shape: {x_train.shape} - y_train shape: {y_train.shape}")
print(f"x_test shape: {x_test.shape} - y_test shape: {y_test.shape}")
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i])
plt.show()
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
169009152/169001437 [==============================] - 3s 0us/step
169017344/169001437 [==============================] - 3s 0us/step
x_train shape: (50000, 32, 32, 3) - y_train shape: (50000, 100)
x_test shape: (10000, 32, 32, 3) - y_test shape: (10000, 100)

Config các hyperparameter
Một tham số quan trọng cần chọn là patch_size, kích thước của input patch. Để sử dụng từng pixel làm đầu vào riêng lẻ, bạn có thể đặt patch_size thành (1, 1). Dưới đây, ta sử dụng config như paper gốc.
patch_size = (2, 2) # 2-by-2 sized patches
dropout_rate = 0.03 # Dropout rate
num_heads = 8 # Attention heads
embed_dim = 64 # Embedding dimension
num_mlp = 256 # MLP layer size
qkv_bias = True # Convert embedded patches to query, key, and values with a learnable additive value
window_size = 2 # Size of attention window
shift_size = 1 # Size of shifting window
image_dimension = 32 # Initial image size
num_patch_x = input_shape[0] // patch_size[0]
num_patch_y = input_shape[1] // patch_size[1]
learning_rate = 1e-3
batch_size = 128
num_epochs = 40
validation_split = 0.1
weight_decay = 0.0001
label_smoothing = 0.1
Helper functions
Tạo 2 helper function để hỗ trợ tạo các patch từ hình ảnh, merge patch và sử dụng dropout
def window_partition(x, window_size):
_, height, width, channels = x.shape
patch_num_y = height // window_size
patch_num_x = width // window_size
x = tf.reshape(
x, shape=(-1, patch_num_y, window_size, patch_num_x, window_size, channels)
)
x = tf.transpose(x, (0, 1, 3, 2, 4, 5))
windows = tf.reshape(x, shape=(-1, window_size, window_size, channels))
return windows
def window_reverse(windows, window_size, height, width, channels):
patch_num_y = height // window_size
patch_num_x = width // window_size
x = tf.reshape(
windows,
shape=(-1, patch_num_y, patch_num_x, window_size, window_size, channels),
)
x = tf.transpose(x, perm=(0, 1, 3, 2, 4, 5))
x = tf.reshape(x, shape=(-1, height, width, channels))
return x
class DropPath(layers.Layer):
def __init__(self, drop_prob=None, **kwargs):
super(DropPath, self).__init__(**kwargs)
self.drop_prob = drop_prob
def call(self, x):
input_shape = tf.shape(x)
batch_size = input_shape[0]
rank = x.shape.rank
shape = (batch_size,) + (1,) * (rank - 1)
random_tensor = (1 - self.drop_prob) + tf.random.uniform(shape, dtype=x.dtype)
path_mask = tf.floor(random_tensor)
output = tf.math.divide(x, 1 - self.drop_prob) * path_mask
return output
Window based multi-head self-attention
Thường thì Transformer sẽ thực hiện global self-attention, trong đó mối quan hệ giữa một token với tất cả các token khác được tính toán. Tuy nhiên, ta sẽ thực hiện như trong bài báo là tính self-attention cho local window.
class WindowAttention(layers.Layer):
def __init__(
self, dim, window_size, num_heads, qkv_bias=True, dropout_rate=0.0, **kwargs
):
super(WindowAttention, self).__init__(**kwargs)
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
self.scale = (dim // num_heads) ** -0.5
self.qkv = layers.Dense(dim * 3, use_bias=qkv_bias)
self.dropout = layers.Dropout(dropout_rate)
self.proj = layers.Dense(dim)
def build(self, input_shape):
num_window_elements = (2 * self.window_size[0] - 1) * (
2 * self.window_size[1] - 1
)
self.relative_position_bias_table = self.add_weight(
shape=(num_window_elements, self.num_heads),
initializer=tf.initializers.Zeros(),
trainable=True,
)
coords_h = np.arange(self.window_size[0])
coords_w = np.arange(self.window_size[1])
coords_matrix = np.meshgrid(coords_h, coords_w, indexing="ij")
coords = np.stack(coords_matrix)
coords_flatten = coords.reshape(2, -1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.transpose([1, 2, 0])
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.relative_position_index = tf.Variable(
initial_value=tf.convert_to_tensor(relative_position_index), trainable=False
)
def call(self, x, mask=None):
_, size, channels = x.shape
head_dim = channels // self.num_heads
x_qkv = self.qkv(x)
x_qkv = tf.reshape(x_qkv, shape=(-1, size, 3, self.num_heads, head_dim))
x_qkv = tf.transpose(x_qkv, perm=(2, 0, 3, 1, 4))
q, k, v = x_qkv[0], x_qkv[1], x_qkv[2]
q = q * self.scale
k = tf.transpose(k, perm=(0, 1, 3, 2))
attn = q @ k
num_window_elements = self.window_size[0] * self.window_size[1]
relative_position_index_flat = tf.reshape(
self.relative_position_index, shape=(-1,)
)
relative_position_bias = tf.gather(
self.relative_position_bias_table, relative_position_index_flat
)
relative_position_bias = tf.reshape(
relative_position_bias, shape=(num_window_elements, num_window_elements, -1)
)
relative_position_bias = tf.transpose(relative_position_bias, perm=(2, 0, 1))
attn = attn + tf.expand_dims(relative_position_bias, axis=0)
if mask is not None:
nW = mask.get_shape()[0]
mask_float = tf.cast(
tf.expand_dims(tf.expand_dims(mask, axis=1), axis=0), tf.float32
)
attn = (
tf.reshape(attn, shape=(-1, nW, self.num_heads, size, size))
+ mask_float
)
attn = tf.reshape(attn, shape=(-1, self.num_heads, size, size))
attn = keras.activations.softmax(attn, axis=-1)
else:
attn = keras.activations.softmax(attn, axis=-1)
attn = self.dropout(attn)
x_qkv = attn @ v
x_qkv = tf.transpose(x_qkv, perm=(0, 2, 1, 3))
x_qkv = tf.reshape(x_qkv, shape=(-1, size, channels))
x_qkv = self.proj(x_qkv)
x_qkv = self.dropout(x_qkv)
return x_qkv
Swin Transformer model
class SwinTransformer(layers.Layer):
def __init__(
self,
dim,
num_patch,
num_heads,
window_size=7,
shift_size=0,
num_mlp=1024,
qkv_bias=True,
dropout_rate=0.0,
**kwargs,
):
super(SwinTransformer, self).__init__(**kwargs)
self.dim = dim # number of input dimensions
self.num_patch = num_patch # number of embedded patches
self.num_heads = num_heads # number of attention heads
self.window_size = window_size # size of window
self.shift_size = shift_size # size of window shift
self.num_mlp = num_mlp # number of MLP nodes
self.norm1 = layers.LayerNormalization(epsilon=1e-5)
self.attn = WindowAttention(
dim,
window_size=(self.window_size, self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
)
self.drop_path = DropPath(dropout_rate)
self.norm2 = layers.LayerNormalization(epsilon=1e-5)
self.mlp = keras.Sequential(
[
layers.Dense(num_mlp),
layers.Activation(keras.activations.gelu),
layers.Dropout(dropout_rate),
layers.Dense(dim),
layers.Dropout(dropout_rate),
]
)
if min(self.num_patch) < self.window_size:
self.shift_size = 0
self.window_size = min(self.num_patch)
def build(self, input_shape):
if self.shift_size == 0:
self.attn_mask = None
else:
height, width = self.num_patch
h_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
w_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
mask_array = np.zeros((1, height, width, 1))
count = 0
for h in h_slices:
for w in w_slices:
mask_array[:, h, w, :] = count
count += 1
mask_array = tf.convert_to_tensor(mask_array)
# mask array to windows
mask_windows = window_partition(mask_array, self.window_size)
mask_windows = tf.reshape(
mask_windows, shape=[-1, self.window_size * self.window_size]
)
attn_mask = tf.expand_dims(mask_windows, axis=1) - tf.expand_dims(
mask_windows, axis=2
)
attn_mask = tf.where(attn_mask != 0, -100.0, attn_mask)
attn_mask = tf.where(attn_mask == 0, 0.0, attn_mask)
self.attn_mask = tf.Variable(initial_value=attn_mask, trainable=False)
def call(self, x):
height, width = self.num_patch
_, num_patches_before, channels = x.shape
x_skip = x
x = self.norm1(x)
x = tf.reshape(x, shape=(-1, height, width, channels))
if self.shift_size > 0:
shifted_x = tf.roll(
x, shift=[-self.shift_size, -self.shift_size], axis=[1, 2]
)
else:
shifted_x = x
x_windows = window_partition(shifted_x, self.window_size)
x_windows = tf.reshape(
x_windows, shape=(-1, self.window_size * self.window_size, channels)
)
attn_windows = self.attn(x_windows, mask=self.attn_mask)
attn_windows = tf.reshape(
attn_windows, shape=(-1, self.window_size, self.window_size, channels)
)
shifted_x = window_reverse(
attn_windows, self.window_size, height, width, channels
)
if self.shift_size > 0:
x = tf.roll(
shifted_x, shift=[self.shift_size, self.shift_size], axis=[1, 2]
)
else:
x = shifted_x
x = tf.reshape(x, shape=(-1, height * width, channels))
x = self.drop_path(x)
x = x_skip + x
x_skip = x
x = self.norm2(x)
x = self.mlp(x)
x = self.drop_path(x)
x = x_skip + x
return x
Model training and evaluation
Extract và embed patches
class PatchExtract(layers.Layer):
def __init__(self, patch_size, **kwargs):
super(PatchExtract, self).__init__(**kwargs)
self.patch_size_x = patch_size[0]
self.patch_size_y = patch_size[0]
def call(self, images):
batch_size = tf.shape(images)[0]
patches = tf.image.extract_patches(
images=images,
sizes=(1, self.patch_size_x, self.patch_size_y, 1),
strides=(1, self.patch_size_x, self.patch_size_y, 1),
rates=(1, 1, 1, 1),
padding="VALID",
)
patch_dim = patches.shape[-1]
patch_num = patches.shape[1]
return tf.reshape(patches, (batch_size, patch_num * patch_num, patch_dim))
class PatchEmbedding(layers.Layer):
def __init__(self, num_patch, embed_dim, **kwargs):
super(PatchEmbedding, self).__init__(**kwargs)
self.num_patch = num_patch
self.proj = layers.Dense(embed_dim)
self.pos_embed = layers.Embedding(input_dim=num_patch, output_dim=embed_dim)
def call(self, patch):
pos = tf.range(start=0, limit=self.num_patch, delta=1)
return self.proj(patch) + self.pos_embed(pos)
class PatchMerging(tf.keras.layers.Layer):
def __init__(self, num_patch, embed_dim):
super(PatchMerging, self).__init__()
self.num_patch = num_patch
self.embed_dim = embed_dim
self.linear_trans = layers.Dense(2 * embed_dim, use_bias=False)
def call(self, x):
height, width = self.num_patch
_, _, C = x.get_shape().as_list()
x = tf.reshape(x, shape=(-1, height, width, C))
x0 = x[:, 0::2, 0::2, :]
x1 = x[:, 1::2, 0::2, :]
x2 = x[:, 0::2, 1::2, :]
x3 = x[:, 1::2, 1::2, :]
x = tf.concat((x0, x1, x2, x3), axis=-1)
x = tf.reshape(x, shape=(-1, (height // 2) * (width // 2), 4 * C))
return self.linear_trans(x)
Build model
input = layers.Input(input_shape)
x = layers.RandomCrop(image_dimension, image_dimension)(input)
x = layers.RandomFlip("horizontal")(x)
x = PatchExtract(patch_size)(x)
x = PatchEmbedding(num_patch_x * num_patch_y, embed_dim)(x)
x = SwinTransformer(
dim=embed_dim,
num_patch=(num_patch_x, num_patch_y),
num_heads=num_heads,
window_size=window_size,
shift_size=0,
num_mlp=num_mlp,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
)(x)
x = SwinTransformer(
dim=embed_dim,
num_patch=(num_patch_x, num_patch_y),
num_heads=num_heads,
window_size=window_size,
shift_size=shift_size,
num_mlp=num_mlp,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
)(x)
x = PatchMerging((num_patch_x, num_patch_y), embed_dim=embed_dim)(x)
x = layers.GlobalAveragePooling1D()(x)
output = layers.Dense(num_classes, activation="softmax")(x)
Training
model = keras.Model(input, output)
model.compile(
loss=keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing),
optimizer=tfa.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
),
metrics=[
keras.metrics.CategoricalAccuracy(name="accuracy"),
keras.metrics.TopKCategoricalAccuracy(5, name="top-5-accuracy"),
],
)
history = model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=num_epochs,
validation_split=validation_split,
)
Thử visualize quá trình training
plt.plot(history.history["loss"], label="train_loss")
plt.plot(history.history["val_loss"], label="val_loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Train and Validation Losses Over Epochs", fontsize=14)
plt.legend()
plt.grid()
plt.show()
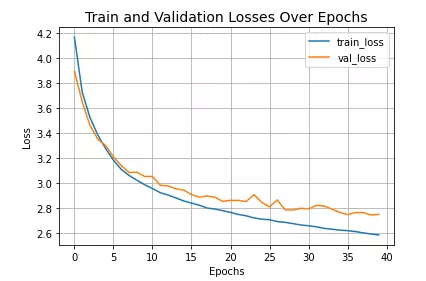
Kết quả
loss, accuracy, top_5_accuracy = model.evaluate(x_test, y_test)
print(f"Test loss: {round(loss, 2)}")
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%")
313/313 [==============================] - 3s 8ms/step - loss: 2.7039 - accuracy: 0.4288 - top-5-accuracy: 0.7366
Test loss: 2.7
Test accuracy: 42.88%
Test top 5 accuracy: 73.66%
Kết quả ở đây khá thấp do chỉ train trên 40 epoch. Bạn đọc có thể tăng số epoch (recommend là 150) để có được performance tốt hơn 
Tài liệu tham khảo
[1] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [2] https://github.com/microsoft/Swin-Transformer [3] https://keras.io/examples/vision/swin_transformers/
All rights reserved
