Paper Reading | ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung
Các mô hình Vision-and-Language pretraining (VLP) tỏ ra hiệu quả trong việc cải thiện các downstream task liên quan đến sự kết hợp thông tin cả ngôn ngữ và hình ảnh. Để đưa vào mô hình VLP, các pixel ảnh cần được embed cùng với các language token. Với bước embed ảnh thì không còn xa lạ rồi, ta có thể sử dụng những mạng CNN phổ biến 
Cho đến nay, hầu hết các nghiên cứu VLP đều tập trung vào việc cải thiện hiệu suất bằng cách cải thiện bước embed hình ảnh. Tuy nhiên bước embed này có những hạn chế trong thế giới thực do sử dụng mô hình thường rất nặng, dẫn đến tốc độ chậm khi thực hiện truy vấn trong thế giới thực. Vì vậy, nhóm tác giả tập chung chuyển hướng nghiên cứu sang việc thiết kế một trình visual embedding nhanh, nhẹ, ngon Những nghiên cứu gần đây chứng minh rằng sử dụng một linear projection đơn giản cho mỗi patch mang lại sự hiệu quả cho việc embed các pixel ảnh trước khi đưa chúng vào mô hình transformer  . Mặc dù thường sử dụng cho văn bản nhưng mô hình transformer gần đây tỏ ra hiệu quả với các dữ liệu hình ảnh. Việc áp dụng transformer cho hình ảnh trong mô hình VLP giúp thay thế cho các mô hình CNN truyền thống.
. Mặc dù thường sử dụng cho văn bản nhưng mô hình transformer gần đây tỏ ra hiệu quả với các dữ liệu hình ảnh. Việc áp dụng transformer cho hình ảnh trong mô hình VLP giúp thay thế cho các mô hình CNN truyền thống.
Trong bài báo, nhóm tác giả đề xuất mô hình Vision-and-Language Transformer (ViLT) xử lý 2 phương thức (vision và language) theo một cách thống nhất. Điểm khác biệt nhất so với các mô hình VLP trước đây là tính "nông" của mô hình được đề xuất, ở đây là ảnh đầu vào sẽ không phải đi qua một mạng CNN riêng biệt Việc loại bỏ bước embedding visual sử dụng mô hình học sâu này giúp giảm đáng kể kích thước và thời gian chạy của mô hình tổng (xem hình dưới)
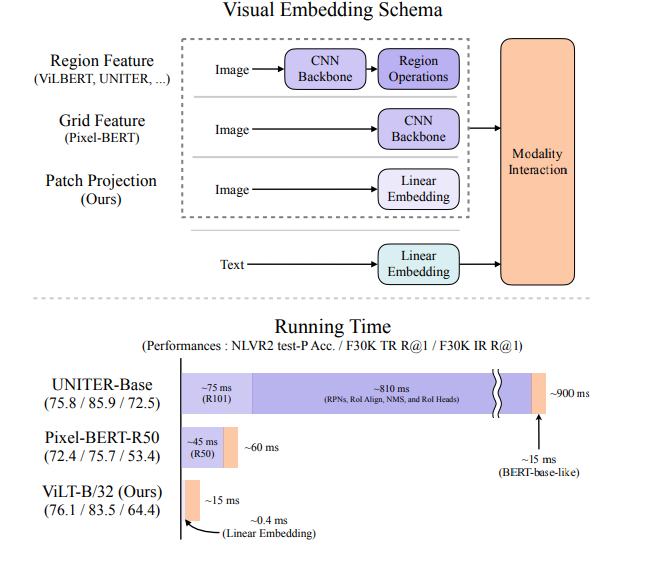
Đây cũng là một trong những ý tưởng hay ho trong bài báo. Cùng tìm hiểu sâu hơn ở các phần dưới nhé
Phương pháp
Phân loại mô hình Vision-and-Language
Nhóm tác giả đề xuất phân loại các mô hình vision-and-language dựa trên 2 thông tin sau:
- So sánh 2 phương thức về mặt tham số và tài nguyên tính toán
- 2 phương thức có tương tác trong một mạng học sâu hay không
Dựa vào 2 thông tin trên ta có 4 trường hợp như hình dưới. Độ cao của hình chữ nhật biểu thị cho tài nguyên tính toán tương đối của module đó.
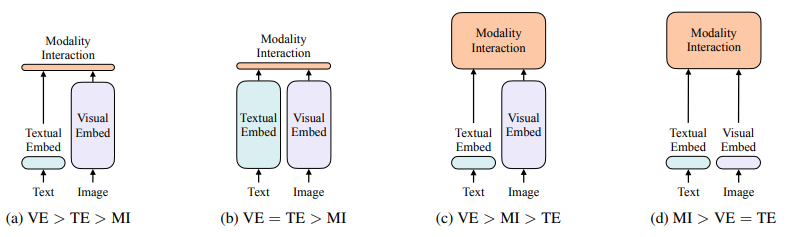
Ta có thấy một số ví dụ cho 4 trường hợp này như sau:
- Với hình (a) ta có model VSE++ và SCAN. 2 model này sử dụng các embedder riêng biệt cho ảnh và văn bản (với ảnh thì nặng hơn ) Sau đó mô hình biểu diễn sự tương đồng giữa các embedded feature từ 2 mô hình với phép nhân vô hướng đơn giản hoặc các lớp shallow attention.
- Với hình (b) ta có model CLIP sử dụng transformer embedder cho 2 phương thức riêng biệt với độ phức tạp tương đồng. Tương tác giữa pooled image vector và text vector vẫn là "nông" (sử dụng tích vô hướng). Tuy nhiên, việc sử dụng các embedder mạnh cho từng phương thức không đảm bảo rằng mô hình sẽ học hiệu quả các task vision-and-language phức tạp. Điển hình như nếu ta fine-tuning MLP head trên NLVR2 thay cho dot product của CLIP thì độ chính xác chỉ khoảng 50.99 vì vậy các biểu diễn không có khả năng học task này. Vì vậy điều này thúc đẩy việc cần xây dựng một cấu trúc tương tác giữa các phương thức chặt chẽ hơn
- Với hình (c), các mô hình VLP gần đây sử dụng một deep transformer để mô hình hóa tương tác các feature ảnh và văn bản. CNN vẫn sử dụng để trích xuất và embed image feature. Điều này làm cho mô hình có kích thước lớn, yêu cầu nhiều hơn và tài nguyên tính toán.
- ViLT chính là mô hình kinh điển đầu tiên cho hình (d). Trong đó lớp embedding nông, nhẹ. Do đó, kiến trúc này tập trung hầu hết các tính toán vào việc mô hình hóa các tương tác giữa các phương thức
Sự tương tác giữa 2 phương thức
Cốt lõi của các mô hình VLP hiện đại là Transformer (đi đâu cũng thấy Transformer nhỉ ). Mô hình nhận đầu vào là các embedding của hình ảnh, văn bản, mô hình hóa giữa các phương thức và tương tác giữa các phương thức qua các lớp, sau đó xuất ra một chuỗi feature được ngữ cảnh hóa. Trong mô hình này, nhóm tác giả sử dụng cách tiếp cận single-stream tức là các layer sẽ thực hiện các thao tác với đầu vào là concat embed của ảnh và văn bản. Cách tiếp cận này đảm bảo không phải bổ sung các tham số như dual-stream.
Visual Embedding
Thay vì sử dụng Region feature và Grid Feature, nhóm tác giả giới thiệu Patch projection cho module trích xuất, cụ thể là linear project cho các image patch. Patch projection không còn xa lạ nếu như bạn đã đọc paper về mô hình ViT. Nhóm tác giả sử dụng một patch projection chỉ yêu cầu 2.4M tham số.
Vision-and-Language Transformer
Tổng quan mô hình
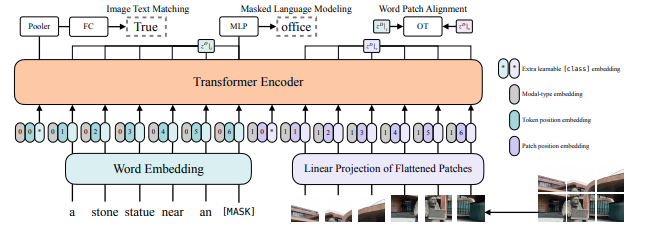
Kiến trúc của ViLT khá đơn giản như trên hình. Một điểm hay là nhóm tác giả khởi tạo trọng số của mô hình tương tác transformer từ pretrained ViT thay vì BERT. Việc khởi tạo này làm "tăng sức mạnh" của interaction layer để xử lý visual feature, điều này bù đắp vào việc ta đã bỏ đi một deep visual embedder riêng biệt. Nhóm tác giả cũng đã thực nghiệm khởi tạo trọng số cho các lớp từ BERT pretrained và sử dụng pretrained patch project từ ViT nhưng cách này không hiệu quả.
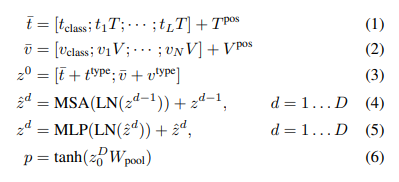
Mô hình hoạt động như sau: Input text được embed thành với 1 ma trận word embedding và 1 ma trận position embedding .
Ảnh đầu vào được cắt thành các patch và flatten thành trong đó là patch resolution và . Tiếp theo là linear projection và position embedding được embed thành .
Text và image embeddings được cộng với modal-type embedding tương ứng vectors , sau đó được concat thành một chuỗi tổng hợp . Contextualized vector được cập nhật thông qua depth transformer layers.
Pre-training Objectives
2 mục tiêu chính và phổ biến khi train mô hình VLP model là Image text matching (ITM) và masked language modeling (MLM)
Image Text Matching
Nhóm tác giả ngẫu nhiên thay ảnh đã căn chỉnh bằng một ảnh khác với xác suất là 0.5. Ngoài ra, kiến trúc bổ sung thêm 1 lớp ITM có nhiệm vụ chiếu pooled output feature qua binary class. Sau đó nhóm tác giả thực hiện tính toán negative log-likelihood loss đại diện cho ITM loss.
Một điểm hay nữa là nhóm tác giả thiết kế word patch alignment (WPA) dùng đế tính toán alignment score giữa 2 tập con (textual subset) và (visual subset) sử dụng inexact proximal point method for optimal transports (IPOT). Phần này mình để nguyên tiếng Anh nha vì dịch ra tiếng Việt có thể không được gần nghĩa. Bạn đọc có thể tìm hiểu cách implement tại đây https://github.com/xieyujia/IPOT
Masked Language Modeling
Mục tiêu chính là dự đoán label của các masked text token từ contextualized vector . Nhóm tác giả che ngẫu nhiên với xác suất là 0.15. MLM loss ở đây là negative log-likelihood loss cho các masked token.
Whole Word Masking
Đây là một kĩ thuật masking (che) mà ta sẽ mask tất cả chữ cái trong một từ. Cách này thể hiện sự hiệu quả trên các downstream task khi ứng dụng BERT.
Ý tưởng của phương pháp này như sau. Ví dụ, cho từ "giraffe" đã được token hóa thành 3 thành phần sau ["gi", "##raf", "##fe"], cách token hóa này sử dụng bert-base-uncased tokenizer. Nếu như không phải toàn bộ token được gán nhãn, ví dụ như , ["gi",
"[MASK]", "##fe"], mô hinh sẽ chỉ phụ thuộc vào các token lân cận ["gi", "##fe"] để dự đoán ra từ bị mask là "##raf" mà không phải dựa vào thông tin từ ảnh.
Image Augmentation
Nhóm tác giả sử dụng RandAugment trong quá trình fine-tuning. Tuy nhiên có 2 phương pháp augment sau bị loại bỏ là color inversion bởi vì văn bản đầu vào có thể có thông tin về màu tại phần nào đó trong ảnh. Tiếp đó, cutout cũng được loại bỏ do việc này có thể làm mất một số object quan trọng có kích thước nhỏ trong ảnh.
Kết luận
Trong bài báo, nhóm tác giả đã đóng góp kiến trúc VLP ViLT hỗ trợ giải quyết các bài toán về Visual - Language một cách hiệu quả. Bên cạnh đó là một số kĩ thuật được áp dụng như Augmentation, Masking làm tăng hiệu suất của mô hình. Đây là một mô hình bạn có thể thử trong một số bài toán như Image Caption hoặc Visual Question Answering.
Tài liệu tham khảo
[1] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
All rights reserved
