Paper reading | Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Bài đăng này đã không được cập nhật trong 2 năm
Đặt vấn đề
Self-supervised learning là một phương pháp học máy mà trong đó mô hình được huấn luyện từ dữ liệu mà không yêu cầu nhãn rõ ràng từ con người. Thay vào đó, các nhãn "giả" được tạo ra từ dữ liệu đầu vào. Trong lĩnh vực computer vision, self-supervised learning đã thu hút sự chú ý lớn vì nó giúp giải quyết vấn đề khan hiếm dữ liệu gán nhãn, mở rộng khả năng ứng dụng của học máy trong các nhiệm vụ phức tạp.
Trong computer vision có 2 cách tiếp cận phổ biến của self-supervised learning từ hình ảnh là phương pháp invariance-based và phương pháp generative.
Trong phương pháp Invariance-based pretraining, một bộ encoder được tối ưu hóa để tạo ra các biểu diễn tương tự cho hai hoặc nhiều phiên bản của cùng một hình ảnh. Các phiên bản này thường được tạo ra bằng cách áp dụng các kĩ thuật augmentation, chẳng hạn như random scaling, cropping, thay đổi màu sắc và các biến đổi khác. Tuy nhiên, phương pháp này tạo ra các strong bias và khó tổng quát hóa cho các nhiệm vụ khác nhau hoặc dữ liệu từ nhiều nguồn. Điều này đặt ra thách thức trong việc sử dụng các biểu diễn này cho các nhiệm vụ với mức độ trừu tượng và kiểu dữ liệu khác nhau.
Khác với Invariance-based pretraining, phương pháp self-supervised generative thực hiện xóa hoặc làm nhiễu một số phần của dữ liệu đầu vào và mô hình sẽ học cách dự đoán nội dung đã bị xóa đó. Cụ thể, các phương pháp mask-denoising học biểu diễn bằng cách tái tạo các phần của dữ liệu đầu vào bị che khuất một cách ngẫu nhiên, ở mức pixel hoặc mức token (đại diện cho một phần nhỏ hơn của dữ liệu). Cách tiếp cận này có một số nhược điểm được liệt kê trong bài báo như sau:
- Lower Semantic Level Representations: Các biểu diễn kết quả thường có mức độ ngữ nghĩa thấp hơn. Điều này có nghĩa là mô hình học các đặc trưng cơ bản của dữ liệu như cạnh, màu sắc, hình dạng cơ bản, nhưng không học được các đặc trưng phức tạp và ngữ nghĩa cao hơn như đối tượng hoặc khái niệm lớn hơn.
- Performance Gap in Downstream Tasks: Các biểu diễn thu được không hiệu quả bằng các phương pháp pretraining khác như invariance-based pretraining. Điều này gây ra khoảng cách về hiệu suất trong các downstream task.
- Complex Adaptation Mechanism Required: Để tận dụng toàn bộ lợi ích của phương pháp này, cần áp dụng cơ chế thích ứng phức tạp hơn. Điều này đòi hỏi quá trình finetuning mô hình sau pretraining phức tạp và tốn kém về mặt tính toán và thời gian.
Đóng góp của bài báo
Từ những vấn đề trên, nhóm tác giả nghiên cứu cách cải thiện mức độ ngữ nghĩa của các biểu diễn self-supervised mà không sử dụng prior knowledge. Bài báo giới thiệu kiến trúc joint-embedding predictive cho hình ảnh có tên viết tắt là I-JEPA (Image, joint-embedding predictive architecture)
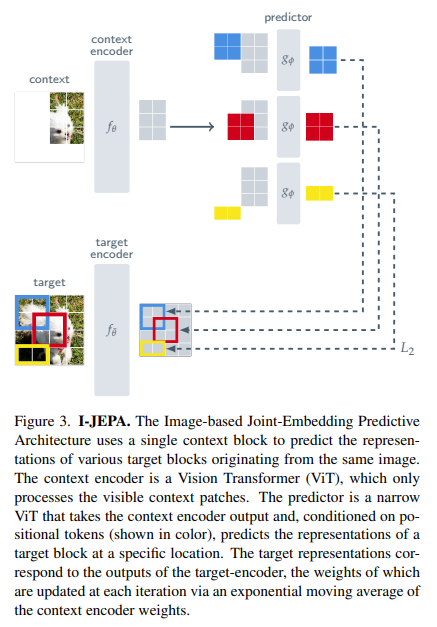
Ý tưởng đằng sau I-JEPA là dự đoán thông tin bị mất trong một không gian biểu diễn trừu tượng (abstract representation space). Cụ thể cho một context block, thực hiện dự đoán biểu diễn của nhiều target block khác nhau trong cùng một ảnh, trong đó những biểu diễn target được tính bằng cách sử dụng một mô hình target-encoder.
Một số kiến thức nền tảng
Ta cùng đi qua một số concept chính trước khi đi vào phương pháp được đề xuất trong bài báo 
Self-supervised learning là quá trình học máy trong đó mô hình tự huấn luyện bản thân học một phần của dữ liệu đầu vào từ một hoặc nhiều phần khác của dữ liệu đầu vào. Điều này có nghĩa là mô hình tạo ra các nhiệm vụ phụ để dự đoán hoặc điền vào một phần của dữ liệu dựa trên các phần còn lại. Phương pháp Self-supervised learning cho thấy khả năng tạo ra các biểu diễn có ý nghĩa và có khả năng tổng quát hóa tốt cho các nhiệm vụ học máy khác nhau.
Ví dụ, trong trường hợp dữ liệu là hình ảnh, mô hình có thể học từ việc dự đoán một phần hình ảnh bị che khuất dựa trên phần hình ảnh còn lại. Mô hình sẽ cố gắng học các đặc trưng quan trọng để dự đoán hoặc tái tạo các phần bị che khuất.
Có nhiều cách tiếp cận cho supervised learning được mô tả trong hình dưới:

Kiến trúc Joint-Embedding (viết tắt là JEA, được mô tả trong hình a), học cách tạo ra các biểu diễn tương tự cho các đầu vào tương thích , và các biểu diễn khác nhau cho các đầu vào không tương thích. Điều này đảm bảo rằng các đối tượng hoặc thông tin tương tự sẽ có các biểu diễn gần nhau trong không gian embedding, trong khi các đối tượng hoặc thông tin không tương thích sẽ có các biểu diễn xa nhau.
Kiến trúc Generative (được mô tả trong hình b) học cách tái tạo trực tiếp một tín hiệu từ một tín hiệu tương thích , sử dụng một mạng decoder được điều kiện hóa bởi các biến số bổ sung (có thể là ẩn) để tạo điều kiện cho quá trình tái tạo. Các kiến trúc generative thường được sử dụng trong các ứng dụng như sinh ảnh, tạo âm nhạc, xử lý ngôn ngữ tự nhiên và nhiều ứng dụng sáng tạo khác, nơi mục tiêu là tạo ra dữ liệu mới từ dữ liệu có sẵn. Trong ngữ cảnh pretrain các mô hình hình ảnh thì là bản sao của ảnh nhưng sẽ có một số patch bị che (mask). Biến số điều kiện tương ứng với một tập hợp các biểu diễn mask và vị trí (learnable), đó là thông tin chỉ định cho mạng decoder biết những patch nào trong hình ảnh cần tái tạo lại Hiện tượng sụp đổ biểu diễn (representation collapse) không còn là mối quan ngại trong các kiến trúc này, miễn là khả năng thông tin của ít hơn so với tín hiệu . Tức là, nếu chứa ít thông tin so với dữ liệu , thì biểu diễn sẽ được học và giữ nguyên độ phức tạp, đa dạng của tín hiệu . Trong bối cảnh này, việc sử dụng masking cho phép mô hình học biểu diễn của dữ liệu và giúp nâng cao khả năng tổng quát hóa cho các nhiệm vụ học máy sau này.
Kiến trúc Joint-Embedding Predictive (viết tắt là JEPA, được mô tả trong hình c), học cách dự đoán biểu diễn (hay embedding) của tín hiệu từ tín hiệu tương thích , sử dụng một mô hình được điều kiện hóa bởi các biến số bổ sung để hỗ trợ dự đoán. Trái với phương pháp Generative ở không gian pixel, JEPA sử dụng các mục tiêu dự đoán trừu tượng, cho phép mô hình ưu tiên các đặc trưng ngữ nghĩa hơn là chi tiết không cần thiết ở mức pixel. Phương pháp này khuyến khích việc học các biểu diễn có ý nghĩa và mức high-level .
Phương pháp
Tổng quan phương pháp được mô tả trong hình trên. Cụ thể, cho một context block, mục tiêu của mô hình là dự đoán biểu diễn của các target block trong cùng một ảnh. Nhóm tác giả sử dụng mô hình Vision Transformer cho các thành phần context-encoder, target-encoder và predictor.
Target trong I-JEPA là biểu diễn của các image block. Cụ thể các bước mô hình thực hiện lấy mẫu target như sau:
- Cho một ảnh đầu vào , ta thực hiện biến đổi ảnh thành một chuỗi gồm patch không chồng nhau.
- Đưa chuỗi các patch trên vào một mạng target-encoder để có các biểu diễn patch-level tương ứng là với trong đó tương ứng với patch thứ .
- Tiếp theo, ta thực hiện lấy mẫu ngẫu nhiên block từ biểu diễn target . thường có giá trị bằng 4. Các block này có thể chồng chéo nhau (xem hình dưới).

Một điểm chú ý rằng, ta lấy mẫu các target block bằng cách masking output của target-encoder chứ không phải input
Mục tiêu ban đầu của mô hình là dự đoán biểu diễn của target block từ một context block.

Xác định context block trong I-JEPA như sau:
- Bước 1, ta lấy mẫu một block từ ảnh với tỷ lệ ngẫu nhiên trong phạm vi và block này có tỷ lệ giữa chiều rộng và chiều cao là 1 (gọi là unit aspect ratio). Vì các target block được lấy mẫu độc lập với các context block nên chúng có thể trùng nhau kha khá Do đó, để đảm bảo nhiệm vụ dự đoán có tính thách thức một chút , các vùng chồng nhau giữa các target block và context block sẽ được loại bỏ khỏi context block.
- Bước 2, context block sau khi được xử lý ở bước trước sẽ được đưa vào context encoder để nhận biểu diễn patch-level tương ứng.
Cuối cùng, output của context encoder ở trên được dùng để dự đoán các biểu diễn của target block. Để đạt được điều này, ta sẽ sử dụng predictor với đầu vào là output của context encoder và mask token cho mỗi patch mà muốn dự đoán.
Loss của kiến trúc này là trung bình khoảng cách giữa các biểu diễn predicted patch-level và các biểu diễn target patch-level :
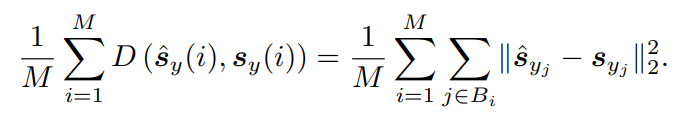
Một điểm chú ý là các tham số của predictor và của context encoder được học thông qua tối ưu gradient-based. Trong khi đó tham số của target encoder được cập nhật thông qua exponential moving average (đường trung bình hàm mũ) của các tham số context encoder.
Thực nghiệm
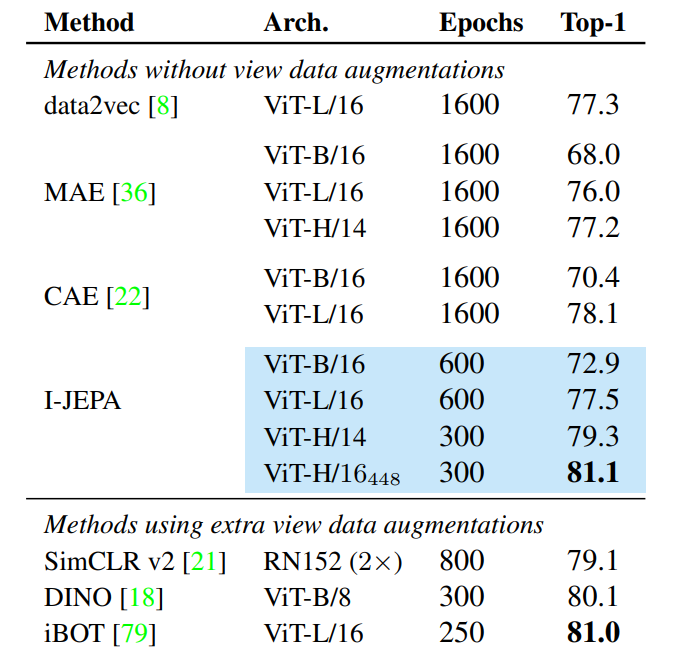
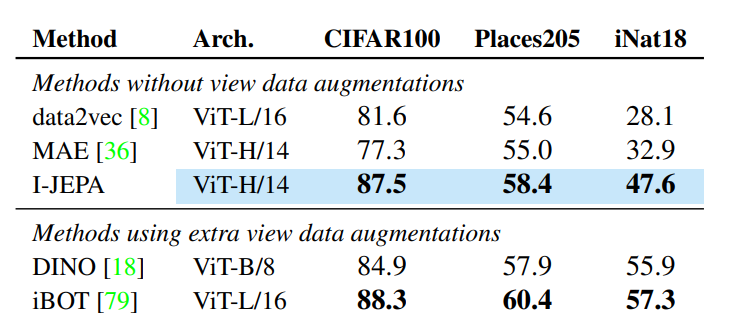
Bảng dưới mô tả kết quả của phương pháp I-JEPA trong việc đánh giá tuyến tính trên tập dữ liệu ImageNet-1k. I-JEPA cải thiện hiệu suất so với các phương pháp khác mà không yêu cầu sử dụng các kỹ thuật data augmentation trong quá trình pretraining. Ngoài ra, I-JEPA đã thể hiện khả năng scale tốt, với các mô hình I-JEPA lớn đạt đến hiệu suất của các phương pháp view-invariance mà không cần yêu cầu thực hiện view data augmentation.
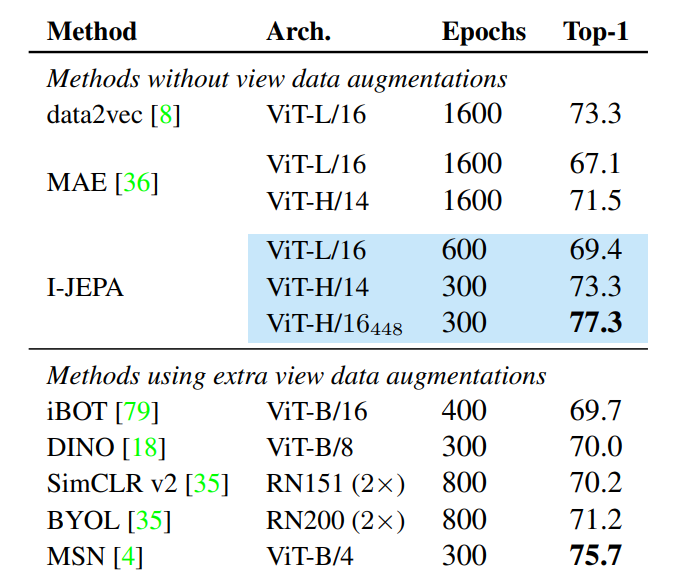
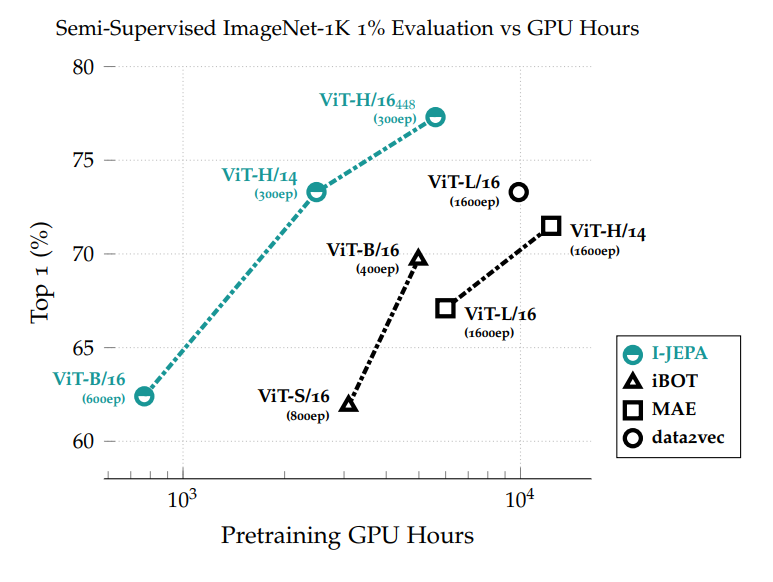
Bảng dưới mô tả kết quả khi thực hiện đánh giá Semi-supervised trên tập ImageNet-1K chỉ sử dụng 1% dữ liệu có gán nhãn.
Kết quả khi đánh giá trên task image classification.
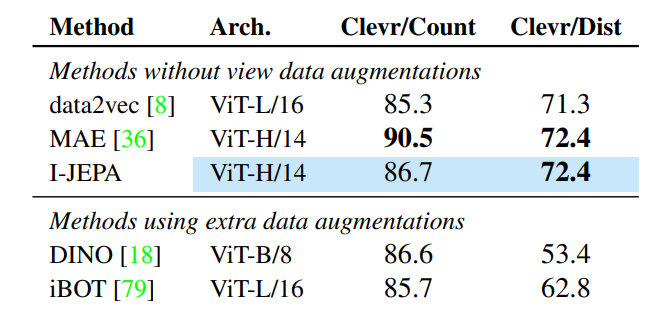
Kết quả đánh giá trên các task khác như object counting, depth prediction.
I-JEPA cho kết quả tốt khi tăng độ đa đạng và số lượng mẫu dữ liệu.

I-JEPA sử dụng ít tài nguyên tính toán hơn các phương pháp trước đó đáng kể.
Tài liệu tham khảo
[1] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
[2] https://github.com/facebookresearch/ijepa
[3] https://leimao.github.io/blog/Exponential-Moving-Average/
All rights reserved
