Xây dựng ứng dụng event-driven với Apache Kafka và Quarkus theo hướng hiện đại
Trong bối cảnh hệ thống phần mềm ngày càng chuyển dịch sang kiến trúc microservices và xử lý dữ liệu theo thời gian thực, việc lựa chọn công nghệ không còn dừng lại ở “chạy được” mà phải đáp ứng đồng thời nhiều tiêu chí: Hiệu năng, khả năng mở rộng, độ linh hoạt và tối ưu tài nguyên.
Sự kết hợp giữa Apache Kafka và Quarkus chính là một trong những hướng tiếp cận tiêu biểu cho bài toán này, đặc biệt khi doanh nghiệp cần xây dựng các pipeline dữ liệu real-time hoặc hệ thống event-driven quy mô lớn.
Từ xử lý batch đến streaming: Kafka thay đổi cách hệ thống vận hành
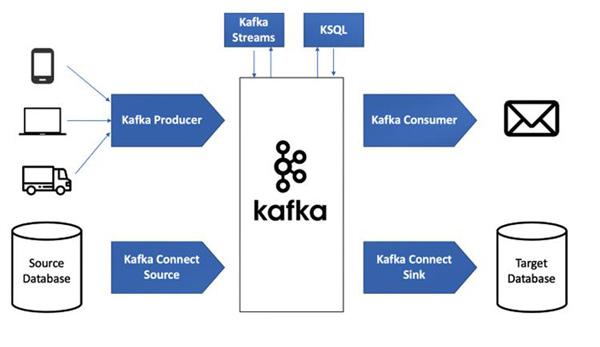 Nếu như trước đây, dữ liệu thường được lưu trữ trong database rồi xử lý theo từng đợt (batch processing), thì ngày nay mô hình đó dần bộc lộ hạn chế về độ trễ và khả năng phản ứng theo thời gian thực.
Nếu như trước đây, dữ liệu thường được lưu trữ trong database rồi xử lý theo từng đợt (batch processing), thì ngày nay mô hình đó dần bộc lộ hạn chế về độ trễ và khả năng phản ứng theo thời gian thực.
Apache Kafka xuất hiện như một lớp hạ tầng trung gian giúp “dòng chảy dữ liệu” trở nên liên tục. Mỗi sự kiện phát sinh trong hệ thống – từ hành vi người dùng, giao dịch, log hệ thống – đều được ghi nhận và phân phối gần như ngay lập tức đến các service liên quan.
Điểm đáng chú ý là Kafka không chỉ đóng vai trò truyền dữ liệu, mà còn lưu trữ dữ liệu theo dạng log phân tán. Điều này cho phép các service có thể đọc lại (replay) dữ liệu bất kỳ thời điểm nào, mở ra khả năng xây dựng các hệ thống phân tích hoặc xử lý lại dữ liệu một cách linh hoạt.
Chính vì vậy, Kafka ngày càng được xem như “trục xương sống dữ liệu” trong kiến trúc hiện đại, thay thế dần các hệ thống messaging truyền thống như JMS hay AMQP trong nhiều use case phức tạp.
Quarkus – Tối ưu Java cho môi trường cloud-native
Trong khi Kafka giải quyết bài toán dữ liệu, thì Quarkus lại tập trung vào lớp xử lý, nơi các business logic được thực thi.
Quarkus được thiết kế lại từ nền tảng để phù hợp với môi trường cloud-native, nơi mà container, Kubernetes và serverless là tiêu chuẩn. Thay vì giữ cách vận hành nặng nề của Java truyền thống, Quarkus tối ưu mạnh ở build-time, giúp ứng dụng có thể khởi động gần như tức thì và tiêu tốn ít tài nguyên hơn.
Điều này đặc biệt quan trọng trong các hệ thống microservices, nơi mỗi service cần nhẹ, linh hoạt và có thể scale nhanh. Khi kết hợp với Kafka, Quarkus cho phép xử lý event theo mô hình reactive tức là không chặn luồng (non-blocking), từ đó tận dụng tài nguyên hiệu quả hơn.

Khi Kafka và Quarkus kết hợp
Thay vì xây dựng hệ thống theo kiểu request–response truyền thống, Kafka và Quarkus mở ra một cách tiếp cận khác: mọi thứ được vận hành dựa trên event.
Một service không cần biết service khác đang hoạt động ra sao, chỉ cần phát sinh sự kiện và đẩy vào Kafka. Các service khác, nếu quan tâm, sẽ tự động lắng nghe và xử lý. Điều này giúp hệ thống giảm phụ thuộc lẫn nhau, dễ mở rộng và dễ thay đổi hơn.
Trong Quarkus, cơ chế này được đơn giản hóa thông qua Reactive Messaging. Thay vì phải thao tác trực tiếp với Kafka client phức tạp, lập trình viên chỉ cần định nghĩa các “channel” để gửi và nhận dữ liệu.
Một phía sẽ đóng vai trò producer – nơi phát sinh event. Phía còn lại là consumer – nơi tiếp nhận và xử lý dữ liệu. Tất cả được kết nối với Kafka thông qua cấu hình, giúp code trở nên gọn gàng và dễ kiểm soát hơn.
Triển khai thực tế: Từ model đến luồng xử lý
Khi bắt đầu triển khai, việc đầu tiên thường là xác định cấu trúc dữ liệu sẽ được truyền qua Kafka. Mỗi message thực chất là một record gồm key và value, vì vậy việc thiết kế model đóng vai trò quan trọng trong việc đảm bảo tính nhất quán giữa các service.
Sau đó, phía producer sẽ chịu trách nhiệm tạo ra các event và gửi chúng vào Kafka. Trong Quarkus, quá trình này diễn ra khá tự nhiên thông qua cơ chế emitter – nơi dữ liệu được đẩy vào một channel đã được ánh xạ sẵn với Kafka topic.
Ở chiều ngược lại, consumer sẽ lắng nghe các event này. Khi có dữ liệu mới, Quarkus tự động kích hoạt logic xử lý tương ứng. Nhờ mô hình reactive, quá trình này diễn ra bất đồng bộ, không làm tắc nghẽn hệ thống ngay cả khi lưu lượng dữ liệu tăng cao.
Một điểm quan trọng khác là lớp cấu hình. Toàn bộ việc kết nối tới Kafka, định nghĩa topic, cũng như cách serialize/deserialize dữ liệu đều được khai báo trong file cấu hình. Điều này giúp tách biệt rõ ràng giữa logic nghiệp vụ và hạ tầng.
Từ môi trường local đến production
Trong giai đoạn phát triển, Kafka thường được chạy bằng Docker để dễ dàng thử nghiệm. Tuy nhiên, khi hệ thống đi vào production, việc vận hành Kafka cluster không còn đơn giản.
Các vấn đề như phân bổ partition, đảm bảo replication, theo dõi trạng thái cluster hay xử lý lỗi đều đòi hỏi kinh nghiệm và nguồn lực đáng kể. Nếu không được thiết kế tốt, Kafka có thể trở thành điểm nghẽn thay vì nền tảng hỗ trợ.
Vì vậy, nhiều doanh nghiệp lựa chọn sử dụng Kafka dưới dạng managed service để giảm tải phần vận hành, tập trung vào phát triển ứng dụng. Điều này đặc biệt phù hợp với các hệ thống Quarkus triển khai trên Kubernetes, nơi khả năng scale và tính ổn định là yếu tố sống còn.
Kết luận
Sự kết hợp giữa Apache Kafka và Quarkus không chỉ giúp xây dựng một hệ thống xử lý dữ liệu nhanh hơn, mà còn thay đổi cách kiến trúc hệ thống được thiết kế.
Kafka đóng vai trò trung tâm trong việc quản lý và phân phối dữ liệu, trong khi Quarkus đảm nhiệm việc xử lý với hiệu suất cao và tối ưu cho môi trường cloud. Khi hai công nghệ này được tích hợp đúng cách, doanh nghiệp có thể xây dựng những hệ thống linh hoạt, dễ mở rộng và sẵn sàng đáp ứng các yêu cầu dữ liệu thời gian thực ngày càng phức tạp.
Tham khảo: https://bizflycloud.vn/tin-tuc/su-dung-apache-kafka-voi-quarkus-20230201161300059.htm
All rights reserved
