Paper reading | Scene Text Recognition with Permuted Autoregressive Sequence Models
Đóng góp của bài báo
Bài toán Scene Text Recognition (STR) luôn nhận được sự quan tâm nhờ tính ứng dụng thực tiễn cao. Không như nhận diện văn bản trên các trang tài liệu do kí tự thường được theo một font, kích thước đồng bộ, đối với scene text thì phức tạp hơn nhiều do văn bản được thể hiện ở nhiều style, hướng, hình dạng, kích thước,... khác nhau.
Về cơ bản, STR là một bài toán computer vision, tuy nhiên nếu trong trường hợp văn bản bị khó đọc (do bị mờ, bị che,...) thì việc sử dụng một model trích xuất feature ảnh là không đủ để predict ra kết quả chính xác. Vì vậy, việc kết hợp thêm thành phần mô hình ngữ nghĩa văn bản sẽ là hợp lý trong trường hợp này. Việc sử dụng thêm một mô hình ngôn ngữ văn bản sẽ giúp ta thêm thông tin để dự đoán hình ảnh văn bản bị khó đọc.
Các phương pháp STR trước đây bên cạnh trích xuất feature từ ảnh còn kết hợp các mô hình văn bản như sử dụng thông tin từ các mô hình biểu diễn từ, sử dụng từ điển hoặc mô hình sequence. Một mô hình SOTA điển hình sử dụng cách tiếp cận này là ABINet. ABINet kết hợp mô hình context-free vision và mô hình context-aware language. Vai trò của language model giống như một trình kiểm tra chính tả (spell checker), tuy nhiên vấn đề ở đây là mặc dù mô hình trích xuất feature hình ảnh cho kết quả đúng nhưng language model vẫn có xu hướng "sửa" thành một kết quả sai.

Mặt khác, các mô hình ngôn ngữ sử dụng trong các phương pháp STR trước đây chủ yếu là một chiều, tức là xác suất xuất hiện một từ tiếp theo chỉ dựa vào các từ đã xuất hiện trước đó (thường theo chiều từ trái sang phải). Điều này làm cho model bị thiên lệch về một hướng đọc dẫn đến đưa ra các dự đoán sai.
Để giải quyết những hạn chế trên, nhóm tác giả đề xuất mô hình Permuted autoregressive sequence (PARSeq) được train với Permutation Language Modeling (PLM) có khả năng inference cả context-free và context-aware cũng như thực hiện lặp lại việc căn chỉnh (iterative refinement) sử dụng bidirectional (cloze) context. PARSeq đạt kết quả SOTA trên cả bộ dữ liệu synthetic và các benchmark khác, đồng thời cũng tối ưu lượng tham số, FLOPs và runtime.
Phương pháp
Kiến trúc mô hình
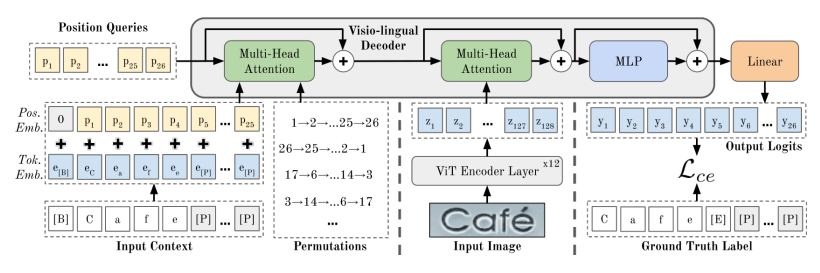
PARSeq là một mô hình có kiến trúc encoder-decoder (xem hình trên). Encoder có 12 layer trong khi decoder chỉ có 1 layer. Cách thiết kế mô hình dạng deep-shallow (sâu - nông  ) này có mục tiêu là tối ưu tài nguyên tính toán sử dụng mà không làm ảnh hưởng đến hiệu suất chung của mô hình.
) này có mục tiêu là tối ưu tài nguyên tính toán sử dụng mà không làm ảnh hưởng đến hiệu suất chung của mô hình.
Multi-head Attention (MHA) được sử dụng trong kiến trúc mô hình PARSeq, kí hiệu là , trong đó lần lượt là các parameter query, key, value và attention mask. Tiếp theo, ta sẽ tìm hiểu 2 thành phần encoder và decoder trong mô hình PARSeq.
Encoder được sử dụng là mô hình Vision Transformer (ViT). Một layer ViT bao gồm một module MHA được sử dụng cho self attention, tức là . Encoder bao gồm 12 layer ViT và không có classification head cũng như token [CLS]. Ban đầu, một ảnh đầu vào , có chiều rộng , chiều cao , và số channel , được chia thành patch. Sau đó mỗi patch được biến đổi tuyến tính thành một vector có chiều bằng ma trận biến đổi , kết quả là ta có token. Embedding vị trí cũng được cộng vào các token trước đó và đưa vào layer ViT đầu tiên. Sau đó, tất cả output token được sử dụng làm đầu vào của decoder.
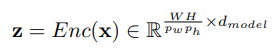
Visio-lingual Decoder. Phần decoder được xây dựng dựa trên kiến trúc giống với kiến trúc của decoder trong mô hình Transformer trước khi áp dụng Layer Normalization (pre-LayerNorm). Layer Normalization là một kỹ thuật chuẩn hóa đầu ra của mỗi lớp trong mạng để cải thiện hiệu suất và dễ dàng đào tạo. Tuy nhiên, điểm khác biệt quan trọng ở đây là phần decoder sử dụng gấp đôi số lượng attention heads so với mô hình Transformer tiêu chuẩn .
Cụ thể, với module MHA đầu tiên được sử dụng làm context–position attention, ta công thức hóa như sau:
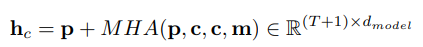
trong đó là độ dài context, là các position token, là các context embedding với thông tin về vị trí (positional information) và là attention mask. Ngoài ra, ta cũng sử dụng thêm 1 trong 2 token đặc biệt là [B] và [E], đây là các token có nhiệm vụ phân cách và việc sử dụng thêm các token này làm độ dài chuỗi tăng lên .
Module MHA thứ 2 được sử dụng làm image-position attention, cụ thể:
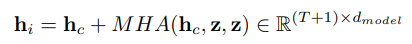
trong công thức trên ta không sử dụng attention mask.
Decoder hidden state cuối cùng là đầu ra của MLP, .
Logit cuối cùng là Linear trong đó là kích thước của tập kí tự (charset) được sử dụng cho training. Tổng quan, cho một attention mask , decoder là một hàm có công thức như sau:
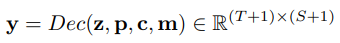
Permutation Language Modeling
Permutation Language Modeling là điểm mới trong mô hình PARSeq. Mục tiêu của mô hình là tối ưu hóa xác suất xuất hiện của một chuỗi văn bản , biểu diễn bằng các từ , dựa trên hình ảnh theo một tập hợp các tham số mô hình . Trong mô hình Autoregressive (AR) tiêu chuẩn, xác suất xuất hiện của chuỗi được tính bằng cách áp dụng chain rule theo thứ tự chuỗi cơ bản . Khi đó ta có xác suất .
Tuy nhiên, vấn đề ở đây là mô hình Transformer xử lý tất cả các token một cách song song, điều này làm các output token truy cập hoặc phụ thuộc vào tất cả các input token. Để có một mô hình AR hợp lệ, các token trong quá khứ không thể truy cập thông tin từ các token trong tương lai. Thuộc tính AR được thực hiện trong các mô hình Transformer bằng cách sử dụng các attention masks. Attention masks này đảm bảo rằng các token trong quá khứ chỉ có thể xem xét thông tin từ các token trong quá khứ và không thể xem xét thông tin từ các token trong tương lai.
Ví dụ trong một chuỗi có 3 kí tự trong bảng dưới. Ở đây ta có 4 permutation và ứng với mỗi permutation ta sẽ có các cách mask khác nhau. 0 nghĩa là mask, không bị leak thông tin từ input tới output.

Ý tưởng cơ bản đằng sau PLM là train trên permutation:
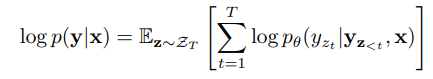
trong đó là tập các permutation, và lần lượt là phần tử thứ và phần tử đầu tiên tương ứng trong một permutation .
Thực tế là ta không train toàn bộ do yêu cầu về tài nguyên tính toán tăng theo cấp số nhân. Vì vậy, ta chỉ sử dụng trên permutation.
Cuối cùng, loss ta sử dụng là cross-entropy loss cho permutation như sau:
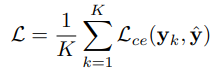
trong đó .
Decoding Schemes
Trong bài báo, nhóm tác giả chỉ sử dụng 2 decoding scheme là Autoregressive (AR) và Non-autoregressive (NAR) cũng như iterative refinement.
Autoregressive (AR) tạo ra một token mới trong mỗi lần lặp. Có nghĩa là mô hình dự đoán từng token một theo thứ tự từ trái qua phải. Đối với mọi lần lặp kế tiếp , các token truy vấn vị trí được sử dụng, các context được gán thành output của quá trình trước đó.

Non-autoregressive (NAR) tạo ra tất cả các output token trong cùng 1 thời điểm. Tất cả truy vấn được sử dụng mà không dùng attention mask. Context ở đây luôn luôn là [B]
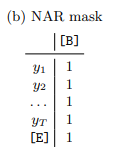
Iterative refinement được thực hiện bất kể ta sử dụng phương decoding ban đầu nào (AR hoặc NAR). Đầu ra trước đó (loại bỏ [E]) được sử dụng làm context cho vòng lặp hiện tại, tương tự như phương pháp decoding AR. Điều này đảm bảo rằng thông tin từ đầu ra trước đó đóng vai trò quan trọng trong việc dự đoán đầu ra tiếp theo trong quá trình tinh chỉnh. Tuy nhiên, trong quá trình iterative refinement, tất cả các token truy vấn vị trí luôn được sử dụng. Cloze attention mask được sử dụng trong quá trình iterative refinement. Cloze attention mask được tạo ra bằng cách bắt đầu với một ma trận toàn bộ là một, sau đó loại bỏ các vị trí khớp với các token.

Coding
Các modules
import math
from typing import Optional
import torch
from torch import nn as nn, Tensor
from torch.nn import functional as F
from torch.nn.modules import transformer
from timm.models.vision_transformer import VisionTransformer, PatchEmbed
class DecoderLayer(nn.Module):
"""A Transformer decoder layer supporting two-stream attention (XLNet)
This implements a pre-LN decoder, as opposed to the post-LN default in PyTorch."""
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation='gelu',
layer_norm_eps=1e-5):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
self.cross_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm_q = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm_c = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = transformer._get_activation_fn(activation)
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.gelu
super().__setstate__(state)
def forward_stream(self, tgt: Tensor, tgt_norm: Tensor, tgt_kv: Tensor, memory: Tensor, tgt_mask: Optional[Tensor],
tgt_key_padding_mask: Optional[Tensor]):
"""Forward pass for a single stream (i.e. content or query)
tgt_norm is just a LayerNorm'd tgt. Added as a separate parameter for efficiency.
Both tgt_kv and memory are expected to be LayerNorm'd too.
memory is LayerNorm'd by ViT.
"""
tgt2, sa_weights = self.self_attn(tgt_norm, tgt_kv, tgt_kv, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)
tgt = tgt + self.dropout1(tgt2)
tgt2, ca_weights = self.cross_attn(self.norm1(tgt), memory, memory)
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(self.norm2(tgt)))))
tgt = tgt + self.dropout3(tgt2)
return tgt, sa_weights, ca_weights
def forward(self, query, content, memory, query_mask: Optional[Tensor] = None, content_mask: Optional[Tensor] = None,
content_key_padding_mask: Optional[Tensor] = None, update_content: bool = True):
query_norm = self.norm_q(query)
content_norm = self.norm_c(content)
query = self.forward_stream(query, query_norm, content_norm, memory, query_mask, content_key_padding_mask)[0]
if update_content:
content = self.forward_stream(content, content_norm, content_norm, memory, content_mask,
content_key_padding_mask)[0]
return query, content
class Decoder(nn.Module):
__constants__ = ['norm']
def __init__(self, decoder_layer, num_layers, norm):
super().__init__()
self.layers = transformer._get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, query, content, memory, query_mask: Optional[Tensor] = None, content_mask: Optional[Tensor] = None,
content_key_padding_mask: Optional[Tensor] = None):
for i, mod in enumerate(self.layers):
last = i == len(self.layers) - 1
query, content = mod(query, content, memory, query_mask, content_mask, content_key_padding_mask,
update_content=not last)
query = self.norm(query)
return query
class Encoder(VisionTransformer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.,
qkv_bias=True, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., embed_layer=PatchEmbed):
super().__init__(img_size, patch_size, in_chans, embed_dim=embed_dim, depth=depth, num_heads=num_heads,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop_rate=drop_rate, attn_drop_rate=attn_drop_rate,
drop_path_rate=drop_path_rate, embed_layer=embed_layer,
num_classes=0, global_pool='', class_token=False) # these disable the classifier head
def forward(self, x):
# Return all tokens
return self.forward_features(x)
class TokenEmbedding(nn.Module):
def __init__(self, charset_size: int, embed_dim: int):
super().__init__()
self.embedding = nn.Embedding(charset_size, embed_dim)
self.embed_dim = embed_dim
def forward(self, tokens: torch.Tensor):
return math.sqrt(self.embed_dim) * self.embedding(tokens)
Model chính:
import math
from functools import partial
from itertools import permutations
from typing import Sequence, Any, Optional
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from pytorch_lightning.utilities.types import STEP_OUTPUT
from timm.models.helpers import named_apply
from strhub.models.base import CrossEntropySystem
from strhub.models.utils import init_weights
from .modules import DecoderLayer, Decoder, Encoder, TokenEmbedding
class PARSeq(CrossEntropySystem):
def __init__(self, charset_train: str, charset_test: str, max_label_length: int,
batch_size: int, lr: float, warmup_pct: float, weight_decay: float,
img_size: Sequence[int], patch_size: Sequence[int], embed_dim: int,
enc_num_heads: int, enc_mlp_ratio: int, enc_depth: int,
dec_num_heads: int, dec_mlp_ratio: int, dec_depth: int,
perm_num: int, perm_forward: bool, perm_mirrored: bool,
decode_ar: bool, refine_iters: int, dropout: float, **kwargs: Any) -> None:
super().__init__(charset_train, charset_test, batch_size, lr, warmup_pct, weight_decay)
self.save_hyperparameters()
self.max_label_length = max_label_length
self.decode_ar = decode_ar
self.refine_iters = refine_iters
self.encoder = Encoder(img_size, patch_size, embed_dim=embed_dim, depth=enc_depth, num_heads=enc_num_heads,
mlp_ratio=enc_mlp_ratio)
decoder_layer = DecoderLayer(embed_dim, dec_num_heads, embed_dim * dec_mlp_ratio, dropout)
self.decoder = Decoder(decoder_layer, num_layers=dec_depth, norm=nn.LayerNorm(embed_dim))
# Perm/attn mask stuff
self.rng = np.random.default_rng()
self.max_gen_perms = perm_num // 2 if perm_mirrored else perm_num
self.perm_forward = perm_forward
self.perm_mirrored = perm_mirrored
# We don't predict <bos> nor <pad>
self.head = nn.Linear(embed_dim, len(self.tokenizer) - 2)
self.text_embed = TokenEmbedding(len(self.tokenizer), embed_dim)
# +1 for <eos>
self.pos_queries = nn.Parameter(torch.Tensor(1, max_label_length + 1, embed_dim))
self.dropout = nn.Dropout(p=dropout)
# Encoder has its own init.
named_apply(partial(init_weights, exclude=['encoder']), self)
nn.init.trunc_normal_(self.pos_queries, std=.02)
@torch.jit.ignore
def no_weight_decay(self):
param_names = {'text_embed.embedding.weight', 'pos_queries'}
enc_param_names = {'encoder.' + n for n in self.encoder.no_weight_decay()}
return param_names.union(enc_param_names)
def encode(self, img: torch.Tensor):
return self.encoder(img)
def decode(self, tgt: torch.Tensor, memory: torch.Tensor, tgt_mask: Optional[Tensor] = None,
tgt_padding_mask: Optional[Tensor] = None, tgt_query: Optional[Tensor] = None,
tgt_query_mask: Optional[Tensor] = None):
N, L = tgt.shape
# <bos> stands for the null context. We only supply position information for characters after <bos>.
null_ctx = self.text_embed(tgt[:, :1])
tgt_emb = self.pos_queries[:, :L - 1] + self.text_embed(tgt[:, 1:])
tgt_emb = self.dropout(torch.cat([null_ctx, tgt_emb], dim=1))
if tgt_query is None:
tgt_query = self.pos_queries[:, :L].expand(N, -1, -1)
tgt_query = self.dropout(tgt_query)
return self.decoder(tgt_query, tgt_emb, memory, tgt_query_mask, tgt_mask, tgt_padding_mask)
def forward(self, images: Tensor, max_length: Optional[int] = None) -> Tensor:
testing = max_length is None
max_length = self.max_label_length if max_length is None else min(max_length, self.max_label_length)
bs = images.shape[0]
# +1 for <eos> at end of sequence.
num_steps = max_length + 1
memory = self.encode(images)
# Query positions up to `num_steps`
pos_queries = self.pos_queries[:, :num_steps].expand(bs, -1, -1)
# Special case for the forward permutation. Faster than using `generate_attn_masks()`
tgt_mask = query_mask = torch.triu(torch.full((num_steps, num_steps), float('-inf'), device=self._device), 1)
if self.decode_ar:
tgt_in = torch.full((bs, num_steps), self.pad_id, dtype=torch.long, device=self._device)
tgt_in[:, 0] = self.bos_id
logits = []
for i in range(num_steps):
j = i + 1 # next token index
# Efficient decoding:
# Input the context up to the ith token. We use only one query (at position = i) at a time.
# This works because of the lookahead masking effect of the canonical (forward) AR context.
# Past tokens have no access to future tokens, hence are fixed once computed.
tgt_out = self.decode(tgt_in[:, :j], memory, tgt_mask[:j, :j], tgt_query=pos_queries[:, i:j],
tgt_query_mask=query_mask[i:j, :j])
# the next token probability is in the output's ith token position
p_i = self.head(tgt_out)
logits.append(p_i)
if j < num_steps:
# greedy decode. add the next token index to the target input
tgt_in[:, j] = p_i.squeeze().argmax(-1)
# Efficient batch decoding: If all output words have at least one EOS token, end decoding.
if testing and (tgt_in == self.eos_id).any(dim=-1).all():
break
logits = torch.cat(logits, dim=1)
else:
# No prior context, so input is just <bos>. We query all positions.
tgt_in = torch.full((bs, 1), self.bos_id, dtype=torch.long, device=self._device)
tgt_out = self.decode(tgt_in, memory, tgt_query=pos_queries)
logits = self.head(tgt_out)
if self.refine_iters:
# For iterative refinement, we always use a 'cloze' mask.
# We can derive it from the AR forward mask by unmasking the token context to the right.
query_mask[torch.triu(torch.ones(num_steps, num_steps, dtype=torch.bool, device=self._device), 2)] = 0
bos = torch.full((bs, 1), self.bos_id, dtype=torch.long, device=self._device)
for i in range(self.refine_iters):
# Prior context is the previous output.
tgt_in = torch.cat([bos, logits[:, :-1].argmax(-1)], dim=1)
tgt_padding_mask = ((tgt_in == self.eos_id).int().cumsum(-1) > 0) # mask tokens beyond the first EOS token.
tgt_out = self.decode(tgt_in, memory, tgt_mask, tgt_padding_mask,
tgt_query=pos_queries, tgt_query_mask=query_mask[:, :tgt_in.shape[1]])
logits = self.head(tgt_out)
return logits
def gen_tgt_perms(self, tgt):
"""Generate shared permutations for the whole batch.
This works because the same attention mask can be used for the shorter sequences
because of the padding mask.
"""
# We don't permute the position of BOS, we permute EOS separately
max_num_chars = tgt.shape[1] - 2
# Special handling for 1-character sequences
if max_num_chars == 1:
return torch.arange(3, device=self._device).unsqueeze(0)
perms = [torch.arange(max_num_chars, device=self._device)] if self.perm_forward else []
# Additional permutations if needed
max_perms = math.factorial(max_num_chars)
if self.perm_mirrored:
max_perms //= 2
num_gen_perms = min(self.max_gen_perms, max_perms)
# For 4-char sequences and shorter, we generate all permutations and sample from the pool to avoid collisions
# Note that this code path might NEVER get executed since the labels in a mini-batch typically exceed 4 chars.
if max_num_chars < 5:
# Pool of permutations to sample from. We only need the first half (if complementary option is selected)
# Special handling for max_num_chars == 4 which correctly divides the pool into the flipped halves
if max_num_chars == 4 and self.perm_mirrored:
selector = [0, 3, 4, 6, 9, 10, 12, 16, 17, 18, 19, 21]
else:
selector = list(range(max_perms))
perm_pool = torch.as_tensor(list(permutations(range(max_num_chars), max_num_chars)), device=self._device)[selector]
# If the forward permutation is always selected, no need to add it to the pool for sampling
if self.perm_forward:
perm_pool = perm_pool[1:]
perms = torch.stack(perms)
if len(perm_pool):
i = self.rng.choice(len(perm_pool), size=num_gen_perms - len(perms), replace=False)
perms = torch.cat([perms, perm_pool[i]])
else:
perms.extend([torch.randperm(max_num_chars, device=self._device) for _ in range(num_gen_perms - len(perms))])
perms = torch.stack(perms)
if self.perm_mirrored:
# Add complementary pairs
comp = perms.flip(-1)
# Stack in such a way that the pairs are next to each other.
perms = torch.stack([perms, comp]).transpose(0, 1).reshape(-1, max_num_chars)
# NOTE:
# The only meaningful way of permuting the EOS position is by moving it one character position at a time.
# However, since the number of permutations = T! and number of EOS positions = T + 1, the number of possible EOS
# positions will always be much less than the number of permutations (unless a low perm_num is set).
# Thus, it would be simpler to just train EOS using the full and null contexts rather than trying to evenly
# distribute it across the chosen number of permutations.
# Add position indices of BOS and EOS
bos_idx = perms.new_zeros((len(perms), 1))
eos_idx = perms.new_full((len(perms), 1), max_num_chars + 1)
perms = torch.cat([bos_idx, perms + 1, eos_idx], dim=1)
# Special handling for the reverse direction. This does two things:
# 1. Reverse context for the characters
# 2. Null context for [EOS] (required for learning to predict [EOS] in NAR mode)
if len(perms) > 1:
perms[1, 1:] = max_num_chars + 1 - torch.arange(max_num_chars + 1, device=self._device)
return perms
def generate_attn_masks(self, perm):
"""Generate attention masks given a sequence permutation (includes pos. for bos and eos tokens)
:param perm: the permutation sequence. i = 0 is always the BOS
:return: lookahead attention masks
"""
sz = perm.shape[0]
mask = torch.zeros((sz, sz), device=self._device)
for i in range(sz):
query_idx = perm[i]
masked_keys = perm[i + 1:]
mask[query_idx, masked_keys] = float('-inf')
content_mask = mask[:-1, :-1].clone()
mask[torch.eye(sz, dtype=torch.bool, device=self._device)] = float('-inf') # mask "self"
query_mask = mask[1:, :-1]
return content_mask, query_mask
def training_step(self, batch, batch_idx) -> STEP_OUTPUT:
images, labels = batch
tgt = self.tokenizer.encode(labels, self._device)
# Encode the source sequence (i.e. the image codes)
memory = self.encode(images)
# Prepare the target sequences (input and output)
tgt_perms = self.gen_tgt_perms(tgt)
tgt_in = tgt[:, :-1]
tgt_out = tgt[:, 1:]
# The [EOS] token is not depended upon by any other token in any permutation ordering
tgt_padding_mask = (tgt_in == self.pad_id) | (tgt_in == self.eos_id)
loss = 0
loss_numel = 0
n = (tgt_out != self.pad_id).sum().item()
for i, perm in enumerate(tgt_perms):
tgt_mask, query_mask = self.generate_attn_masks(perm)
out = self.decode(tgt_in, memory, tgt_mask, tgt_padding_mask, tgt_query_mask=query_mask)
logits = self.head(out).flatten(end_dim=1)
loss += n * F.cross_entropy(logits, tgt_out.flatten(), ignore_index=self.pad_id)
loss_numel += n
# After the second iteration (i.e. done with canonical and reverse orderings),
# remove the [EOS] tokens for the succeeding perms
if i == 1:
tgt_out = torch.where(tgt_out == self.eos_id, self.pad_id, tgt_out)
n = (tgt_out != self.pad_id).sum().item()
loss /= loss_numel
self.log('loss', loss)
return loss
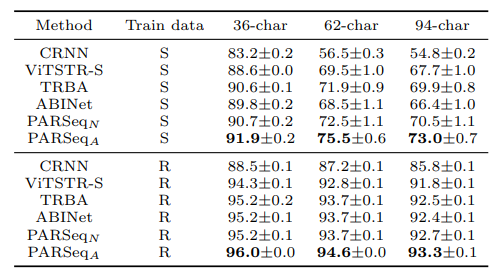
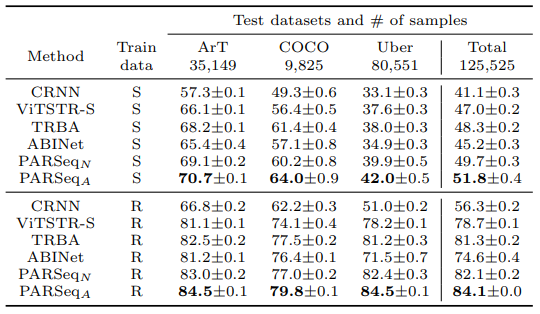
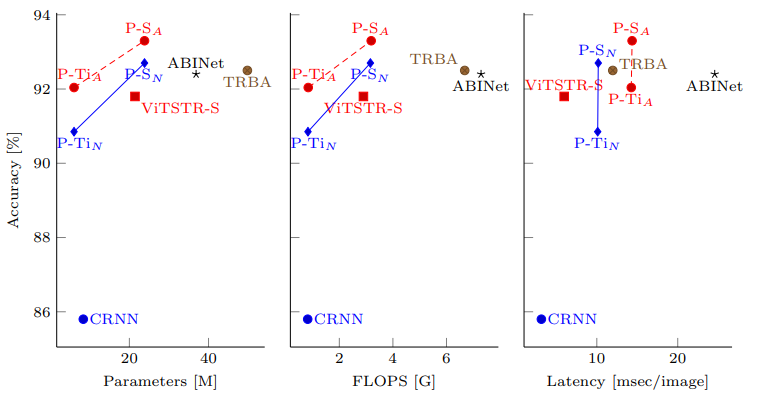
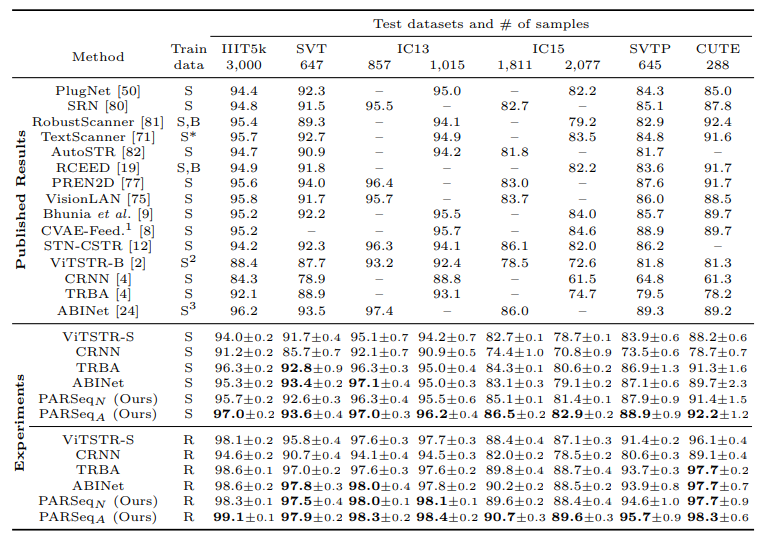
Kết quả thực nghiệm
Các bảng dưới là kết quả của PARSeq so sánh với các mô hình SOTA trên nhiều tập dữ liệu khác nhau.
Tham khảo
[1] Scene Text Recognition with Permuted Autoregressive Sequence Models
All rights reserved
