[Paper reading] PaLI: A Jointly-Scaled Multilingual Language-Image Model
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung
Việc tăng dung lượng mạng neural đã đạt những thành tựu nhất định với các tác vụ liên quan đến NLP và Computer Vision. Ý tưởng cơ bản là ta "nhồi" thêm dữ liệu và tăng độ phức tạp mô hình để thu về một model khủng có độ chính xác cao.  Trong các bài toán NLP, các mô hình như T5, GPT-3, Megatron-Turing, GLAM, Chinchilla, và PaLM đã cho thấy những lợi thế đáng kể từ việc training quy mô lớn Transformer trên số lượng lớn dữ liệu văn bản. Với các bài về Computer Vision, không thể không chú ý đến các model họ Transformer như ViT, BEiT,....
Trong các bài toán NLP, các mô hình như T5, GPT-3, Megatron-Turing, GLAM, Chinchilla, và PaLM đã cho thấy những lợi thế đáng kể từ việc training quy mô lớn Transformer trên số lượng lớn dữ liệu văn bản. Với các bài về Computer Vision, không thể không chú ý đến các model họ Transformer như ViT, BEiT,....
Trong bài báo, nhóm tác giả đề xuất mô hình PaLI (Pathways Language and Image). PaLI có thể thực hiện được nhiều tác vụ liên quan đến Computer Vision, NLP và thậm chí cả 2 Một số điểm hay trong bài báo ta có thể liệt kê như sau:
- Model PaLI tái sử dụng các backbone lớn để thực hiện modeling ngôn ngữ và hình ảnh, mục tiêu là chuyển giao các khả năng hiện có và giảm chi phí đào tạo.
- Scale đồng thời các thành phần về vision và ngôn ngữ mang lại một số lợi ích, đặc biệt với vision (cải thiện độ chính xác trên mỗi tham số / FLOP). Kết quả là với model PaLI lớn nhất là PaLI-17B, được phân phối tương đối đồng đêu giữa hai phương thức, với thành phần ViT-e chiếm khoảng 25% tổng số tham số. Điều này không phải lúc nào cũng đúng với những cách làm trước đây trong lĩnh vực mô hình ngôn ngữ và vision dung lượng lớn, lý do là sự không phù hợp về scale giữa backbone về vision và ngôn ngữ.
- Chia sẻ tri thức giữa các task về vision ngôn ngữ bằng cách chuyển chúng thành một task VQA tổng quát.

Để đào tạo PaLI-17B, nhóm tác giả xây dựng dataset lớn về ngôn ngữ và hình ảnh, WebLI, bao gồm 10 tỷ cặp mẫu hình ảnh-văn bản. Đặc biệt WebLI chứa văn bản với hơn 100 ngôn ngữ.
Ngoài ra, một điểm hay ho trong bài báo là nhóm tác giả cung cấp một lộ trình mở rộng quy mô cho các mô hình đa phương thức trong tương lai. Tỷ lệ mô hình là đặc biệt quan trọng để hiểu ngôn ngữ-hình ảnh trong môi trường đa ngôn ngữ. Kết quả của nhóm tác giả hỗ trợ kết luận rằng việc mở rộng các thành phần của mỗi phương thức mang lại hiệu suất tốt hơn so với nhiều lựa chọn thay thế khác.
PaLI Model
Kiến trúc model
Thông thường, với những task mà cần sự kết hợp giữa cả mô hình ngôn ngữ và hình ảnh (ví dụ như VQA chẳng hạn), ý tưởng cơ bản là ta thường kết hợp các model rời rạc với nhau. Cách này có điểm hạn chế là trong khi các bài toán Image classification và các dạng bài VQA thường yêu cầu dự đoán các phần tử trong 1 tập cố định thì các task về ngôn ngữ và image captioning lại yêu cầu cần phải sinh một văn bản với từ vựng mở. Để giải quyết sự "không khớp" này, nhóm tác giả đề xuất một phương pháp tổng quát cho tất cả các task có đặc điểm như sau:
- Mô hình sẽ có input là ảnh và 1 string
- Output mô hình sẽ là đoạn văn bản nào đó
- Vì là mô hình tổng quát nên sẽ không có tham số cụ thể cho mỗi task và "head" của mô hình
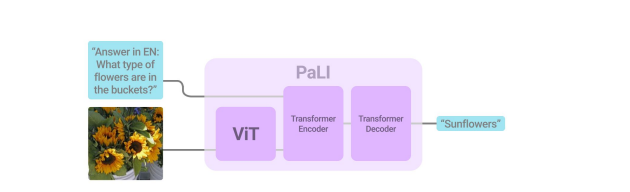
Như hình trên, bạn có thể thấy ta có một bộ text encoder-decoder Transformer. Đối với text thì dễ rồi, nhưng làm thế nào để cho hình ảnh làm đầu vào của bộ text encoder-decoder Transformer này? Cách làm là ta sẽ cho hình ảnh qua Vision Transformer, output feature của bước này sẽ được đưa vào encoder-decoder model.
Visual Component Nhóm tác giả train kiến trúc ViT-e với cách thức giống như train ViT-G và mô hình này được scale lên 4 tỷ tham số. Điểm khác biệt là áp dụng chiến lược "learning rate cool-down" 2 lần, 1 lần áp dụng inception crop augmentation và 1 lần không. sau đó trung bình trọng số của 2 lần này.
Language Component Nhóm tác giả sử dụng backbone mT5 làm mô hình ngôn ngữ. Mô hình được train trên nhiều task, bao gồm cả task language understanding thuần.
Overall model Trong phần này, kích thước mô hình được xét với 3 phiên bản như bảng dưới đây

Dữ liệu
Với mô hình lớn cần có một bộ dữ liệu lớn để hoạt động hiệu quả. Nhóm tác giả sử dụng bộ dữ liệu WebLI, bộ dữ liệu này bao gồm ảnh và văn bản đa ngôn ngữ từ các trang web public.
Đặc biệt, do quy mô của WebLI, để giảm thiểu vấn đề rò rỉ train-to-test, nhóm tác giả thực hiện lọc các mẫu trùng lặp.
Để cải thiện chất lượng dữ liệu về mặt image-text alignment, nhóm tác giả đánh điểm số cặp hình ảnh-văn bản dựa trên cross-mdoal similarity. Điểm số này được tính bằng cách sử dụng cosine similarity giữa các embedding representation từ mỗi phương thức. Cách tính sẽ như sau:
- Các embedding của ảnh được train với một graph-based sử dụng cách tiếp cận semi-supervised representation
- Các embedding của văn bản được train bằng cách sử dụng embedding hình ảnh được frozen với cách tiếp cận contrastive, khi đó cả 2 phương thức representation này đều về chung 1 không gian embedding
Để cân bằng chất lượng và duy trì quy mô của mô hình, nhóm tác giả tinh chỉnh ngưỡng điểm giữa các cặp hình ảnh-văn. Nhóm tác giả chỉ lấy 10% điểm số cao nhất để sử dụng cho việc train model PaLI.
Pretraining Task Mixture
Để đáp ứng các task đa dạng về hình ảnh - ngôn ngữ, nhóm tác giả train PaLI bằng cách sử dụng hỗn hợp các task pretrained. Hỗn hợp này được thiết kế để mở rộng một loạt các khả năng tổng quát hữu ích cho các task downstream. Ta có thể xét một số task như sau (mình sẽ để tên các task này là tiếng Anh để các bạn có thể tiện tham khảo):
- Span corruption on text-only data
- Split-captioning (SplitCap) on WebLI alt-text data
- Captioning (Cap) on CC3M-35L on native and translated alt-text data
- OCR on WebLI OCR-text data
- English and Cross-Lingual VQA on native and translated VQ2A-CC3M-35L-100M VQA triplets
- English and Cross-Lingual visual question generation (VQG) on native and translated VQ2A-CC3M-35L 100M VQA triplets
- English-only Object-Aware (OA) VQA
- Object detection
Một số điểm hạn chế
Một số điểm hạn chế của model này có thể kể đến như sau:
- Một điều dễ thấy là model không thể mô tả một văn cảnh phức tạp với nhiều object được, lý do là các nhãn cho những mẫu này thường đơn giản và khó cover được hết tất cả. Nhóm tác giả cố gắng khắc phục điều này bằng cách đưa vào dữ liệu các truy vấn về vị trí, vật thể khác nhau
- Một số khả năng đa ngôn ngữ bị mất đi khi fine-tune trễn dữ liệu chỉ có tiếng Anh
- Hạn chế về cách thức đánh giá model. Ví dụ như với task VQA, model có thể cho ra output là đồng nghĩa với ground truth nhưng vì chỉ mang tính đồng nghĩa chứ không "match" hẳn với ground truth nên việc đánh giá sẽ gặp khó khăn. Thậm chí vài trường hợp về mặt ngữ nghĩa mà con người đánh giá thì đúng, nhưng sử dụng công thức tính evaluation sẽ bị đánh sai.
Kết luận
Nhóm tác giả trình bày PaLI, một model ngôn ngữ và hình ảnh được chia tỷ lệ chung nhắm mục tiêu đến nhiều nhiệm vụ ngôn ngữ và hình ảnh. PaLI sử dụng lại các mô hình đơn phương thức pretrained và tận dụng khả năng của chúng, đồng thời bù đắp chi phí đáng kể cho những nỗ lực đào tạo quy mô lớn. Nhóm tác giả cũng mở rộng PaLI trên cả ngôn ngữ và các, đồng thời tận dụng một tập dữ liệu đào tạo ngôn ngữ-hình ảnh lớn là WebLI, bao gồm hơn 100 ngôn ngữ. PaLI thiết lập các kết quả hiện đại mới trên nhiều task hình ảnh-ngôn ngữ, vượt trội so với các mô hình mạnh hiện có.
Qua bài viết, bạn đọc hiểu và nắm được một số ý chính về cách xây dựng một mô hình hình ảnh-ngôn ngữ tổng quát. Cách làm việc và những vấn đề cần quan tâm khi thao tác với một mô hình lớn trên một tập dữ liệu lớn, sẽ có rất nhiều yếu tố cần phải quan tâm và cân nhắc đến
Tài liệu tham khảo
[1] PaLI: A Jointly-Scaled Multilingual Language-Image Model
[3] https://github.com/google/flax
All rights reserved
