Paper reading | Fastformer: Additive Attention Can Be All You Need
Bài đăng này đã không được cập nhật trong 2 năm
1. Động lực
Transformer là model nổi tiếng với khả năng xử lý trên dữ liệu dạng văn bản một cách mạnh mẽ. Tuy nhiên, điểm trừ lớn của Transformer là độ phức tạp bậc hai với độ dài của chuỗi đầu vào. Trong bài báo, nhóm tác giả đề xuất model Fastformer với mục tiêu tăng độ hiệu quả của model Transformer dựa trên cơ chế additive attention.
2. Đóng góp
Trong Fastformer thay vì modeling tương tác giữa các cặp token thì ta modeling global context sử dụng cơ chế additive attention và sau đó biến đổi mỗi biểu diễn của token dựa trên tương tác của chúng với biểu diễn global context. Với cách này thì Fastformer có thể modeling context hiệu quả với độ phức tạp tuyến tính. Các thử nghiệm mở rộng trên 5 bộ dữ liệu cho thấy Fastformer hiệu quả hơn nhiều mẫu Transformer hiện có mà trong khi đó có thể đạt được hiệu suất modeling văn bản dài tương đương hoặc thậm chí tốt hơn.
3. Phương pháp
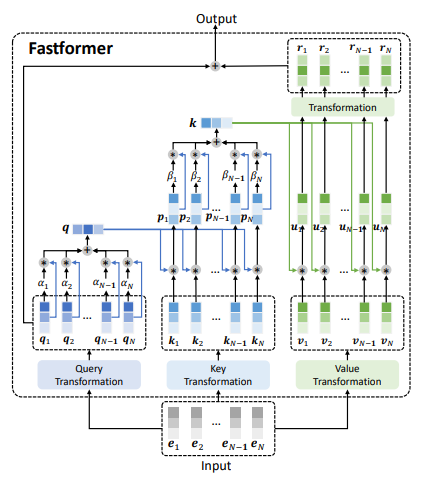
Kiến trúc mô hình Fastformer được thể hiện trong hình trên. Các bước tổng quan của mô hình như sau:
- Đầu tiên, sử dụng cơ chế additive attention để tổng hợp query sequence thành một global query vector.
- Tiếp theo, mô hình sự tương tác giữa global query vector và các attention key sử dụng phép nhân element-wise. Sau đó tổng hợp các key thành một global key vector thông qua additive attention.
- Tiếp theo, ta mô hình sự tương tác giữa global key và các attention value thông qua phép nhân element-wise và sử dụng một biến đổi tuyến tính để học các global context-aware attention value.
- Cuối cùng, cộng các giá trị trên với attention query để cho ra output cuối cùng.
3.1. Kiến trúc
Đầu tiên, model Fastformer biến đổi ma trận input embedding thành các chuỗi query, key và value. Ma trận input được kí hiệu là trong đó kà độ dài chuỗi và là hidden dimension. Các vector cấu thành ma trận này là như hình dưới:
Theo mô hình Transformer chuẩn, mỗi attention head sử dụng 3 layer biến đổi tuyến tính độc lập để biến đổi input thành các ma trận attention query, key, value và có thể được viết lại như sau và .
Việc mô hình được context của chuỗi đầu vào dựa trên tương tác giữa attention query, key và value là rất quan trọng. Tuy nhiên việc sử dụng cơ chế dot-product attention có độ phức tạp bậc 2 là không hiệu quả với việc mô hình các chuỗi dài. Tham khảo hình và code ở dưới:

class ScaleDotProductAttention(nn.Module):
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
Vì lý do trên, tác giả đề xuất phương pháp làm giảm độ phức tạp tính toán bằng cách tổng hợp ma trận attention (ví dụ như query) trước khi mô hình các sự tương tác. Để đạt được điều này, tác giả sử dụng additive attention để tổng hợp ma trận query thành một global query vector tóm gọn thông tin global context trong attention query. Cụ thể hơn, trọng số attention của vector query thứ được tính như sau:
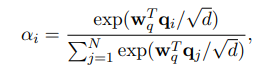
Trong đó là learnable parameter vector. Global attention query được tính như sau:
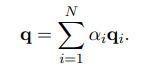
Vấn đề tiếp theo là làm như nào để Fastformer có thể mô hình được sự tương tác giữa global query vector và ma trận key. Ta có thể sử dụng một số cách như cộng hoặc concat global query vector với từng vector trong ma trận key. Tuy nhiên, các cách này không thể phân biệt ảnh hưởng của global query đối với các key khác nhau, điều này không có lợi cho việc hiểu context. Do vậy, nhóm tác giả sử dụng element-wise product, operator này hiệu quả cho việc biểu diễn quan hệ phi tuyến tính giữa 2 vector. Ta công thức phép toán này như sau:
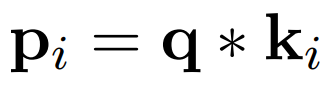
trong đó: * là element-wise product. là vector thứ trong global context-aware key matrix. Tương tự như tổng hợp global query vector ta sử dụng cơ chế additive attention để tổng hợp ma trận global context-aware key.
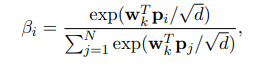
Trong đó là learnable parameter vector. Global key vector được tính như sau:
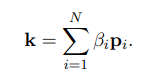
Bước cuối cùng là ta sẽ mô hình sự tương tác giữa ma trận attention value và global key vector. Tương tự như 2 bước trên ta vẫn sẽ dùng element-wise product giữa global key và mỗi value vector và cho ra key-value interaction vector , công thức như sau: . Sau đó ta sử dụng một linear transformation layer cho mỗi key-value interaction vector để học biểu diễn ẩn của chúng. Ma trận output của layer này được biểu thị như sau . Tiếp theo ma trận này lại tiếp tục được cộng với query matrix để cho ra output cuối cùng 
3.2. Phân tích độ phức tạp
Độ phức tạp tính toán và bộ nhớ của Fastformer (không tính phần Query, Key, Value Transformer) là . Trong khi đó, Transformer tiêu chuẩn có độ phức tạp tính toán là .
4. Thực nghiệm
Dưới đây là một số thống kê về dataset được sử dụng để thực nghiệm.
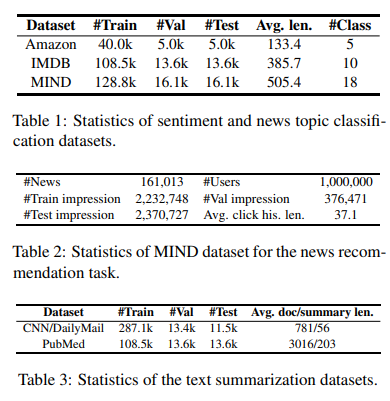
Bảng dưới là kết quả khi sử dụng các method khác nhau trong task sentiment classification và topic classification.
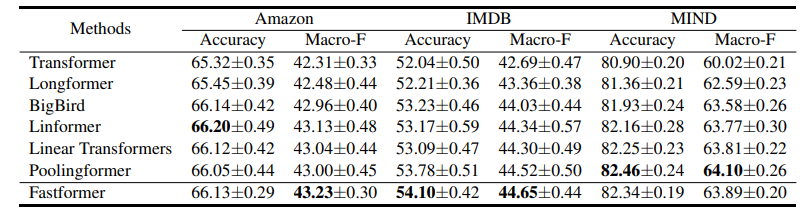
Bảng dưới là hiệu suất của các method khác nhau trong task news recommendation.
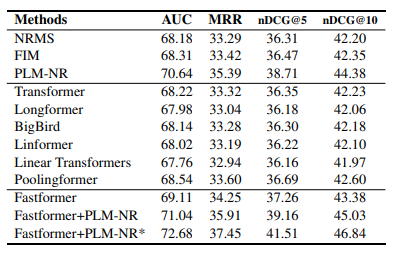
Bảng dưới là hiệu suất của các method khác nhau trong task text summarization.
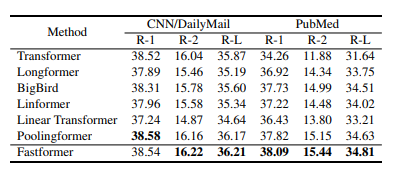
5. Kết luận
Bài báo cho ta một ý tưởng đơn giản nhưng khá hay để giảm độ phức tạp tính toán của mô hình Transformer tiêu chuẩn. Mô hình có thể ứng dụng trong nhiều task khác nhau thuộc NLP và Recommendation system.
6. Tham khảo
[1] Fastformer: Additive Attention Can Be All You Need
[2] The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)
All rights reserved
