Paper reading | Expanding Language-Image Pretrained Models for General Video Recognition
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung
Video recognition là một lĩnh vực trong trí tuệ nhân tạo (AI) và thị giác máy tính tập trung vào việc phân tích và nhận dạng nội dung trong các video. Mục tiêu của video recognition là hiểu về các hình ảnh, đối tượng, hành động và sự tương tác trong video giống như cách con người làm. Công nghệ video recognition đã phát triển đáng kể nhờ sự tiến bộ trong AI, xử lý ảnh và tài nguyên tính toán.
Có nhiều ứng dụng quan trọng của video recognition trong thế giới thực, có thể kể đến một số ví dụ điển hình sau:
-
Giám sát an ninh: Video recognition được sử dụng trong hệ thống giám sát an ninh để phát hiện và nhận dạng các hoạt động đáng ngờ, như xâm nhập, vật thể nghi vấn và hành vi không phù hợp. Việc này giúp cải thiện đáng kể khả năng phát hiện và giám sát trong các khu vực như ngân hàng, sân bay, trung tâm mua sắm và các cơ sở quân sự.
-
Xử lý video tự động: Video recognition được sử dụng để tự động phân loại và gắn nhãn các video dựa trên nội dung chúng. Điều này giúp tạo ra các công cụ tìm kiếm video thông minh và hệ thống gợi ý video, đồng thời cải thiện trải nghiệm người dùng và khả năng quản lý nội dung trên các nền tảng video trực tuyến.
-
Xe tự hành: Video recognition cũng đóng vai trò quan trọng trong xe tự hành. Các hệ thống xe tự hành sử dụng video recognition để phát hiện và nhận dạng các vật thể xung quanh, như người đi bộ, xe đạp, ô tô và biển báo giao thông. Điều này giúp xe tự hành đưa ra quyết định an toàn và tương tác thông minh với môi trường xung quanh.
-
Quảng cáo và truyền thông: Video recognition cung cấp khả năng phân tích nội dung video. Các công ty quảng cáo có thể sử dụng thông tin này để tạo ra các chiến dịch quảng cáo được cá nhân hóa hơn và đưa ra đề xuất sản phẩm phù hợp dựa trên sở thích và hành vi xem video của khách hàng.
Đó chỉ là một số ứng dụng phổ biến của video recognition, lĩnh vực này đang phát triển và mở ra nhiều cơ hội mới trong nhiều ngành công nghiệp khác nhau.
Với nhiều ứng dụng thực tiễn, nhiều nghiên cứu đã được thực hiện để cung cấp giải pháp cho bài toán này.
Đóng góp của bài báo
Đóng góp của bài báo:
- Thiết kế một kiến trúc mô hình mới cho việc mô hình video temporal.
- Xây dựng kĩ thuật video-specific prompting để trả về biểu diễn văn bản ở mức instance-level một cách tự động. Kĩ thuật này sử dụng thông tin nội dung video để nâng cao chất lượng tạo prompt.
- Đề xuất một cách mới để mở rộng các mô hình language-image pretrained cho bài toán video recognition và các task về video khác.
Phương pháp
Tổng quan
Các phương pháp trước đây giải quyết bài toán Video recognition theo hướng là học feature embedding riêng biệt được supervise theo các label one-hot. Nhược điểm của cách này là khả năng dự đoán bị đóng khung theo các label có sẵn, do đó sẽ rất khó để train những label khác mà không có trong tập label hiện tại. Chính vì vậy, giống như các mô hình contrastive language-image pretraining, nhóm tác giả sử dụng text là supervision vì text cung cấp nhiều ngữ nghĩa thông tin hơn.
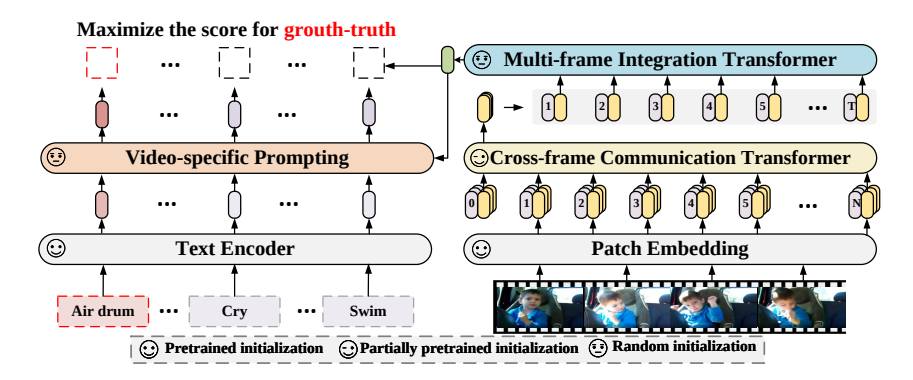
Phương pháp đề xuất trong bài báo là học cách căn chỉnh biểu diễn video và biểu diễn text tương ứng bằng cách train cả video encoder và text encoder. Thay vì tốn tài nguyên và thời gian để train lại từ đầu cũng như tận dụng được sức mạnh của các model pretraining trước đó, phương pháp tận dùng các model pretraining này và mở rộng với dạng video và các textual prompt.
Cụ thể, cho một video clip và text description tương ứng là trong đó là tập các video và là tập tên các category. Đầu tiên ta sẽ truyền video vào video encoder và text vào text encoder để nhận biểu diễn video và biểu diễn text tương ứng, trong đó
![]()
Sau đó, ta sử dụng prompt generator để trả về instance-level biểu diễn text cho mỗi video, cụ thể như sau:
![]()
Cuối cùng, ta sử dụng consine similarity để tính độ tương đồng giữa biểu diện hình ảnh và text.
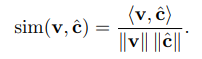
Mục tiêu của phương pháp này là tối đa hóa nếu như và khớp nhau, ngược lại tất nhiên là tối thiểu hóa 
Video Encoder
Video encoder bao gồm 2 thành phần:
- Cross-frame communication transformer có nhiệm vụ nhận các frame làm input, thông qua pretrained language-image model, output là các biểu diễn frame-level có chứa thông tin trao đổi giữa các frame.
- Multi-frame integration transformer có nhiệm vụ tích hợp các biểu diễn frame-level với các video feature.
Cụ thể, cho một video clip trong đó là số frame được lấy mẫu, và là chiều cao và chiều rộng của frame, theo model ViT ta sẽ chia frame thành patch không chồng chéo nhau, mỗi patch sẽ có kích thước là pixel và . Sau đó, ý tưởng như ViT ta sẽ nhúng các patch vào patch embedding sử dụng linear projection . Tiếp theo, ta sẽ thêm một learnable embedding là (hay class token) vào chuỗi các patch được embedding. Vậy ta có đầu vào của cross-frame communication transformer tại frame được biểu diễn như sau:
![]()
trong đó là spatial position encoding.
Tiếp theo ta sẽ truyền các patch embedding trên vào một Lc-layer Cross-frame Communication Transformer (CCT) để nhận biểu diễn frame-level :
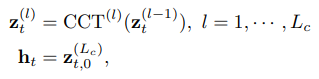
trong đó là block index của CCT, biểu diễn final output của class token.
Cuối cùng, - layer Multi-frame Integration Transformer (MIT) nhận tất cả các biểu diễn frame làm input và output là video-level representation được biểu diễn như sau:
![]()
trong đó AvgPool và lần lượt là average pooling và temporal position encoding. Multi-frame integration transformer được xây dựng bởi multi-head self-attention và feed-forward networks tiêu chuẩn
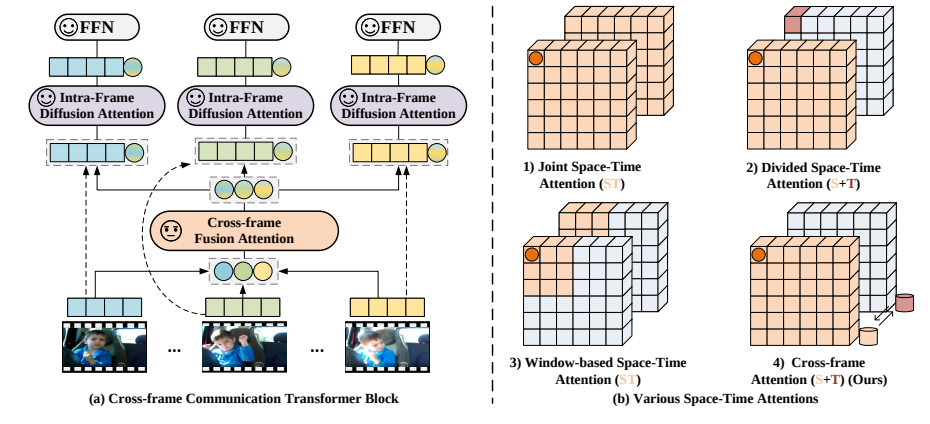
Để có thể có được thông tin trao đổi giữa các frame với nhau, nhóm tác giả đề xuất một module attention mới. Thành phần của module này gồm 2 loại attention là cross-frame fusion attention (CFA) và intra-frame diffusion attention (IFA), với một feed-forward network (FFN). Nhóm cũng giới thiệu cơ chế message token cho mỗi frame có vai trò trừu tượng, gửi và nhận thông tin, do đó có thể trao đổi thông tin visual giữa các frame như hình trên.
Cụ thể, message token cho frame thứ tại layer thứ được tạo bằng cách sử dụng một linear transformation trên class token . Điều này cho phép các message token có thể trừu tượng thông tin visual của frame hiện tại.
Sau đó, ta sẽ tổng hợp các message token để học các phụ thuộc toàn cục spatio-temporal của video đầu vào. Cụ thể, quá trình tại block thứ như sau:
![]()
trong đó, và LN là layer normalization.
Sau đó, IFA nhận các frame token với message token liên kết (xem hình trên) để học biểu diễn visual, trong đó message token liên quan cũng có thể "khuếch tán" phụ thuộc spatio-temporal toàn cục cho quá trình học. Quá trình tại block thứ được biểu diễn như sau:
![]()
trong đó concat các feature của frame token và message token.
Cuối cùng, ta cho các frame token qua feed-forward network (FFN) như sau
![]()
Chú ý rằng, message token được bỏ qua trước FFN layer và không được truyền vào block sau, lý do là message token được tạo liên tục và được sử dụng cho frame communication trong mỗi block.
Bằng cách thực hiện đan xen việc kết hợp và phân tán các attention qua các block, CCT có thể encode thông tin spatial và temporal toàn cục của các video frames. Mặt khác, điều này cũng giảm đáng kể chi phí tính toán (xem hình dưới).
Về việc khởi tạo, thay vì train từ đầu, mô hình tận dụng các pretrained image encoder vào video encoder và có 2 chỉnh sửa chính:
- IFA kết thừa trọng số trực tiếp từ các pretrained model, trong khi CFA được khởi tạo ngẫu nhiên.
- MIT được khởi tạo ngẫu nhiên.
Text Encoder
Nhóm tác giả sử dụng pretrained text encoder và mở rộng cho việc xây dựng nội dung mô tả cho video. Gọi là mô tả của một video và biểu diễn text () tạo bởi text encoder. Nhóm tác giả chỉ sử dụng tên nhãn cơ bản, ngắn gọn làm text description và đề xuất một text prompting scheme có thể học được.
Để hiểu ảnh hoặc video, ta thường cần một ngữ cảnh để hỗ trợ phân biệt. Ví dụ như ngữ cảnh "in the water" sẽ giúp ta dễ dàng phân biệt "swimming" và "running". Tuy nhiên, rất khó để có được ngữ nghĩa trực quan như vậy trong các tác vụ nhận dạng video, lý do là dataset chỉ cung cấp tên các category cố định và video có cùng class sẽ có cùng category nhưng visual context và content có thể khác nhau. Để giải quyết vấnd dề này, nhóm tác giả đề xuất một learnable prompting scheme để sinh biểu diễn text tự động. Cụ thể như sau:
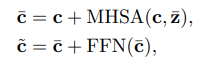
trong đó là text embedding, MHSA là multi-head self-attention, là trung bình của và là prompt của video. Nhóm tác giả sử dụng biểu diễn text là query và biểu diễn nội dung video là key và value. Cách cài đặt này giúp cho biểu diễn text có thể trích xuất thông tin visual context từ video.
Sau đó, nhóm tác giả cài đặt , trong đó là learnable parameter được khởi tạo giá trị là 0.1. Giá trị cuối cùng được sử dụng cho việc phân loại.
Coding
Khối CCT được xây dựng như sau:
from collections import OrderedDict
from timm.models.layers import trunc_normal_
import torch
from torch import nn
from torch.utils.checkpoint import checkpoint_sequential
import sys
sys.path.append("../")
from clip.model import LayerNorm, QuickGELU, DropPath
class CrossFramelAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None, droppath = 0., T=0, ):
super().__init__()
self.T = T
self.message_fc = nn.Linear(d_model, d_model)
self.message_ln = LayerNorm(d_model)
self.message_attn = nn.MultiheadAttention(d_model, n_head,)
self.attn = nn.MultiheadAttention(d_model, n_head,)
self.ln_1 = LayerNorm(d_model)
self.drop_path = DropPath(droppath) if droppath > 0. else nn.Identity()
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x):
l, bt, d = x.size()
b = bt // self.T
x = x.view(l, b, self.T, d)
msg_token = self.message_fc(x[0,:,:,:])
msg_token = msg_token.view(b, self.T, 1, d)
msg_token = msg_token.permute(1,2,0,3).view(self.T, b, d)
msg_token = msg_token + self.drop_path(self.message_attn(self.message_ln(msg_token),self.message_ln(msg_token),self.message_ln(msg_token),need_weights=False)[0])
msg_token = msg_token.view(self.T, 1, b, d).permute(1,2,0,3)
x = torch.cat([x, msg_token], dim=0)
x = x.view(l+1, -1, d)
x = x + self.drop_path(self.attention(self.ln_1(x)))
x = x[:l,:,:]
x = x + self.drop_path(self.mlp(self.ln_2(x)))
return x
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None, droppath=None, use_checkpoint=False, T=8):
super().__init__()
self.use_checkpoint = use_checkpoint
if droppath is None:
droppath = [0.0 for i in range(layers)]
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[CrossFramelAttentionBlock(width, heads, attn_mask, droppath[i], T) for i in range(layers)])
def forward(self, x: torch.Tensor):
if not self.use_checkpoint:
return self.resblocks(x)
else:
return checkpoint_sequential(self.resblocks, 3, x)
class CrossFrameCommunicationTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int,
droppath = None, T = 8, use_checkpoint = False,):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
## Attention Blocks
self.transformer = Transformer(width, layers, heads, droppath=droppath, use_checkpoint=use_checkpoint, T=T,)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def init_weights(self):
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2)
x = self.transformer(x)
x = x.permute(1, 0, 2)
cls_x = self.ln_post(x[:, 0, :])
if self.proj is not None:
cls_x = cls_x @ self.proj
return cls_x, x[:,1:,:]
Khối MIT được xây dựng như sau:
import torch
from torch import nn
from collections import OrderedDict
from timm.models.layers import trunc_normal_
import sys
sys.path.append("../")
from clip.model import QuickGELU
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = nn.LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class MultiframeIntegrationTransformer(nn.Module):
def __init__(self, T, embed_dim=512, layers=1,):
super().__init__()
self.T = T
transformer_heads = embed_dim // 64
self.positional_embedding = nn.Parameter(torch.empty(1, T, embed_dim))
trunc_normal_(self.positional_embedding, std=0.02)
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(d_model=embed_dim, n_head=transformer_heads) for _ in range(layers)])
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Linear,)):
trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
ori_x = x
x = x + self.positional_embedding
x = x.permute(1, 0, 2)
x = self.resblocks(x)
x = x.permute(1, 0, 2)
x = x.type(ori_x.dtype) + ori_x
return x.mean(dim=1, keepdim=False)
Tiếp theo, ta có module text encoder
from timm.models.layers import trunc_normal_
import torch
from torch import nn
import sys
sys.path.append("../")
from clip.model import QuickGELU
class MulitHeadAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q_proj = nn.Linear(dim, dim, bias=qkv_bias)
self.k_proj = nn.Linear(dim, dim, bias=qkv_bias)
self.v_proj = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, q, k, v):
B, N, C = q.shape
B, M, C = k.shape
q = self.q_proj(q).reshape(B, N, self.num_heads, C // self.num_heads).permute(0,2,1,3)
k = self.k_proj(k).reshape(B, M, self.num_heads, C // self.num_heads).permute(0,2,1,3)
v = self.v_proj(v).reshape(B, M, self.num_heads, C // self.num_heads).permute(0,2,1,3)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class PromptGeneratorLayer(nn.Module):
def __init__(
self,
d_model,
nhead,
dropout=0.,
):
super().__init__()
self.cross_attn = MulitHeadAttention(d_model, nhead, proj_drop=dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model * 4),
QuickGELU(),
nn.Dropout(dropout),
nn.Linear(d_model * 4, d_model)
)
def forward(self, x, visual):
q = k = v = self.norm1(x)
x = x + self.cross_attn(q, visual, visual)
x = x + self.dropout(self.mlp(self.norm3(x)))
return x
class VideoSpecificPrompt(nn.Module):
def __init__(self, layers=2, embed_dim=512, alpha=0.1,):
super().__init__()
self.norm = nn.LayerNorm(embed_dim)
self.decoder = nn.ModuleList([PromptGeneratorLayer(embed_dim, embed_dim//64) for _ in range(layers)])
self.alpha = nn.Parameter(torch.ones(embed_dim) * alpha)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, text, visual):
B, N, C = visual.shape
visual = self.norm(visual)
for layer in self.decoder:
text = layer(text, visual)
return self.alpha * text
Tổng hợp lại, ta có model hoàn chỉnh:
from typing import Tuple, Union
import torch
from torch import nn
import numpy as np
from .mit import MultiframeIntegrationTransformer
from .prompt import VideoSpecificPrompt
from .cct import CrossFrameCommunicationTransformer
import sys
import warnings
sys.path.append("../")
from clip.model import CLIP,LayerNorm,Transformer
import clip
class XCLIP(CLIP):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int,
# video
T=8,
droppath=0.,
mit_layers=1,
# prompt
prompts_alpha=1e-4,
prompts_layers=1,
# other
use_cache=True,
use_checkpoint=False,
):
super().__init__(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
)
self.prompts_generator = VideoSpecificPrompt(layers=prompts_layers, embed_dim=embed_dim, alpha=prompts_alpha,)
self.use_cache=use_cache
self.mit = MultiframeIntegrationTransformer(T=T, embed_dim=embed_dim, layers=mit_layers,)
dpr = [x.item() for x in torch.linspace(0, droppath, vision_layers)] if droppath > 0. else None
vision_heads = vision_width // 64
self.visual = CrossFrameCommunicationTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim,
droppath=dpr,
T=T,
use_checkpoint=use_checkpoint,
)
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.cache_text_features = None
self.prompts_visual_ln = LayerNorm(vision_width)
self.prompts_visual_proj = nn.Parameter(torch.randn(vision_width, embed_dim))
self.initialize_parameters()
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'positional_embedding'}
def encode_image(self, image):
return self.visual(image)
def encode_text(self, text):
x = self.token_embedding(text)
eos_indx = text.argmax(dim=-1)
K, N1, C = x.shape
x = x + self.positional_embedding
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), eos_indx] @ self.text_projection
x = x.reshape(K, -1)
return x
def encode_video(self, image):
b,t,c,h,w = image.size()
image = image.reshape(-1,c,h,w)
cls_features, img_features = self.encode_image(image)
img_features = self.prompts_visual_ln(img_features)
img_features = img_features @ self.prompts_visual_proj
cls_features = cls_features.view(b, t, -1)
img_features = img_features.view(b,t,-1,cls_features.shape[-1])
video_features = self.mit(cls_features)
return video_features, img_features
def cache_text(self, text):
self.eval()
with torch.no_grad():
if self.cache_text_features is None:
self.cache_text_features = self.encode_text(text)
self.train()
return self.cache_text_features
def forward(self, image, text):
b = image.shape[0]
video_features, img_features = self.encode_video(image)
img_features = img_features.mean(dim=1, keepdim=False)
if self.use_cache:
text_features = self.cache_text(text)
else:
text_features = self.encode_text(text)
text_features = text_features.unsqueeze(0).expand(b, -1, -1)
text_features = text_features + self.prompts_generator(text_features, img_features)
video_features = video_features / video_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = torch.einsum("bd,bkd->bk", video_features, logit_scale * text_features)
return logits
def build_model(state_dict: dict, T=8, droppath=0., use_checkpoint=False, logger=None, prompts_alpha=1e-1, prompts_layers=2, use_cache=True, mit_layers=4,):
vit = "visual.proj" in state_dict
if vit:
vision_width = state_dict["visual.conv1.weight"].shape[0]
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
image_resolution = vision_patch_size * grid_size
else:
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
vision_layers = tuple(counts)
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
vision_patch_size = None
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
image_resolution = output_width * 32
embed_dim = state_dict["text_projection"].shape[1]
context_length = state_dict["positional_embedding"].shape[0]
vocab_size = state_dict["token_embedding.weight"].shape[0]
transformer_width = state_dict["ln_final.weight"].shape[0]
transformer_heads = transformer_width // 64
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
model = XCLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers,
T=T, droppath=droppath, mit_layers=mit_layers,
prompts_alpha=prompts_alpha, prompts_layers=prompts_layers,
use_checkpoint=use_checkpoint, use_cache=use_cache,
)
for key in ["input_resolution", "context_length", "vocab_size"]:
if key in state_dict:
del state_dict[key]
msg = model.load_state_dict(state_dict,strict=False)
logger.info(f"load pretrained CLIP: {msg}")
return model.eval()
def load(model_path, name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu",
jit=True, T=8, droppath=0., use_checkpoint=False, logger=None, use_cache=True, prompts_alpha=1e-1, prompts_layers=2, mit_layers=1,
):
if model_path is None:
model_path = clip._download(clip._MODELS[name])
try:
# loading JIT archive
model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
state_dict = None
except RuntimeError:
# loading saved state dict
if jit:
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
jit = False
state_dict = torch.load(model_path, map_location="cpu")
model = build_model(state_dict or model.state_dict(), T=T, droppath=droppath,
use_checkpoint=use_checkpoint, logger=logger,
prompts_alpha=prompts_alpha,
prompts_layers=prompts_layers,
use_cache=use_cache,
mit_layers=mit_layers,
)
if str(device) == "cpu":
model.float()
return model, model.state_dict()
Thực nghiệm
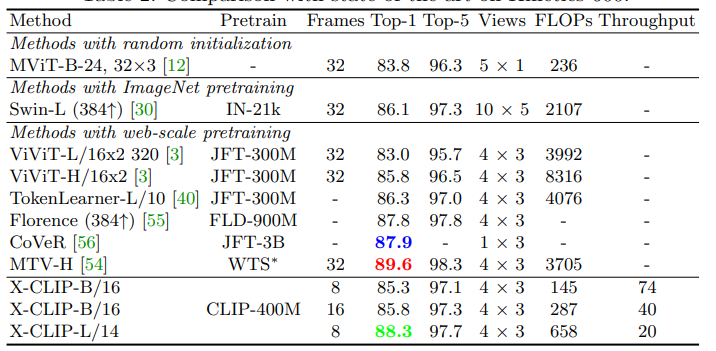
Bảng so sánh kết quả với các SOTA trên bộ data Kinetics-600.
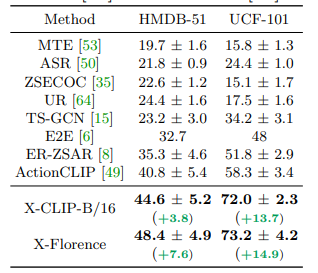
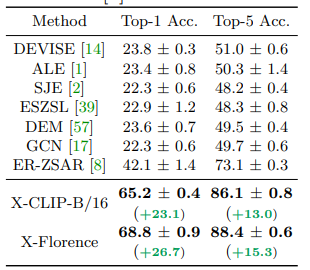
Kết quả khi thực hiện zero shot trên tập HMDB51, UCF101 và Kinetic.
Tham khảo
[1] Expanding Language-Image Pretrained Models for General Video Recognition
All rights reserved
