Multi-Vector Retrieval Algorithm (MUVERA)
https://research.google/blog/muvera-making-multi-vector-retrieval-as-fast-as-single-vector-search/
https://arxiv.org/pdf/2405.19504
https://github.com/sionic-ai/muvera-py
https://github.com/raulcarlomagno/muvera-py-numba
1. Tổng quan
Các mô hình biểu diễn đa vector (multi-vector) như ColBERT hiện là nền tảng của hệ thống truy xuất thông tin (Information Retrievaletrieval) hiện đại nhờ khả năng nắm bắt thông tin ngữ nghĩa sâu sắc, mang lại độ chính xác vượt trội so với các mô hình vector đơn truyền thống. Tuy nhiên, việc triển khai ColBERT gặp rất nhiều khó khăn do sự phức tạp thuật toán (do phải sử dụng phép đo độ tương đồng MaxSim cho toàn bộ vector trong tập hợp) và quá trình tính toán đắt đỏ, phức tạp nên không thể sử dụng được các thuật toán tìm kiếm vector tối ưu như MIPS (Maximum Inner Product Search). MUVERA được ra đời nhằm giải quyết phần nào bài toán đó
MUVERA (Multi-Vector Retrieval Algorithm) là một thuật toán tìm kiếm đột phá mới được Google công bố vào cuối tháng 6/2025, được thiết kế để cải thiện tốc độ và độ chính xác của các hệ thống tìm kiếm, đề xuất, và xử lý ngôn ngữ tự nhiên (NLP). MUVERA biến bài toán tìm kiếm đa vector phức tạp của ColBERT thành bài toán tìm kiểm vector đơn MIPS, giúp cải thiện hiệu suất tìm kiếm multi-vector nhanh gần bằng single-vector search mà vẫn giữ nguyên (hoặc cải thiện độ chính xác).
2. Kiến trúc cốt lõi
Các mô hình “Single-vector” truyền thống nén toàn bộ tài liệu và truy vấn vào cùng một không gian vector duy nhất, điều này làm “loãng” đi thông tin. Các mô hình “Multi-vector” giải quyết vấn đề này bằng Token-level embeddings, trong đó mỗi token trong tài liệu hay câu truy vấn được ánh xạ thành một vector riêng biệt, sau đó thực hiện phép tính Chamber (hay MaxSim) cho toàn bộ các vector của câu truy vấn so với tài liệu. Cách giải quyết này tuy giải quyết được vấn đề hao hụt thông tin tuy nhiên lại gây ra trường hợp tốn tài nguyên và chậm hơn so với single-vector
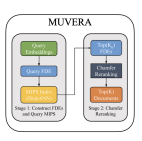
MUVERA giải quyết vấn đề này bằng quy trình hai giai đoạn: Mã hóa kích thước cố định Fixed Dimensional Embedding (FDE) (offline) và Truy hồi 2 giai đoạn (online)
2.1. Fixed Dimensional Embedding (FDE)
MUVERA chuyển đổi tập hợp đa vector của truy vấn (Q) và tài liệu (P) thành các vector đơn và có kích thước cố định .
- MUVERA nén toàn bộ vector nhúng của tài liệu/truy vấn thành các vector đại diện đơn duy nhất (FDE) có số chiều cố định.
- FDE được tạo ra bằng việc phân cụm không gian bằng SimHash (hoặc k-means). Sử dụng random hyperplanes để partition không gian embedding thành B clusters. Các vector gần nhau có xác suất cao rơi vào cùng cluster
- Với mỗi cluster, nếu cluster của query thì sẽ tính tổng các vector còn nếu là cluster của tài liệu thì sẽ tính centroid của các vector. Sau đấy, áp dụng random linear projection để giảm chiều mỗi block.
- Lặp lại quy trình trên nhiều lần với các random partition khác nhau và nối kết quả để tăng độ chính xác.
- Kết quả là vector FDE có số chiều là ’
2.2 Truy hồi 2 giai đoạn:
Sau khi tạo được vector FDE đại điện cho truy vấn/tài liệu, MUVERA sẽ tiến tới việc truy hồi thông tin qua 2 giai đoạn
- Giai đoạn 1 (Lọc ứng viên): Sử dụng các bộ giải MIPS thông dụng (như DiskANN) để tìm kiếm trên các vector FDE. Tích vô hướng của FDE xấp xỉ gần đúng độ tương đồng Chamfer gốc.
- Giai đoạn 2 (Tái xếp hạng): Sử dụng độ tương đồng Chamfer chính xác để xếp hạng lại một nhóm nhỏ các ứng viên hàng đầu từ giai đoạn 1.
3. Kết quả thực nghiệm
Theo kết quả nghiên cứu được công bố trong bài báo https://arxiv.org/pdf/2405.19504
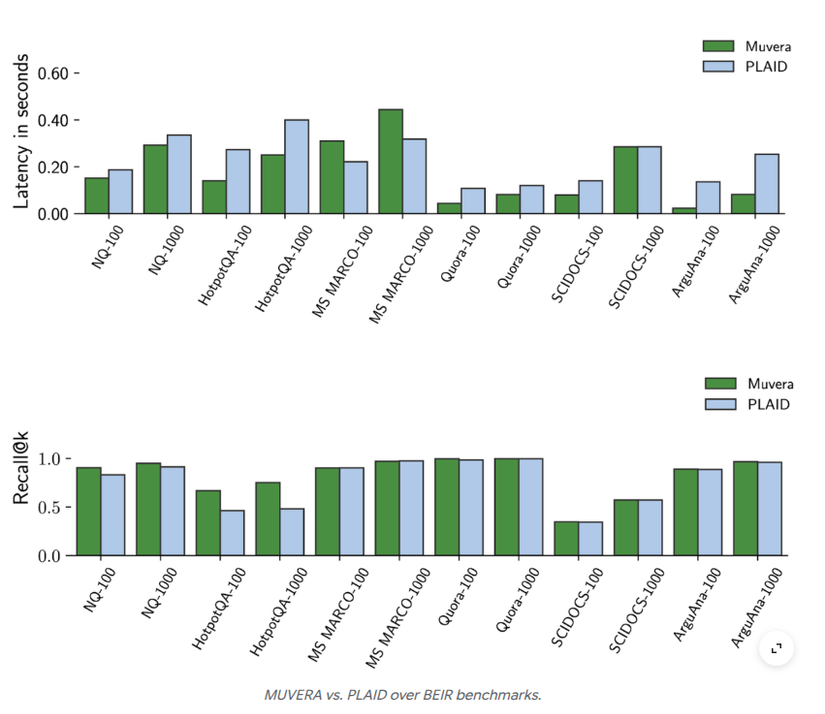
MUVERA được đánh giá trên một số tập dữ liệu thông tin truy hồi từ BEIR benchmarks. Kết quả cho thấy MUVERA đạt được khả năng truy hồi chính xác cao trong khi độ trễ giảm rõ rệt so với một vài phương pháp SOTA như PLAID (của ColBERT).
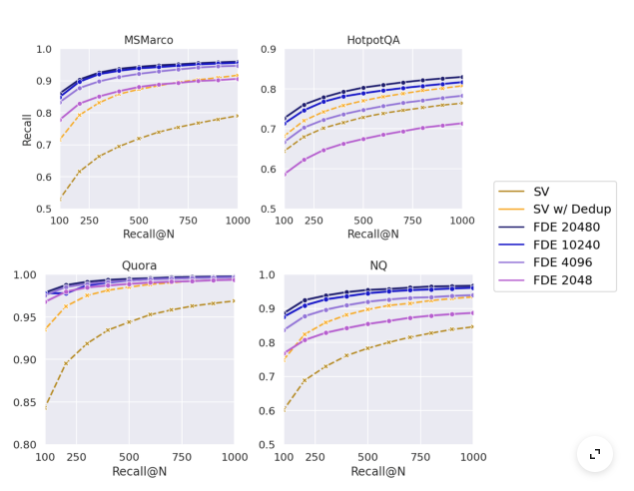
MUVERA thể hiện sự vượt trội so với phương pháp truy vấn single-vector heuristic (được sử dụng bởi PLAID). MUVERA chỉ cần trích xuất số lượng ứng viên sơ bộ ít hơn từ 2 đến 5 lần so với kỹ thuật SV heuristic của PLAID mà vẫn đảm bảo được mức recall tương đương (hình bên trên)
Bên cạnh đó, MUVERA cho thấy rằng so với PLAID - hệ thống truy xuất đa vectơ được tối ưu hóa cao dựa trên thuật toán vectơ đơn, MUVERA tốt hơn 10% ở khả năng recall trong khi giảm 90%^ độ trễ trên bộ dataset BEIR (hình bên dưới). FDE vượt trội hơn Single-Vector Heuristic (cơ sở của PLAID) ở khả năng recall khi quét cùng số floats.
Ngoài ra, MUVERA cũng có thể cải thiện bằng phương pháp nén product quantization - giảm chiều vector nhúng, giúp cải thiện 32x về mặt bộ nhớ tiêu thụ trong khi vẫn giữ nguyên khả năng truy xuất.
4. Kết luận
MUVERA là bước tiến quan trọng, biến multi-vector retrieval thành vấn đề gần như single-vector, đồng thời giữ được chất lượng vượt trội. Đây là giải pháp cân bằng hoàn hảo giữa hiệu suất và độ chính xác, rất phù hợp cho các hệ thống retrieval quy mô lớn. Với việc triển khai đơn giản, hiệu suất vượt trội và không cần tinh chỉnh phức tạp, MUVERA mở ra hướng đi mới cực kỳ thực tiễn cho hệ thống công cụ tìm kiếm và mô hình ngôn ngữ quy mô lớn trong tương lai
All Rights Reserved
