Một số khái niệm cơ bản trong bài toán xử lý âm thanh sử dụng Deep learning (Phần 1)
Âm thanh là gì?
Nếu học các kiến thức môn Vật lý cấp 2, cấp 3 hẳn các bạn đều biết rõ bản chất âm thanh là gì  Âm thanh là tín hiệu được tạo ra bởi sự biến đổi của áp suất không khí. Những biến đổi này có thể được đo lường và biểu đồ hóa theo thời gian. Khi chúng ta đo cường độ của các biến đổi áp suất và vẽ các số đo này theo thời gian, chúng ta có thể thấy các tín hiệu âm thanh.
Âm thanh là tín hiệu được tạo ra bởi sự biến đổi của áp suất không khí. Những biến đổi này có thể được đo lường và biểu đồ hóa theo thời gian. Khi chúng ta đo cường độ của các biến đổi áp suất và vẽ các số đo này theo thời gian, chúng ta có thể thấy các tín hiệu âm thanh.
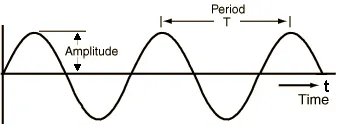
Âm thanh có 1 số đặc tính cơ bản sau:
- Biên độ (Amplitude): Đây là chiều cao của sóng âm, biểu thị cường độ của âm thanh. Biên độ lớn hơn tương ứng với âm thanh lớn hơn.
- Chu kỳ (Period): Là khoảng thời gian để tín hiệu hoàn thành một chu kỳ sóng đầy đủ.
- Tần số (Frequency): Là số chu kỳ sóng hoàn thành trong một giây. Tần số được đo bằng đơn vị Hertz (Hz) và là nghịch đảo của chu kỳ. Ví dụ, nếu một sóng hoàn thành một chu kỳ trong 1/100 giây, tần số của nó sẽ là 100 Hz.
Hầu hết các âm thanh chúng ta nghe thấy không tuân theo các mẫu chu kỳ đơn giản và đều đặn như trên. Các tín hiệu có tần số khác nhau có thể được kết hợp lại để tạo ra các tín hiệu phức tạp hơn với các mẫu lặp phức tạp. Tất cả các âm thanh mà chúng ta nghe, bao gồm cả giọng nói con người, đều bao gồm các dạng sóng phức tạp này.
Tai người có khả năng phân biệt giữa các âm thanh khác nhau dựa trên "chất lượng" của âm thanh, còn được gọi là timbre (âm sắc). Timbre là yếu tố giúp chúng ta nhận ra sự khác biệt giữa các nguồn âm thanh khác nhau, chẳng hạn như giữa các nhạc cụ hoặc giọng nói của những người khác nhau.
Nên biểu diễn âm thanh dưới dạng số như thế nào?
Để số hóa một âm thanh, chúng ta cần biến nó thành một dãy số để có thể model có thể xử lý. Điều này được thực hiện bằng cách đo biên độ của âm thanh tại những khoảng thời gian đều đặn. Mỗi lần đo này được gọi là một mẫu (sample), và tần số lấy mẫu là số lượng mẫu được lấy trong một giây. Ví dụ, một tần số lấy mẫu phổ biến là 44.=100 mẫu mỗi giây, có nghĩa là một đoạn nhạc dài 10 giây sẽ có 441000 mẫu.
Trước đây, khi Deep learning chưa phát triển, các ứng dụng máy học trong Computer Vision và xử lý ngôn ngữ tự nhiên (NLP) sử dụng các kỹ thuật truyền thống để trích xuất đặc trưng. Trong Computer Vision, chúng ta sử dụng các thuật toán để phát hiện góc, cạnh và khuôn mặt. Với NLP, chúng ta trích xuất N-gram và tính tần số xuất hiện của từ.
Tương tự, các ứng dụng machine learning trong audio cũng dựa vào các kỹ thuật xử lý tín hiệu số truyền thống để trích xuất đặc trưng. Ví dụ, để hiểu giọng nói của con người, các tín hiệu âm thanh được phân tích sử dụng các khái niệm như ngữ âm, âm vị,... Tất cả những điều này đòi hỏi rất nhiều kiến thức chuyên môn để giải quyết vấn đề và tối ưu hóa hệ thống
Hãy tưởng tượng bạn có một đoạn ghi âm giọng nói. Trước đây, bạn sẽ cần một chuyên gia ngữ âm để phân tích đoạn ghi âm và trích xuất các đặc trưng như âm vị, giúp máy tính hiểu được đoạn nói. Đây là một công việc phức tạp và tốn thời gian. Nhưng hiện nay, với sự phát triển của Deep learning, chúng ta có thể xử lý âm thanh một cách dễ dàng hơn. Thay vì phân tích từng đặc trưng âm thanh một cách thủ công, chúng ta có thể chuyển đổi âm thanh thành hình ảnh spectrogram. Một spectrogram là một hình ảnh hiển thị cường độ của các tần số âm thanh theo thời gian. Bạn có thể hình dung spectrogram như một bức ảnh nhiệt của âm thanh, trong đó các màu sắc khác nhau thể hiện cường độ của các tần số.
Khi đã có spectrogram, chúng ta có thể sử dụng các mô hình CNN để xử lý hình ảnh spectrogram này, giống như cách chúng ta xử lý hình ảnh. Điều này giúp mô hình deep learning nhận diện và phân tích âm thanh mà không cần sự can thiệp và kiến thức chuyên môn sâu rộng như trước.
Với Deep learning, việc chuẩn bị và xử lý âm thanh trở nên đơn giản hơn nhiều. Thay vì cần nhiều kiến thức chuyên môn và các bước xử lý phức tạp, chúng ta có thể dựa vào các phương pháp chuẩn hóa và sử dụng sức mạnh của mô hình deep learning để xử lý và phân tích âm thanh hiệu quả.
Các thành phần cơ bản trong audio
Spectrum
Như mình đã đề cập ở phần trước, các tín hiệu của các tần số khác nhau có thể được kết hợp lại để tạo ra các tín hiệu tổng hợp, đại diện cho mọi âm thanh trong thế giới thực. Điều này có nghĩa là bất kỳ tín hiệu nào cũng bao gồm nhiều tần số riêng biệt và có thể được biểu diễn như là tổng của các tần số đó.
Spectrum là tập hợp các tần số được kết hợp lại để tạo ra một tín hiệu. Ví dụ, hình ảnh phổ dưới đây cho thấy spectrum của một đoạn nhạc. Spectrum hiển thị tất cả các tần số có trong tín hiệu cùng với cường độ của mỗi tần số.
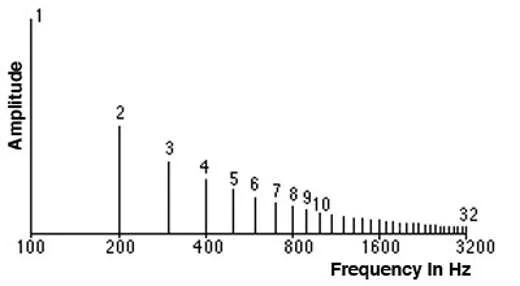
Hãy tưởng tượng bạn nghe một đoạn nhạc. Âm thanh bạn nghe thấy thực chất là sự kết hợp của nhiều tần số khác nhau. Mỗi tần số này đóng góp một phần vào âm thanh tổng thể. Spectrum sẽ cho bạn biết những tần số nào đang có mặt trong âm thanh đó và cường độ của từng tần số.
Tần số thấp nhất trong một tín hiệu được gọi là tần số cơ bản (fundamental frequency). Các tần số là bội số nguyên của tần số cơ bản được gọi là các hài âm (harmonics). Ví dụ, nếu tần số cơ bản là 200 Hz, thì các tần số hài của nó sẽ là 400 Hz, 600 Hz,...
Giả sử bạn đang nghe một nốt nhạc đơn giản được phát ra từ một nhạc cụ. Nốt nhạc này có tần số cơ bản là 200 Hz. Điều này có nghĩa là tần số 200 Hz là tần số thấp nhất có mặt trong nốt nhạc này. Ngoài tần số cơ bản này, nốt nhạc cũng có thể chứa các hài âm với tần số là 400 Hz, 600 Hz, 800 Hz, và tiếp tục tăng lên. Các hài âm này là các bội số nguyên của tần số cơ bản và chúng làm cho âm thanh của nốt nhạc trở nên phong phú và phức tạp hơn.
Time Domain và Frequency Domain
Waveform của audio hiển thị biên độ theo thời gian, đây là một cách để biểu diễn tín hiệu âm thanh. Trong biểu đồ này, trục x hiển thị khoảng thời gian của tín hiệu, vì vậy chúng ta đang xem tín hiệu trong Time Domain (miền thời gian).
Spectrum là một cách khác để biểu diễn cùng một tín hiệu. Thay vì hiển thị biên độ theo thời gian, spectrum hiển thị biên độ theo tần số. Trong biểu đồ spectrum, trục x hiển thị khoảng giá trị tần số của tín hiệu tại một thời điểm cụ thể. Vì vậy, chúng ta đang xem tín hiệu trong Frequency Domain (miền tần số).
Giả sử bạn đang nghe một đoạn ghi âm giọng nói. Khi nhìn vào biểu đồ trong Time Domain, bạn sẽ thấy biên độ của tín hiệu âm thanh thay đổi theo thời gian. Điều này cho bạn biết mức độ to hay nhỏ của âm thanh tại mỗi thời điểm, nhưng không cho bạn biết tần số nào đang có mặt.
Nếu bạn nhìn vào cùng đoạn ghi âm đó trong Frequency Domain, bạn sẽ thấy một biểu đồ hiển thị biên độ của các tần số khác nhau có trong tín hiệu tại một thời điểm cụ thể. Điều này cho bạn biết các tần số nào đang có mặt và cường độ của từng tần số.
Biểu đồ trong Time Domain rất hữu ích để xem cách âm thanh thay đổi theo thời gian. Nó cho chúng ta biết mức độ âm thanh tại mỗi thời điểm và giúp chúng ta nhận diện các thay đổi trong âm thanh, như khi một nhạc cụ bắt đầu hoặc dừng chơi.
Biểu đồ trong Frequency Domain lại rất hữu ích để hiểu thành phần của âm thanh. Nó cho chúng ta biết các tần số nào đang có mặt trong âm thanh và cường độ của từng tần số. Điều này rất quan trọng trong nhiều ứng dụng, chẳng hạn như phân tích nhạc, nhận diện giọng nói, và kỹ thuật âm thanh.
Bằng cách kết hợp cả hai loại biểu đồ này, chúng ta có thể có được một cái nhìn toàn diện về tín hiệu âm thanh, từ cách nó thay đổi theo thời gian đến thành phần tần số của nó. Điều này giúp chúng ta hiểu rõ hơn về âm thanh và cách nó được tạo ra, xử lý và nhận diện.
Spectrograms
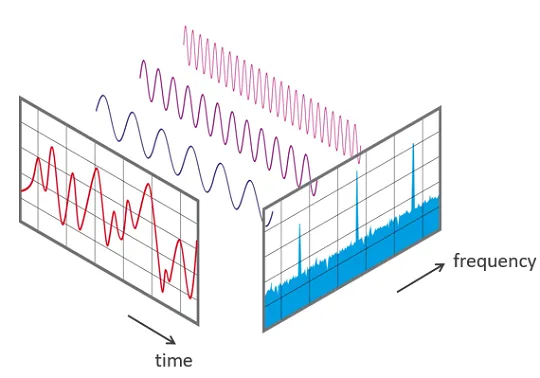
Khi tín hiệu thay đổi theo thời gian, các tần số cấu thành của nó cũng thay đổi theo thời gian. Nói cách khác, spectrum của tín hiệu cũng thay đổi theo thời gian.
Spectrogram của một tín hiệu biểu diễn spectrum của nó theo thời gian, giống như một “bức ảnh” của tín hiệu. Spectrogram hiển thị thời gian trên trục x và tần số trên trục y. Nó giống như chúng ta chụp spectrum nhiều lần tại các thời điểm khác nhau, sau đó ghép chúng lại thành một biểu đồ duy nhất.
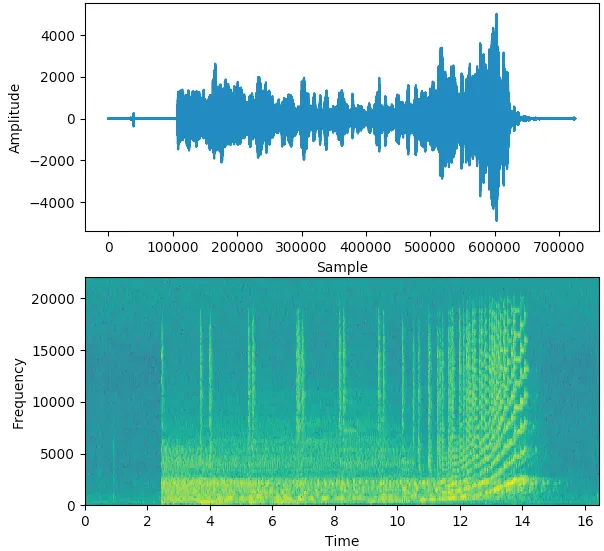
Spectrogram sử dụng các màu sắc khác nhau để biểu diễn cường độ của mỗi tần số. Màu càng sáng, năng lượng của tín hiệu càng cao. Mỗi "lát" dọc của spectrogram thực chất là spectrum của tín hiệu tại thời điểm đó và cho thấy cách phân bố cường độ tín hiệu trong mỗi tần số tại thời điểm đó.
Giả sử bạn có một đoạn ghi âm. Hình ảnh đầu tiên hiển thị tín hiệu trong Time Domain, tức là biên độ theo thời gian. Nó cho chúng ta biết mức độ âm thanh to hay nhỏ tại bất kỳ thời điểm nào, nhưng không cung cấp nhiều thông tin về tần số nào đang có mặt.
Hình ảnh thứ hai là Spectrogram và hiển thị tín hiệu trong Frequency Domain. Nó cho thấy cách các tần số trong tín hiệu thay đổi theo thời gian và cường độ của từng tần số.
Ví dụ, nếu đoạn ghi âm có một nốt nhạc với tần số cơ bản là 200 Hz, cùng với các hài âm ở 400 Hz, 600 Hz, v.v., bạn sẽ thấy các đường sáng tại các tần số này trên spectrogram. Nếu năng lượng của nốt nhạc tăng lên, màu sắc trên spectrogram sẽ trở nên sáng hơn, biểu thị rằng tín hiệu mạnh hơn tại những tần số đó.
Spectrogram là một công cụ mạnh mẽ giúp chúng ta hiểu rõ hơn về tín hiệu âm thanh. Bằng cách xem xét spectrogram, chúng ta có thể thấy cách các tần số trong tín hiệu thay đổi theo thời gian và cường độ của từng tần số. Điều này rất hữu ích trong nhiều lĩnh vực, từ phân tích nhạc, nhận diện giọng nói đến kỹ thuật âm thanh và nghiên cứu khoa học về âm thanh.
All rights reserved
