[LLM] Sử dụng RAGAs và LlamaIndex để đánh giá chất lượng RAG
Giới thiệu
Nếu bạn đã phát triển một ứng dụng Retrieval Augmented Generation (RAG) cho hệ thống kinh doanh thực tế, bạn có thể quan tâm đến hiệu quả của nó. Nói cách khác, bạn muốn đánh giá xem RAG hoạt động tốt như thế nào.
Hơn nữa, nếu bạn nhận thấy rằng RAG hiện tại của mình chưa đủ hiệu quả, bạn có thể cần kiểm tra tính hiệu quả của các phương pháp cải tiến RAG mới. Điều này đồng nghĩa với việc bạn cần thực hiện một quá trình đánh giá để xem những phương pháp cải tiến này có thực sự hiệu quả hay không.
Trong bài viết này, chúng ta đầu tiên sẽ tìm hiểu các tiêu chí đánh giá cho RAG được đề xuất bởi RAGAs (Retrieval Augmented Generation Assessment), một framework để đánh giá các pipeline của RAG. Sau đó, ta sẽ tìm hiểu cách triển khai toàn bộ quá trình đánh giá này sử dụng RAGAs cùng với LlamaIndex.
Metrics để đánh giá RAG
Trong quá trình triển khai Retrieval Augmented Generation (RAG), có ba thành phần chính: truy vấn đầu vào, ngữ cảnh được truy xuất và phản hồi do LLM (Large Language Model) tạo ra. Ba yếu tố này tạo thành bộ ba quan trọng nhất trong quá trình RAG và có sự phụ thuộc lẫn nhau.
Do đó, hiệu quả của RAG có thể được đánh giá bằng cách đo lường độ liên quan giữa ba yếu tố này, như được minh họa trong hình dưới đây.
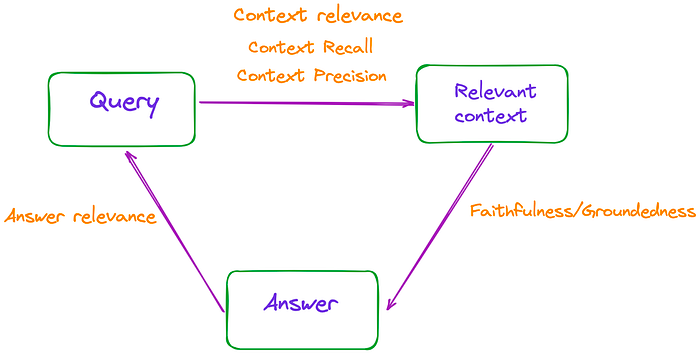
Bài viết đề cập đến ba tiêu chí đánh giá: Faithfulness (Độ trung thực), Answer Relevance (Độ phù hợp của câu trả lời) và Context Relevance (Độ liên quan của ngữ cảnh). Các tiêu chí này không yêu cầu truy cập vào dữ liệu được gán nhãn bởi con người hoặc các câu trả lời tham chiếu.
Ngoài ra, trang web RAGAs cung cấp thêm hai tiêu chí: Context Precision (Độ chính xác của ngữ cảnh) và Context Recall (Độ phủ của ngữ cảnh).
Faithfulness/Groundedness (Độ trung thực)
Faithfulness đề cập đến việc đảm bảo rằng câu trả lời phải dựa trên ngữ cảnh đã được truy xuất. Điều này là quan trọng để tránh những vấn đề về hallucination và đảm bảo rằng ngữ cảnh truy xuất được sử dụng làm căn cứ để tạo câu trả lời. Nếu điểm số này thấp, điều đó cho thấy phản hồi của LLM không tuân theo kiến thức đã truy xuất, và khả năng cung cấp các câu trả lời ảo giác tăng lên 
Ví dụ:
Câu hỏi: Where and when was Einstein born?
Ngữ cảnh: Albert Einstein (born 14 March 1879) was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time.
Câu trả lời độ trung thực cao: Einstein was born in Germany on 14th March 1879.
vs
Câu trả lời độ trung thực thấp: Einstein was born in Germany on 20th March 1879.
Để tính toán độ trung thực, trước tiên chúng ta sử dụng LLM để trích xuất một tập hợp các câu phát biểu (statements) từ câu trả lời. Phương pháp này sử dụng prompt sau:
Given a question and answer, create one or more statements from each sentence in the given answer. question: [question] answer: [answer]
Sau khi tạo ra , LLM sẽ xác định xem mỗi câu phát biểu có thể được suy ra từ hay không. Bước xác minh này được thực hiện bằng cách sử dụng prompt sau:
Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explanation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format. statement: [statement 1] ... statement: [statement n]
Điểm số cuối cùng của độ trung thực , được tính bằng công thức , trong đó đại diện cho số câu phát biểu được tạo ra theo LLM, và đại diện cho tổng số câu phát biểu.
Answer Relevance
Tiêu chí này đo lường mức độ liên quan hay phù hợp giữa câu trả lời được tạo và truy vấn. Điểm số cao hơn cho thấy mức độ phù hợp tốt hơn.
Ví dụ:
Câu hỏi: Where is France and what is its capital?
Câu trả lời độ phù hợp thấp: France is in western Europe.
Câu trả lời độ phù hợp cao: France is in western Europe and Paris is its capital.
Để ước tính độ phù hợp của câu trả lời, chúng ta prompt LLM tạo ra câu hỏi tiềm năng dựa trên câu trả lời đã cho , với prompt sau:
Generate a question for the given answer. answer: [answer]
Sau đó, chúng ta sử dụng mô hình embedding văn bản để lấy các embeddings cho tất cả các câu hỏi.
Đối với mỗi , chúng ta tính toán độ tương đồng so với câu hỏi gốc . Điều này tương ứng với độ tương đồng cosine giữa các nhúng. Điểm số độ phù hợp câu trả lời cho câu hỏi được tính bằng công thức sau:
Qua các tiêu chí này, chúng ta có thể đánh giá hiệu quả của hệ thống RAG một cách chi tiết và có căn cứ hơn.
Context Relevance
Đây là một chỉ số dùng để đo lường chất lượng truy xuất, đặc biệt đánh giá mức độ mà bối cảnh được truy xuất hỗ trợ truy vấn. Điểm số thấp cho thấy có một lượng lớn nội dung không liên quan được truy xuất, điều này có thể ảnh hưởng đến câu trả lời cuối cùng được tạo ra bởi mô hình ngôn ngữ lớn (LLM). Ví dụ:
Câu hỏi: Thủ đô của Pháp là gì?
Độ liên quan bối cảnh cao: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower._
Độ liên quan bối cảnh thấp: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history._
Để ước tính độ liên quan của bối cảnh, một tập hợp các câu chính được trích xuất từ bối cảnh bằng cách sử dụng mô hình ngôn ngữ lớn (LLM). Đây là những câu này rất quan trọng dùng để trả lời câu hỏi. Prompt như sau:
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you're not allowed to make any changes to sentences from given context.
Trong hệ thống RAGAs, độ liên quan được tính ở mức câu bằng công thức sau:
Trong đó:
- CR là chỉ số độ liên quan (Context Relevance)
- Số lượng câu được trích xuất là các câu trong
- Tổng số câu trong bối cảnh là tất cả các câu trong đoạn văn cung cấp.
Việc đánh giá chính xác độ liên quan của bối cảnh là rất quan trọng để đảm bảo rằng các câu trả lời từ mô hình ngôn ngữ lớn có tính chính xác và chất lượng cao.
Context Recall
Độ gọi bối cảnh (Context Recall) là một chỉ số dùng để đo lường mức độ nhất quán giữa bối cảnh được truy xuất và câu trả lời đã được gán nhãn. Context Recall có giá trị càng lớn đồng nghĩa với performance càng tốt. Chỉ số này được tính toán dựa trên dữ liệu thực tế và bối cảnh được truy xuất. Ví dụ:
Ví dụ
Câu hỏi: Nước Pháp ở đâu và thủ đô của nó là gì?
Dữ liệu thực tế: France is in Western Europe and its capital is Paris.
Context Recall cao: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.
Context Recall thấp: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.
Phương pháp đánh giá Context Recall
Khi triển khai, cần cung cấp dữ liệu thực tế. Công thức tính chỉ số Context Recall như sau:
Context Precision
Context Precision là một chỉ số có khá phức tạp, dùng để đo lường xem tất cả các bối cảnh liên quan chứa dữ liệu đúng có được xếp hạng trên đầu hay không. Điểm số cao hơn chỉ ra độ chính xác cao hơn. Công thức tính chỉ số này như sau:
Ưu điểm của Context Precision là khả năng nhận biết xếp hạng của các context được truy xuất. Tuy nhiên, nhược điểm của nó là nếu có rất ít context chính xác được gọi, nhưng xếp hạng cao, thì điểm số cũng sẽ cao. Do đó, cần cân nhắc tổng thể bằng cách kết hợp thêm các chỉ số khác.
Sử dụng RAGAs + LlamaIndex để đánh giá RAG
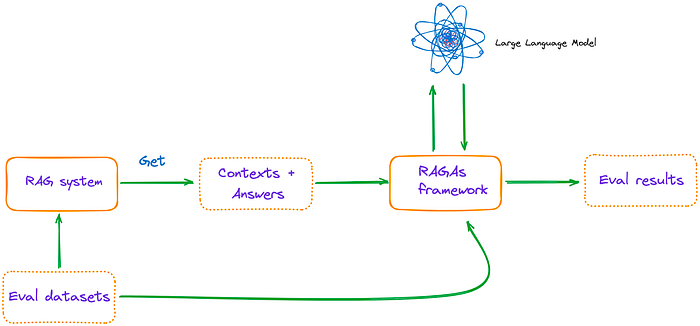
Đầu tiên, ta cần cài đặt ragas bằng câu lệnh pip install ragas
Sau đó, chúng ta cần nhập các thư viện liên quan và thiết lập các biến môi trường cũng như biến toàn cục.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision
)
from ragas.llama_index import evaluate
import os
Thiết lập biến môi trường cho API key và biến toàn cục cho đường dẫn thư mục:
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
dir_path = "YOUR_DIR_PATH"
Trong thư mục chỉ có duy nhất một tệp PDF, đó là bài báo "TinyLlama: An Open-Source Small Language Model".
Để xây dựng một hệ thống truy vấn RAG (Retrieval-Augmented Generation) đơn giản bằng LlamaIndex, chúng ta thực hiện các bước sau:
Tạo hệ thống truy vấn RAG
Sử dụng SimpleDirectoryReader để đọc dữ liệu từ thư mục chứa các tài liệu và tạo một VectorStoreIndex từ những tài liệu đã được đọc.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Đường dẫn tới thư mục chứa tài liệu
dir_path = "YOUR_DIR_PATH"
# Đọc dữ liệu từ thư mục
documents = SimpleDirectoryReader(dir_path).load_data()
# Tạo VectorStoreIndex từ tài liệu
index = VectorStoreIndex.from_documents(documents)
# Tạo hệ thống truy vấn từ index
query_engine = index.as_query_engine()
Thiết lập biến môi trường và cấu hình model
import os
# Đặt API key cho OpenAI
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
# Mặc định, mô hình OpenAI được sử dụng trong LlamaIndex. Bạn có thể cấu hình lại sử dụng ServiceContext nếu cần.
Tạo tập dữ liệu để đánh giá
Chúng ta sẽ viết một số câu hỏi và câu trả lời tương ứng để tạo tập dữ liệu đánh giá.
eval_questions = [
"Can you provide a concise description of the TinyLlama model?",
"I would like to know the speed optimizations that TinyLlama has made.",
"Why TinyLlama uses Grouped-query Attention?",
"Is the TinyLlama model open source?",
"Tell me about starcoderdata dataset",
]
eval_answers = [
"TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.",
"During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.",
"To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance",
"Yes, TinyLlama is open-source",
"This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.",
]
eval_answers = [[a] for a in eval_answers]
Lựa chọn các metric và thực hiện đánh giá
Chúng ta lựa chọn các metrics như faithfulness, answer relevancy, context relevancy, context recall và context precision để thực hiện đánh giá hệ thống.
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision
)
from ragas.llama_index import evaluate
metrics = [
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision,
]
# Thực hiện đánh giá
result = evaluate(query_engine, metrics, eval_questions, eval_answers)
# Xuất kết quả ra file CSV
result.to_pandas().to_csv('YOUR_CSV_PATH', sep=',')
Kết quả đánh giá

Từ bảng kết quả hiển thị trong ảnh trên, một số kết luận có thể được rút ra:
- Câu hỏi thứ 4, "Tell me about starcoderdata dataset", có tất cả các giá trị là 0 vì LLM không cung cấp được câu trả lời.
- Câu hỏi thứ 2 và thứ 3 có độ chính xác ngữ cảnh là 0, cho thấy các ngữ cảnh liên quan không được xếp hạng cao.
- Context recall cho câu hỏi thứ hai là 0, cho thấy các context recall không trùng khớp với câu trả lời đã được gán nhãn.
- Các câu hỏi từ 0 đến 3 có điểm số liên quan đến câu trả lời cao, cho thấy sự tương quan mạnh mẽ giữa các câu trả lời và câu hỏi.
- Faithfulness không thấp, cho thấy các câu trả lời được rút ra hoặc tóm tắt từ ngữ cảnh, ít có khả năng mô hình LLM bị hallucination.
Hệ thống RAG cơ bản này còn nhiều điều kiện cải thiện để đạt kết quả tốt hơn. Tuy nhiên, từ các kết quả đã có, chúng ta có thể thấy rằng mô hình gpt-3.5-turbo-16k (mô hình mặc định của RAGAs) vẫn có khả năng suy luận câu trả lời từ ngữ cảnh mặc dù điểm số tương thích ngữ cảnh thấp.
All rights reserved
