[LLM - Paper reading] RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Giới thiệu
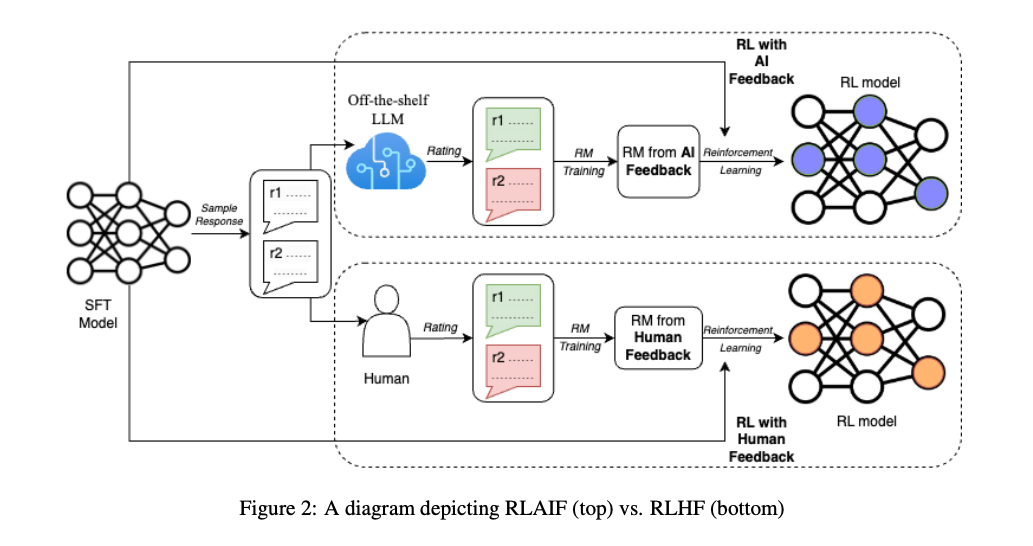
Các bạn đều biết rằng Reinforcement Learning from Human Feedback (RLHF) là một phương pháp hiệu quả để align các mô hình ngôn ngữ lớn (LLMs) theo preference của con người, đóng vai trò quan trọng trong sự phát triển của các mô hình hội thoại hiện đại như ChatGPT và Bard  Tuy nhiên, RLHF yêu cầu rất nhiều thời gian và chi phí do cần nhãn chất lượng cao được gán bởi con người.
Tuy nhiên, RLHF yêu cầu rất nhiều thời gian và chi phí do cần nhãn chất lượng cao được gán bởi con người.
Phương pháp Reinforcement Learning from AI Feedback (RLAIF) được giới thiệu trong bài báo là một phương pháp thay thế đầy tiềm năng cho RLHF RLAIF sử dụng LLMs để tạo ra các nhãn preference, từ đó giảm thiểu sự phụ thuộc vào con người. Nghiên cứu này cho thấy RLAIF đạt hiệu suất tương đương, và thậm chí vượt trội hơn RLHF trong một số task như tóm tắt nội dung, sinh đoạn hội thoại,...
Ngoài ra, RLAIF còn thể hiện sự vượt trội hơn so với model SFT baseline kể cả khi LLM preference labeler có cùng size với policy. Trong một thử nghiệm khác của nhóm tác giả, việc trực tiếp prompting LLM để cung cấp reward scores mang lại hiệu suất cao hơn so với cách thiết lập RLAIF truyền thống.
Qua những lần thử nghiệm, nhóm tác giả chỉ ra rằng RLAIF có thể đạt được hiệu suất ngang tầm với con người, từ đó mở ra một giải pháp tiềm năng cho các hạn chế về khả năng mở rộng của RLHF.
Phương pháp
Gán nhãn preference sử dụng LLM
Chúng ta sẽ sử dụng một model LLM có sẵn để thực hiện gán nhãn preference. Model LLM này cần đảm bảo là một model LLM pretrained hoặc instruction-tuned cho các nhiệm vụ tổng quát (không được finetune cho một downstream task nào). Sau đó, ta sẽ sử dụng model LLM này để chọn ra câu trả lời tốt nhất trong 2 candidates output được tạo ra bởi model policy.
Cụ thể, cho một đoạn văn bản và 2 candidate responses, nhiệm vụ của LLM là chọn response tốt nhất. Prompt được sử dụng cho model LLM này được thể hiện trong hình dưới.

Cấu trúc của prompt bao gồm các thành phần:
- Phần mở đầu (Preamble): Giới thiệu và mô tả nhiệm vụ cần thực hiện
- Ví dụ mẫu (Example), bao gồm các thành phần:
- Input context
- Cặp responses
- Chain of thought
- Preference label
- Sample cần gán nhãn
- Input context
- Cặp responses cần được gán nhãn
- Kết thúc: Một đoạn text để yêu cầu LLM đưa ra câu trả lời (ví dụ: "Preferred Response=")
Một ví dụ về cách chọn nhãn preference như sau:
Okay! Vây là ta đã có prompt cho LLM. Sau đó, nhóm tác giả trích xuất các log-probabilities của việc generate các token “1” và “2” (response 1 và response 2). Sau đó, họ sử dụng softmax để tạo ra một preference distribution, thể hiện phân phối xác suất của mỗi responses mà mô hình LLM lựa chọn.
Nhóm tác giả giải thích rằng có nhiều cách để lấy thông tin preference từ LLM. Ví dụ, ta có thể trích xuất preference từ câu trả lời "free-form" của mô hình LLM (ví dụ như “The first response is better”, thay vì để mô hình LLM đưa ra nhãn "1" hoặc "2").
Một cách khác là sử dụng one-hot encoding - một dạng biểu diễn trong đó chỉ có một phần tử duy nhất có giá trị khác không (thường là 1) và tất cả các phần tử khác đều là 0.
Tuy nhiên, nhóm tác giả chọn phương pháp tính softmax vì nó đơn giản và cung cấp nhiều thông tin hơn so với one-hot encoding, nhờ vào việc biểu diễn preference distribution.
Nhóm tác giả cũng thực hiện thử nghiệm với hai kiểu phần mở đầu (preambles) khác nhau:
-
"Base": Đây chỉ là câu hỏi đơn giản
ví dụ như “which response is better?”” -
"Detailed": Đây là các hướng dẫn label chi tiết được đưa cho con người.
Ngoài ra, nhóm tác giả còn thử nghiệm với phương pháp in-context learning. Đây là kỹ thuật trong đó các ví dụ chất lượng cao được chọn lọc thủ công để bao gồm nhiều chủ đề khác nhau. Phương pháp này giúp LLM học từ các context cụ thể để cải thiện chất lượng phản hồi.
Giải quyết vấn đề Position Bias
Giống như con người, chúng ta thường có ấn tượng hơn về những cái gì xuất hiện đầu tiên (ví dụ như tình đầu chẳng hạn ) và mô hình LLM cũng có bias tương tự.
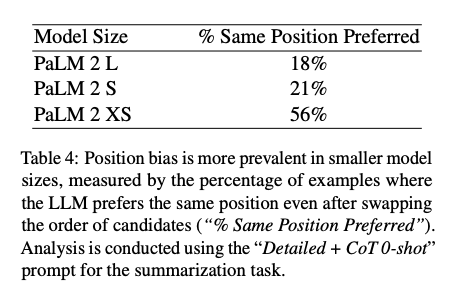
Thứ tự mà các candidate được trình bày cho model LLM có thể làm thay đổi nhãn preference của mô hình đối với từng candidate. Nhóm tác giả nhận thấy hiện tượng về position bias, điều này càng thể hiện rõ ràng hơn khi sử dụng các LLM có kích thước nhỏ.
Để giảm thiểu hiện tượng position bias trong việc gán nhãn preference, nhóm tác giả thực hiện 2 lần inference cho mỗi cặp candidate, trong đó thứ tự trình bày các candidate cho LLM được đảo ngược ở lần inference thứ hai. Kết quả từ cả hai lần suy luận sau đó được tính trung bình để có được preference distribution cuối cùng.
Sử dụng Chain-of-thought
Nhóm tác giả đã tiến hành thí nghiệm với việc sử dụng prompt theo chiến lược chain-of-thought và sử dụng thêm 2 lần inference như mình đã trình bày ở phần trước.
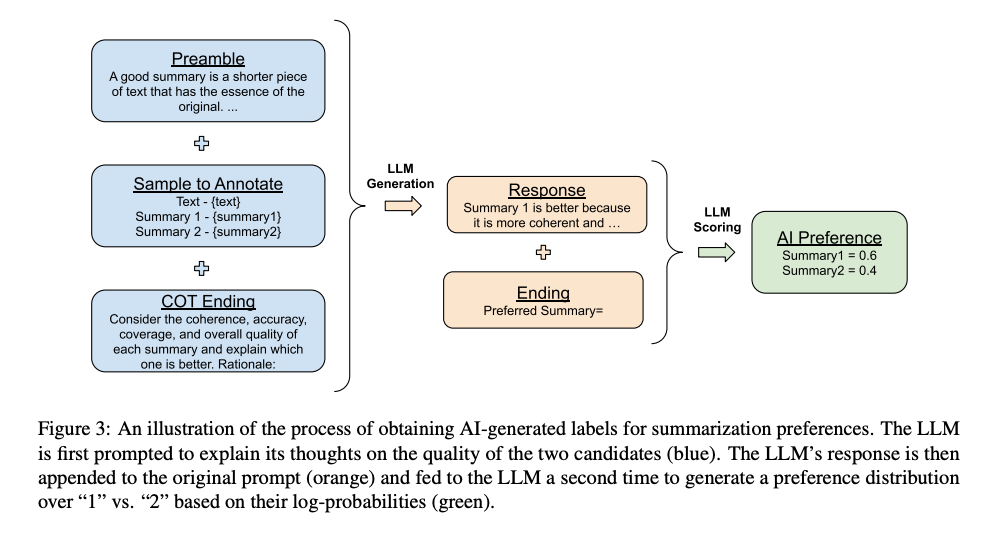
Đầu tiên, nhóm tác giả thay thế phần kết thúc của prompt (ví dụ: "Preferred Summary=") bằng một câu yêu cầu suy nghĩ và giải thích (ví dụ: "Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:") và sau đó decode phản hồi từ model LLM.
Tiếp theo, nhóm tác giả concat prompt ban đầu, response, và phần kết thúc (đã trình bày ở trên) lại với nhau thành 1 prompt mới. Nhóm tác giả sử dụng prompt này cho quá trình inference. Để dễ hiểu hơn, các bạn có thể xem ở hình dưới:
RLAIF
Distilled RLAIF
Sau khi sử dụng một model LLM để gán nhãn preference, một reward model (RM) sẽ được training trên những nhãn này. Vì output của model LLM dùng để gán nhãn preference là các soft labels (ví dụ: , do output là preference distribution) nên nhóm tác giả sử dụng cross-entropy loss lên softmax của các reward scores được sinh ra bởi RM. Softmax chuyển đổi các RM scores thành một phân phối xác suất.
Các bạn có thể thấy rằng việc huấn luyện một RM trên một dataset của AI labels có thể được xem là một hình thức model distilled Cuối cùng, nhóm tác giả tiến hành reinforcement learning để huấn luyện RLAIF policy model, sử dụng RM để gán rewards cho các phản hồi của mô hình.
Direct RLAIF
Một phương pháp thay thế khác là sử dụng trực tiếp feedback từ LLM để làm reward trong RL Phương pháp này sẽ giúp chúng ta bỏ qua giai đoạn trung gian của việc huấn luyện một RM để tiếp cận các preference của LLM.
Đầu tiên, mô hình LLM dùng để gán nhãn sẽ sử dụng prompt để output điểm chất lượng của một generation trong khoảng từ 1 đến 10. Prompt vẫn giữ nguyên cấu trúc mà mình đã trình bày ở phần trước đó.
Sau đó, xác suất của mỗi token score trong khoảng từ 1 tới 10 được tính toán, các xác suất được chuẩn hóa thành một phân phối xác suất, một weighted score được tính theo công thức , và sau đó score lại được chuẩn hóa về phạm vi .
Cuối cùng, RL được thực hiện tương tự như "distilled RLAIF", trong đó score trực tiếp được sử dụng như là reward thay vì score từ RM. Cách tiếp cận này tốn kém hơn về mặt tính toán do AI labeler cần lớn hơn RM.
Phương pháp đánh giá
Nhóm tác đánh giá kết quả sử dụng 3 chỉ số - AI Labeler Alignment, Win Rate, và Harmless Rate. AI Labeler Alignment đo lường độ chính xác của các lựa chọn được gán nhãn bởi AI so với các lựa chọn của con người. Đối với một ví dụ đơn lẻ, soft-label được gán nhãn bởi AI sẽ được chuyển đổi thành dạng nhị phân (ví dụ, ). Sau đó, giá trị 1 được gán nếu nhãn đồng ý với lựa chọn của con người và 0 nếu không đồng ý. Độ chính xác của sự đồng thuận có thể được biểu diễn như sau:
trong đó là kích thước của bộ dữ liệu tùy chọn, là ma trận chứa các soft-label được gán nhãn bởi AI, và là vector tương ứng chứa tùy chọn của con người, với các phần tử là 0 hoặc 1 để đánh dấu tùy chọn giữa phản hồi thứ nhất hoặc thứ hai.
Win Rate đánh giá chất lượng tổng thể của hai policy bằng cách so sánh xem một policy được người gán nhãn hơn bao nhiêu lần so với policy khác. Khi cho input vào model policy và hai kết quả sinh ra, những người gán nhãn sẽ chọn ra kết quả mà họ ưa thích. Tỷ lệ phần trăm các trường hợp mà policy A được ưa thích hơn policy B được gọi là "win rate của A so với B". Tỷ lệ win rate 50% cho thấy rằng A và B được ưa thích ngang nhau.
Harmless Rate đo lường tỷ lệ phần trăm của các phản hồi được xem là không gây hại với những người đánh giá. Điều này có nghĩa là trong quá trình đánh giá, các phản hồi của mô hình sẽ được kiểm tra xem chúng có tiềm ẩn bất kỳ rủi ro hay gây hại nào cho người dùng hay không. Nhóm tác giả chọn sử dụng chỉ số Harmless Rate thay vì Win Rate để đánh giá nhiệm vụ generate hội thoại với nhiều style khác nhau. Lý do sử dụng Harmless Rate là vì các repsonse từ mô hình đều an toàn như nhau, khiến cho việc xếp hạng tương đối trở nên khó khăn.
Một số kết quả
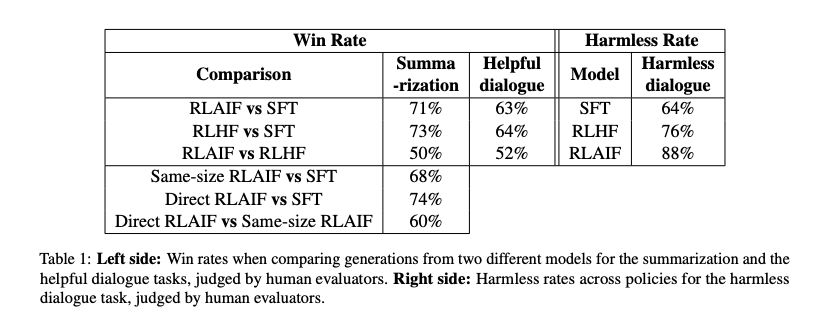
Ta có một số kết quả như sau:
-
RLAIF vs SFT: RLAIF vượt qua SFT với tỷ lệ 71% trong nhiệm vụ tóm tắt văn bản và 63% trong nhiệm vụ helpful diaglogue. -
RLHF vs SFT: RLHF vượt qua SFT với tỷ lệ 73% trong nhiệm vụ tóm tắt văn bản và 64% trong nhiệm vụ helpful diaglogue. -
RLAIF vs RLHF: RLAIF và RLHF ngang ngửa nhau trong nhiệm vụ tóm tắt văn bản với tỷ lệ 50%, và RLAIF có 52% trong nhiệm vụ helpful diaglogue. -
Same-size RLAIF vs SFT: RLAIF cùng kích cỡ vượt qua SFT với tỷ lệ 68% trong nhiệm vụ tóm tắt văn bản. -
Direct RLAIF vs SFT: RLAIF trực tiếp vượt qua SFT với tỷ lệ 74% trong nhiệm vụ tóm tắt văn bản. -
Direct RLAIF vs Same-size RLAIF: RLAIF trực tiếp đánh bại RLAIF cùng kích cỡ với tỷ lệ 60% trong nhiệm vụ tóm tắt văn bản. -
Harmless Rate:
SFT: Đạt 64% phản hồi không gây hại.RLHF: Đạt 76% phản hồi không gây hại.RLAIF: Đạt 88% phản hồi không gây hại.
Tổng kết:
- Win Rate: RLAIF và RLHF thường có tỷ lệ thắng cao hơn so với SFT trong cả hai nhiệm vụ tóm tắt văn bản và helpful dialogue.
- Harmless Rate: RLAIF có tỷ lệ phản hồi không gây hại cao nhất, tiếp đó là RLHF và cuối cùng là SFT.
Kết luận
Như vậy, thông qua paper chúng ta đã có thêm 1 ý tưởng mới để align mô hình LLM, từ đó nâng cao chất lượng của mô hình. Về cơ bản, nếu dùng RLHF đơn thuần thì sẽ rất là tốn "thóc", vì vậy việc sử dụng AI cho công đoạn feedback cũng là 1 ý tưởng hay mà các bạn có thể thử
All rights reserved
