[LLM 101 - Paper reading] SaulLM-7B: A pioneering Large Language Model for Law
Đóng góp của bài báo
Việc áp dụng mô hình ngôn ngữ lớn (LLMs) trong nhiều lĩnh vực như dịch thuật, y tế và sinh code đạt được nhiều thành tựu nổi bật. Tuy nhiên, lĩnh vực pháp lý vẫn chưa tận dụng hết tiềm năng của LLMs. Bài báo giới thiệu SaulLM-7B, LLM dành cho pháp lý đầu tiên được thiết kế để giải quyết những thách thức ngôn ngữ đặc trưng trong văn bản pháp lý. Cách tiếp cận của bài báo tập trung vào việc pretraining mở rộng trên một lượng lớn tài liệu pháp lý từ các khu vực nói tiếng Anh như Hoa Kỳ, Canada, Anh và Châu Âu. Mục tiêu là nhằm đảm bảo mô hình có thể giải thích chính xác và đáp ứng được sự thay đổi của ngôn ngữ pháp lý.
Phương pháp
Bài báo sử dụng mô hình Mistral 7B, một mô hình ngôn ngữ open source với 7 tỷ tham số, được lựa chọn vì hiệu suất cao của nó trên nhiều benchmark và nhiệm vụ.
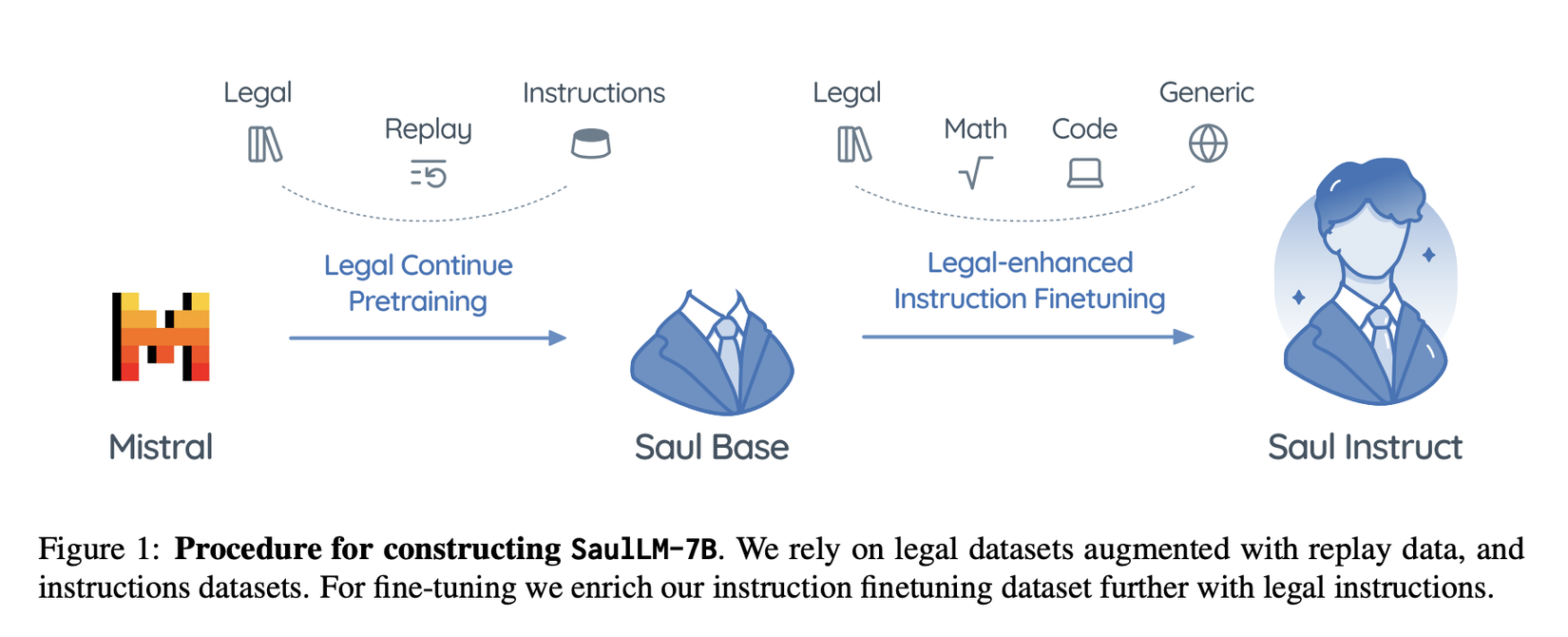
Nâng cao năng lực pháp lý của Mistral
Trong quá trình huấn luyện, các mô hình tổng quát thường chỉ nhận được một lượng hạn chế về dữ liệu pháp lý, chiếm một phần nhỏ trong tổng thể dữ liệu huấn luyện. Để cải thiện hiệu suất của các mô hình này trên các nhiệm vụ liên quan đến lĩnh vực pháp lý, một phương pháp đơn giản nhưng hiệu quả là tiến hành huấn luyện bổ sung với sự tập trung cụ thể vào dữ liệu pháp lý. Phương pháp này được áp dụng thành công trên các mô hình decoder trong nhiều lĩnh vực như y học, dịch thuật và lập trình, thể hiện ưu điểm về khả năng mở rộng và tính độc lập với đặc trưng cụ thể của dữ liệu huấn luyện.
Tuy nhiên, trong lĩnh vực thích ứng miền (domain adaption), nỗ lực chuyên môn hóa các mô hình ngôn ngữ thông qua các nhiệm vụ giả định thường gặp phải các thách thức như chi phí tính toán cao, hoặc hạn chế về khả năng mở rộng. Đối mặt với những thách thức này và dựa vào sự sẵn có của bộ dữ liệu pháp lý quy mô lớn từ web, nhóm tác giả đã cẩn thận lựa chọn và chuẩn bị một bộ dữ liệu chất lượng cao, bao gồm nội dung đa dạng từ các kho dữ liệu pháp lý. Sau quá trình lọc và loại bỏ trùng lặp kỹ lưỡng, họ thu được một bộ dữ liệu gồm 30 tỷ token. Bộ dữ liệu này cung cấp một nền tảng vững chắc cho quá trình continued pretraining, hướng tới việc cải thiện hiệu suất của mô hình trên các nhiệm vụ pháp lý.
Cải thiện việc tuân thủ chỉ dẫn pháp lý
Để hỗ trợ yêu cầu của người dùng và tương tác hội thoại, các LLMs thường trải qua quá trình điều chỉnh hướng dẫn (instruction tuning), một quá trình quan trọng bao gồm việc huấn luyện mô hình trên các cặp hội thoại giám sát (supervised conversational pair). Đối với các mô hình ngôn ngữ đa năng, sự đa dạng và chất lượng của hướng dẫn là rất quan trọng để đảm bảo hiệu quả 
Trong các lĩnh vực chuyên biệt, việc bổ sung các hướng dẫn cụ thể cho nhiệm vụ là cực kỳ quan trọng để nâng cao hiệu suất. Giai đoạn instruction tuning bao gồm hai thành phần chính: hướng dẫn chung (tức là không phải pháp lý) và hướng dẫn pháp lý. Các hướng dẫn chung nhằm mục đích tăng cường khả năng của mô hình trong việc hiểu và tuân theo các lệnh trong các lĩnh vực đa dạng như lập trình, toán học và cuộc trò chuyện chung. Đối với các hướng dẫn pháp lý, nhóm tác giả tập trung vào những chi tiết quan trọng trong ngành pháp luật, như trả lời các câu hỏi về luật và làm rõ các vấn đề phức tạp, cùng với nhiều nhiệm vụ khác.
Quá trình tinh chỉnh này giúp mô hình có tên SaulLM-7B-Instruct nâng cao kiến thức về pháp luật và thực hiện tốt các nhiệm vụ liên quan. Đồng thời, mô hình cũng trở nên linh hoạt và có khả năng chuyên sâu, hiệu quả trong nhiều lĩnh vực khác nhau.
Dữ liệu
Dữ liệu pretraining về pháp lý
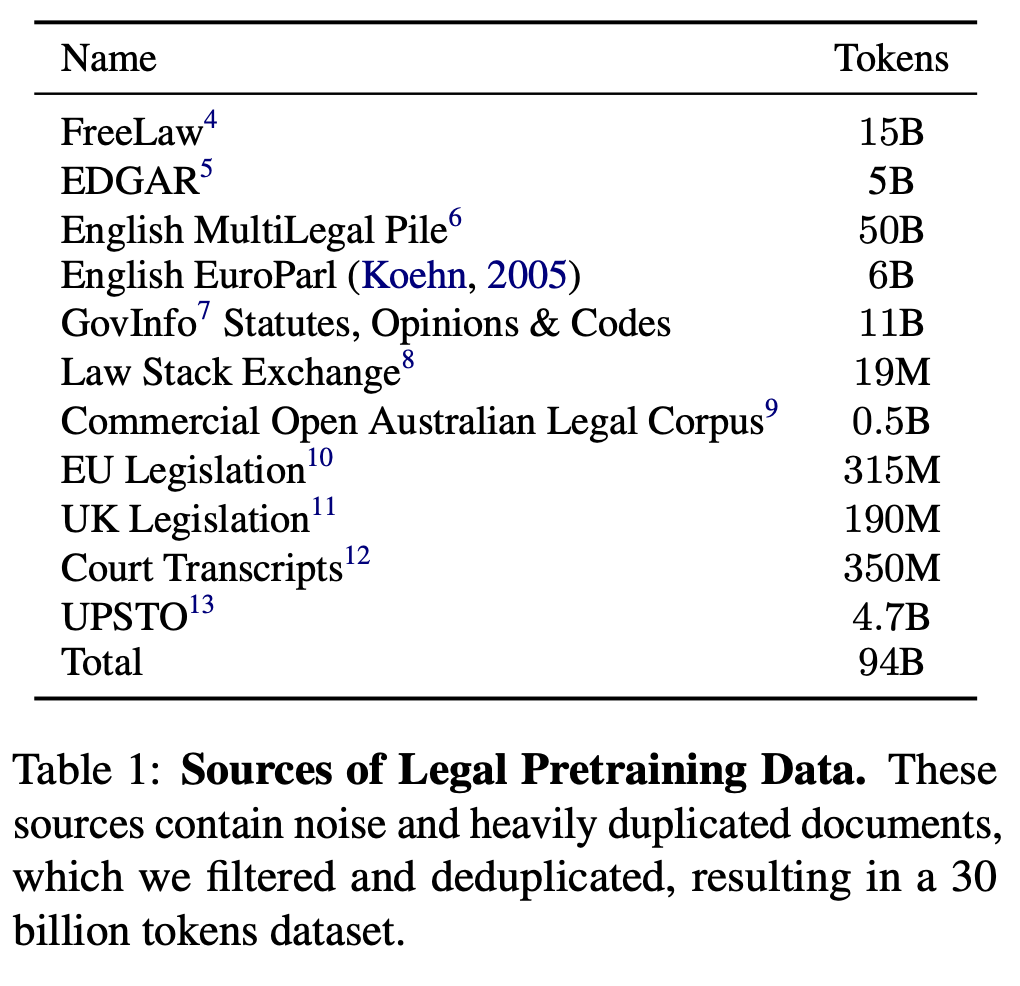
Nhóm tác giả kết hợp các bộ dữ liệu đã có sẵn trước đó như FreeLaw từ The Pile và MultiLegal Pile, cùng với dữ liệu được thu thập từ các nguồn public trên Web.
Để giảm thiểu vấn đề catastrophic forgetting trong quá trình continued pretraining, nhóm tác giả thực hiện sử dụng lại dữ liệu training trước đó. Tuy nhiên, do dữ liệu huấn luyện cho Mistral không được công bố, nhóm tác giả đã sử dụng dữ liệu general phổ biến từ Wikipedia, StackExchange và GitHub, chiếm khoảng 2% tổng số dữ liệu training cuối cùng. Các tập dữ liệu này được sample từ SlimPajama.
Ngoài ra, nhóm tác giả nhận thấy việc bổ sung dữ liệu hội thoại trong quá trình pretraining mang lại nhiều lợi ích. Ý tưởng này đến từ một quan sát rằng các mô hình dịch thuật hoạt động tốt nhờ có những dữ liệu trùng khớp ngẫu nhiên trong bộ dữ liệu training. Nói cách khác, khi bắt đầu training, nhóm tác giả thêm vào hai bộ dữ liệu đặc biệt là Super Natural Instruction và FLAN để nâng cao hiệu suất mô hình.
Trong phần data cleaning, nhóm tác giả xử lý một lượng lớn dữ liệu thu thập được, phần lớn ở dạng file PDF hoặc văn bản được trích xuất từ PDF. Văn bản này chứa một số lỗi như số trang ở giữa câu, số dòng, ký tự Unicode không chuẩn, dòng văn bản bị đứt quãng, ký tự lặp lại như dấu gạch ngang,... Nhóm tác giả đã sử dụng kết hợp các quy tắc và phương pháp thực nghiệm để lọc dữ liệu này.
Chuẩn hóa văn bản: Nhóm tác giả chuẩn hóa tất cả ký tự Unicode bằng phương thức NFKC, sử dụng package unicodedata trong Python.
Lọc theo quy tắc: Nhóm tác giả xác định 10-gram phổ biến nhất trong bộ dữ liệu và sử dụng regular expressions để loại bỏ những phần không mong muốn, chủ yếu là ký tự lặp lại. Chẳng hạn, 8 trong 10 10-gram hàng đầu trong dữ liệu gốc là ký tự lặp lại và các ký tự lạ do lỗi mã hóa. Nhóm tác giả cũng loại bỏ khoảng trắng lặp lại và các thẻ HTML.
Lọc theo độ phức tạp: Nhóm tác giả huấn luyện một mô hình KenLM trên một tập con dữ liệu pháp lý được kiểm tra kỹ lưỡng và sử dụng nó để lọc bất kỳ đoạn văn có độ phức tạp cao. Phương pháp này giúp loại bỏ văn bản không phải tiếng Anh và hầu hết các chuỗi Unicode "lạ" trong dữ liệu.
Loại bỏ trùng lặp: Nhóm tác giả loại bỏ các dữ liệu trùng lặp và gần trùng lặp, sau đó thu được khoảng 30 tỷ token văn bản chất lượng cao.
Qua quá trình này, bộ dữ liệu được tinh chỉnh để chuẩn bị cho quá trình training, đảm bảo chất lượng và độ đa dạng của dữ liệu đầu vào.
Instruction Finetuning Mixes
Quá trình Instruction Finetuning là rất quan trọng để tối ưu hóa hiệu suất của các mô hình decoder đã qua pretraining trên các nhiệm vụ khác nhau. Nhóm tác giả sử dụng kết hợp hướng dẫn chung (General Instructions) và hướng dẫn pháp lý (Legal Instruction) để huấn luyện mô hình hiểu và tuân thủ hướng dẫn một cách hiệu quả, với trọng tâm là kiến thức pháp lý.
Hướng dẫn Chung: Hướng dẫn chung được thu thập từ bốn nguồn chính:
- SlimOrca: Một phần của bộ sưu tập FLAN, bao gồm hướng dẫn chung cho nhiều nhiệm vụ.
- Hướng dẫn Trả lời Câu hỏi Toán Meta: Dành cho việc hỏi đáp về toán học, tập dữ liệu này cung cấp nhiều câu hỏi toán học, hỗ trợ nghiên cứu trong lĩnh vực xử lý ngôn ngữ tự nhiên dựa trên toán.
- Các Cuộc trò chuyện chung từ UltraChat: Chứa các ngữ cảnh hội thoại đa dạng, tập dữ liệu này giúp cải thiện mức độ thông hiểu và tạo sinh ngôn ngữ tự nhiên của mô hình.
- Hướng dẫn Code từ Glaive Code Assistant: Huấn luyện trên code đã được chứng minh là tăng cường khả năng suy luận của mô hình.
Tất cả dữ liệu này đều được lọc kỹ lưỡng, loại bỏ trùng lặp và tổ chức cẩn thận, tạo ra một bộ dữ liệu tinh gọn gồm 600K hướng dẫn.

Xây dựng Hướng dẫn Pháp lý: Nhóm tác giả tạo ra các cuộc trò chuyện toàn diện một cách tổng hợp, tập trung vào các kỹ năng pháp lý cơ bản qua nhiều loại tài liệu pháp lý. Cách tiếp cận này bao gồm việc bắt đầu cuộc trò chuyện với 3 turns được định sẵn: (1) người dùng đưa ra yêu cầu liên quan đến tài liệu pháp lý, (2) trợ lý đáp lại bằng cách tái diễn thông tin (ví dụ: loại tài liệu, ngày, tên của thẩm phán), và (3) người dùng yêu cầu trợ lý giải thích lý do của mình. Sau đó, cuộc trò chuyện được mở rộng qua một loạt turns khác, trong đó người dùng đặt ra các câu hỏi cụ thể hơn để hiểu rõ suy luận của trợ lý. Đồng thời, mô hình trợ lý cung cấp cái nhìn sâu sắc cho người dùng (xem hình trên) Ngoài ra, nhóm tác giả đảm bảo rằng tập test không được lấy từ các benchmark hiện có.
Phương pháp đánh giá
Để đánh giá khả năng pháp lý của mô hình, nhóm tác sử dụng 3 benchmarks: (i) so sánh perplexity của các backbones trên 5 loại tài liệu pháp lý, (ii) phát triển LegalBench thành LegalBench-Instruct để đánh giá được sâu hơn, (iii) dựa vào phần pháp lý trong bộ benchmarks MMLU để có thêm insight khác.
Đo lường Perplexity: Để đánh giá khả năng adapt của các backbones với tài liệu pháp lý, nhóm tác giả đánh giá perplexity sử dụng các benchmark datasets từ 4 lĩnh vực pháp lý riêng biệt: hợp đồng, quyết định tư pháp, văn bản ý kiến, và lập pháp.
Nhóm tác giả đảm bảo rằng các datasets được cập nhật và thu thập sau ngày dữ liệu bị cắt của LLM (tức là sau ngày cuối cùng của thông tin được dùng để train LLM). Cụ thể, dữ liệu hợp đồng được lấy từ EDGAR (quý đầu của 2024), quyết định pháp lý từ các quyết định của tòa ICSID sau tháng 10 năm 2023, lập pháp tập trung vào các dự luật của Mỹ được đệ trình lên Hạ viện hoặc Thượng viện sau tháng 10 năm 2023, và các bài nộp của các bên bao gồm các bản kiến nghị Texas sau tháng 10 năm 2023.
Trong quá trình nghiên cứu, nhóm tác giả phát hiện một hạn chế lớn trong các prompt gốc của LegalBench. Bản chất phức tạp của các prompt này, cùng với những hạn chế của các LLM open source trong việc tuân theo hướng dẫn - đặc biệt là xử lý định dạng - dẫn đến sự sụt giảm đáng kể về hiệu suất (được đo bằng accuracy). Các câu được tạo ra thường dài dòng và khó hiểu, khiến LegalBench ở dạng hiện tại quá nghiêm ngặt và không đo lường chính xác sự cải thiện trong nhiệm vụ.
Ví dụ, trong một số nhiệm vụ, hiệu suất được đánh giá bởi từ đầu tiên mà mô hình dự đoán, và từ này được mong đợi là Yes/No. Điều này có nghĩa là nếu câu trả lời hơi dài dòng thì sẽ được coi là không chính xác, ngay cả khi một người sẽ phân loại nó là câu trả lời đúng. Để khắc phục nhược điểm này, nhóm tác giả tinh chỉnh các prompt bằng cách 1) loại bỏ các ví dụ few-shot gây nhiễu và 2) kết thúc bằng một hướng dẫn cụ thể cho mô hình để tạo ra các tags (như hình dưới).

Kết luận
Bài báo tập trung vào phương pháp training LLM cho một domain phức tạp là pháp lý. Qua bài báo này, các bạn sẽ có thêm ý tưởng huấn luyện mô hình và ứng dụng vào nhiều domain khác, từ cách xử lý dữ liệu đầu vào cho đến training và đánh giá
Tài liệu tham khảo
All rights reserved
