[LLM 101 - Paper reading] Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment
Đóng góp của bài báo
Các Mô hình Ngôn ngữ Lớn (LLMs) như GPT-4 thể hiện khả năng đáng kinh ngạc trong việc hiểu ý định (understanding intent), tuân theo hướng dẫn (following instructions), và thực hiện một loạt các nhiệm vụ đa dạng. Mặc dù có những năng lực này, LLMs vẫn thiếu tính chất giống con người trong giao tiếp do không có sự hiểu biết về trải nghiệm và thiếu chiều sâu cảm xúc, dẫn đến các cuộc trò chuyện kém hấp dẫn.
Để giải quyết vấn đề này, các Mô hình LLMs role-playing (đóng vai) đã được phát triển, cho phép người dùng tạo và tương tác với các hồ sơ nhân vật cá nhân, nhằm mục đích thêm chiều sâu cảm xúc vào tương tác. Tuy nhiên, hầu hết các nỗ lực hiện tại trong việc cải thiện chức năng đóng vai chỉ là bắt chước khả năng của GPT-4 bằng những mô hình open source. Những bản sao này gặp khó khăn trong việc tái tạo độ chính xác của GPT-4 và có xu hướng tạo ra thông tin không chính xác, đồng thời phải đối mặt với thách thức bổ sung là tuân thủ các điều khoản sử dụng của OpenAI. Lĩnh vực này thiếu một phương pháp rõ ràng để phát triển một mô hình đóng vai tiên tiến hơn từ đầu mà không phụ thuộc nhiều vào việc gắn nhãn dữ liệu thủ công.
Trong bài báo, nhóm tác giả giới thiệu phương pháp DITTO, cho phép LLMs đóng vai thông qua self-alignment, giảm bớt nhu cầu phải distilling output từ mô hình khác mạnh hơn. Dựa trên việc training LLMs với lượng lớn văn bản do con người tạo, DITTO khai thác kiến thức sẵn có trong LLMs về nhân vật để thực hiện đóng vai chỉ qua 2 bước: Cung cấp thông tin nhân vật và sau đó điều chỉnh phản hồi của LLM cho phù hợp. Nhóm tác giả cũng phát triển bộ dữ liệu đóng vai WIKIROLE từ 4,000 nhân vật Wikipedia, mở rộng khả năng áp dụng của DITTO.
Việc đánh giá mức độ hiệu quả cho khả năng đóng vai trong LLMs vẫn là một thách thức do phụ thuộc nhiều vào việc gán nhãn thủ công, gây tốn kém và tồn tại các vấn đề về tính nhất quán. Để giải quyết vấn đề này, nhóm tác giả đề xuất một phương pháp đánh giá đơn giản, cho phép LLMs tự động đánh giá khả năng đóng vai nhân vật của mình qua 3 tiêu chí:
- Khả năng duy trì vai nhân vật của mình một cách nhất quán
- Cung cấp kiến thức liên quan đến nhân vật một cách chính xác
- Khả năng từ chối câu hỏi không liên quan đến profile của nhân vật
Đánh giá được thực hiện thông qua các câu hỏi trắc nghiệm và chọn đúng/sai, giúp đánh giá đóng vai trở nên hiệu quả và dễ dàng hơn.
Nhóm tác giả triển khai DITTO trên các mô hình Qwen-Chat và cho thấy khả năng đóng vai ấn tượng mà không cần distilling output từ các chatbot mạnh hơn (như ChatGPT-4). Qwen-72B-Chat với DITTO đạt hiệu suất cao về nhất quán nhận dạng vai và sánh ngang với GPT-3.5-Turbo, nhưng hơi kém về kiến thức so với GPT-4.
Phương pháp
Xác định vấn đề
Để thực hiện đóng vai, các LLMs cần tham gia vào cuộc đối thoại và tạo ra tương tác nhập vai chân thực. Vì vậy, một LLM đóng vai cần phải có sự tự nhận thức vững chắc và kiến thức sâu rộng về từng nhân vật theo yêu cầu của câu hỏi.
Trong bài báo, nhóm tác giả thiết lập nhiệm vụ đóng vai bằng cách cung cấp cho LLMs tên hoặc mô tả ngắn gọn về một nhân vật cụ thể. Tiếp theo đó là đánh giá khả năng của LLMs trong việc duy trì sự tự nhận thức nhất quán và thể hiện kiến thức đặc trưng cho vai trong các cuộc đối thoại.
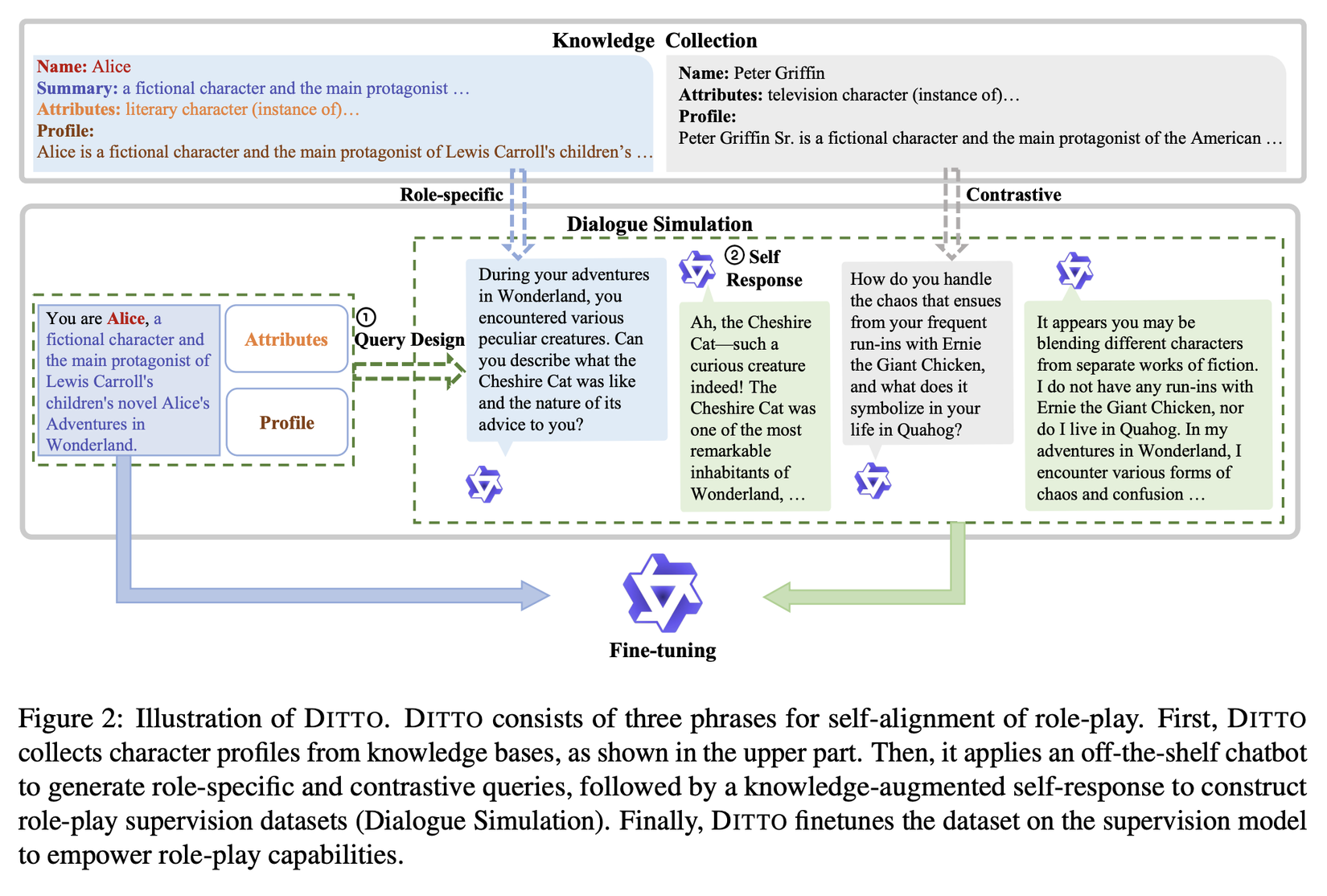
Ý tưởng của DITTO dựa trên giả định rằng các LLMs là sự chồng chất của tất cả các nhân vật, do chúng được pretrained trên một lượng lớn dữ liệu, bao gồm các cuộc trò chuyện với nhiều phong cách và lĩnh vực. DITTO phân tách nhiệm vụ đóng vai thành 2 thành phần quan trọng: Sự tự nhận thức nhất quán và kiến thức cụ thể cho từng vai.
Để đạt được mục tiêu này, DITTO thực hiện 3 bước để xây dựng bộ dữ liệu phù hợp cho bài toán này như sau: Thu thập kiến thức về nhân vật, mô phỏng đối thoại, và supervised finetuning.
Cụ thể, DITTO hoạt động trên các chatbot LLM sẵn có như Qwen-Chat, Llama-chat, hoặc Mistral-instruct. Những LLM open source này đã thể hiện khả năng follow theo hướng dẫn tốt nhưng vẫn chưa đủ khả năng đóng vai. DITTO mô phỏng đối thoại đóng vai bằng cách tái cấu trúc nó thành một nhiệm vụ đọc hiểu, sử dụng các hồ sơ nhân vật từ các tập dữ liệu public để tạo ra bộ dữ liệu đóng vai. Sau đó, finetune LLM sử dụng bộ dữ liệu tự tạo này để trang bị cho mô hình khả năng đóng vai.
Bộ sưu tập kiến thức cho nhân vật
DITTO bắt đầu bằng việc thu thập các hồ sơ nhân vật chi tiết từ các nguồn kiến thức mở như Wikidata và Wikipedia, vốn là nguồn thông tin được biên soạn bởi con người và phổ biến trong nghiên cứu ngôn ngữ tự nhiên. Nhóm tác giả thu thập tên nhân vật, mô tả, và các đặc điểm quan trọng từ Wikidata, kèm theo bài viết Wikipedia tương ứng làm hồ sơ nhân vật.
Mặc dù hiện tại chỉ tập trung vào nhân vật tiếng Trung và tiếng Anh, DITTO có thể mở rộng sang các tình huống đa ngôn ngữ phức tạp hơn do Wikidata và Wikipedia có nội dung phong phú trong nhiều ngôn ngữ.
Mô phỏng đoạn hội thoại
Quá trình mô phỏng đối thoại đóng vai được nhóm tác giả cấu trúc thành hai nhiệm vụ đọc hiểu liên tiếp: một để tạo câu hỏi và một để tạo câu trả lời.
Mô Phỏng Câu Hỏi: Nhóm tác giả sử dụng LLM để tạo ra câu hỏi liên quan và không liên quan với vai, nhằm duy trì nhận dạng vai nhất quán và từ chối câu hỏi không liên quan. Câu hỏi đặc thù cho vai đề cập đến thông tin chặt chẽ liên quan đến lý lịch của nhân vật. Ngược lại, câu hỏi đối lập yêu cầu thông tin nằm ngoài kiến thức của nhân vật. Nhóm tác giả ghép cặp các nhân vật và cung cấp hồ sơ chi tiết cho LLM để tạo ra câu hỏi mà một nhân vật có thể trả lời nhưng không phù hợp với nhân vật kia. Setting các bạn có thể tham khảo trong hình dưới:


Mô Phỏng Câu Trả Lời: Với các câu hỏi tự tạo và hồ sơ nhân vật, nhóm tác giả cũng coi mô phỏng câu trả lời như một nhiệm vụ đọc hiểu. Hồ sơ nhân vật được biến đổi theo một mẫu nhất định, sau đó câu hỏi được thêm vào phía sau hồ sơ đã được biểu đạt. LLM được kỳ vọng sẽ trích xuất thông tin liên quan từ ngữ cảnh và tạo ra câu trả lời bằng cách mô phỏng nhân vật. Quá trình này khả thi vì tất cả câu hỏi đều xuất phát từ cùng một bộ hồ sơ.

Supervised finetuning
Nhóm tác giả finetune LLM trên tập dữ liệu tự tạo để tăng cường khả năng nhập vai. Trong quá trình finetuning, họ loại bỏ kiến thức được đưa vào và chỉ giữ lại phần giới thiệu rất ngắn gọn về nhân vật. Các biến thể như vậy giúp LLM không chỉ truy xuất hồ sơ nhân vật từ một bối cảnh nhất định mà còn chứa cả kiến thức vốn có.
Kết luận
Trong bài báo này, nhóm tác giả giới thiệu một LLM có khả năng tuân theo hướng dẫn và đạt được kỹ năng đóng vai thông qua self-alignment mà không cần đến việc distill từ các mô hình mạnh như GPT-4. Kết quả thí nghiệm cho thấy hiệu quả của chiến lược self-alignment DITTO với các LLM có kích thước từ 1.8B đến 72B. Các mô hình này outperform so với tất cả các mô hình đóng vai open source hiện có mà không cần dữ liệu distilling. Dựa vào ý tưởng của bài báo mà các bạn có thể tự thiết kế một nhân vật LLM cho riêng mình 
Tài liệu tham khảo
All rights reserved
