Làm như nào để giải thích một mô hình học máy? (phần 1)
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Các mô hình học máy đã bắt đầu thâm nhập vào các lĩnh vực quan trọng, yêu cầu về tính bảo mật và độ chính xác cao như y tế, hệ thống tư pháp và ngành tài chính. Do đó, việc giải thích tại sao mô hình lại đưa ra dự đoán như vậy là một điều cần thiết, nó giúp ta đảm bảo sự tin tưởng khi áp dụng mô hình vào thực tế. 
Trong khi đó, sự tăng trưởng nhanh chóng của các mô hình học sâu làm cho việc diễn giải các mô hình ngày càng trở nên phức tạp. Chúng ta mong muốn áp dụng sức mạnh của AI vào mọi khía cạnh chính của cuộc sống hàng ngày. Tuy nhiên, thật khó để làm được điều đó nếu không có đủ tin tưởng vào các mô hình hoặc một quy trình hiệu quả để giải thích các hành vi ngoài ý muốn, đặc biệt là khi xem xét các mạng neural như một blackbox 
Thử xét một vài ví dụ sau để "cảm nhận" được tầm quan trọng của việc giải thích các mô hình:
- Ngành tài chính được quản lý chặt chẽ và luật pháp yêu cầu các tổ chức phát hành khoản vay phải đưa ra các quyết định công bằng. Việc giải thích các mô hình tín dụng là cần thiết để đưa ra lý do hợp lý cho các quyết định cho vay hay không.
- Trong y tế, việc sử dụng các mô hình liên quan trực tiếp tới sức khỏe của con người. Làm sao để chúng ta có thể tự tin trao quyền quyết định tới sức khỏe bệnh nhân cho một black-box model?
- Khi sử dụng mô hình quyết định hình sự để dự đoán nguy cơ tái phạm tại tòa án, chúng ta phải đảm bảo rằng mô hình này hành xử một cách công bằng, trung thực và không phân biệt đối xử
- Nếu một chiếc xe tự lái đột nhiên hoạt động bất thường và không thể giải thích lý do tại sao, liệu chúng ta có đủ tin tưởng để sử dụng công nghệ này trong giao thông thực tế trên diện rộng không?
Interpretable Models
Lipton (2017) đã tổng hợp các tính chất của một interpretable model trong bài báo The Mythos of Model Interpretability như sau: A human can repeat (“simulatability”) the computation process with a full understanding of the algorithm (“algorithmic transparency”) and every individual part of the model owns an intuitive explanation (“decomposability”).
Các mô hình cổ điển có sự hình thành tương đối đơn giản và đi kèm với một phương pháp giải thích cụ thể. Trong khi đó, các công cụ mới đang được phát triển để giúp tạo ra các mô hình có thể diễn giải tốt hơn (Been, Khanna, & Koyejo, 2016, Lakkaraju, Bach & Leskovec, 2016)
Regression
Công thức tổng quát của linear regression model:
Trong đó các biến độc lập là các feature của data. Kết quả của dự đoán được biểu diễn bởi giá trị .
Naive Bayes
"Naive" (ngây thơ) trong Naive Bayes là do thuật toán hoạt động trên một giả định rất đơn giản rằng các tính năng độc lập với nhau và mỗi tính năng đóng góp vào kết quả đầu ra một cách độc lập.
Cho 1 feature vector và class label , Xác suất của một điểm dữ liệu này thuộc class là
Naive Bayes Classifier được định nghĩa như sau:
Vì mô hình học giá trị trong quá trình training nên đóng góp của một feature riêng lẻ có thể được định lượng dễ dàng như sau
Decision Tree
Decision Tree là một tập các boolean function, thường được xây dựng bởi công thức if... then... else... Điều kiện if chứa một function liên quan đến một hoặc nhiều feature và trả về một output kiểu boolean. Decision Tree có khả năng diễn giải tốt và có thể được hình dung trong một cấu trúc cây. Nhiều nghiên cứu về decision tree với mục tiêu ứng dụng trong lĩnh vực y tế, trong đó khả năng diễn giải của mô hình đóng vai trò rất quan trọng.
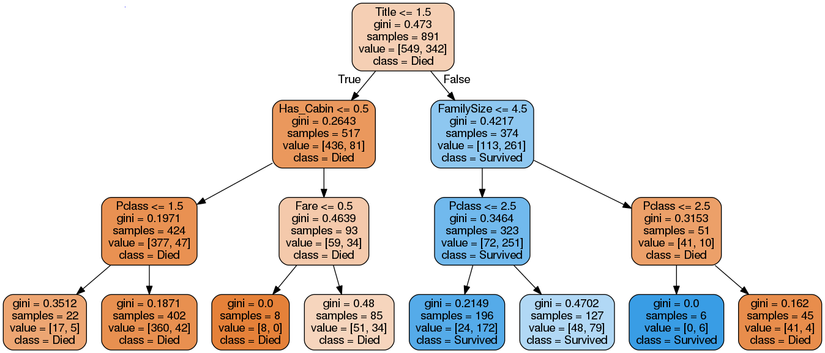
Decision tree là một mô hình supervised learning, có thể được áp dụng vào cả hai bài toán classification và regression. Việc xây dựng một decision tree trên dữ liệu huấn luyện cho trước là việc đi xác định các câu hỏi và thứ tự của chúng. Một điểm đáng lưu ý của decision tree là nó có thể làm việc với các đặc trưng (trong các tài liệu về decision tree, các đặc trưng thường được gọi là thuộc tính – attribute) dạng categorical, thường là rời rạc và không có thứ tự. Ví dụ, mưa, nắng hay xanh, đỏ, v.v. Decision tree cũng làm việc với dữ liệu có vector đặc trưng bao gồm cả thuộc tính dạng categorical và liên tục (numeric). Một điểm đáng lưu ý nữa là decision tree ít yêu cầu việc chuẩn hoá dữ liệu.
Thuật toán xây dựng decision tree phổ biến là ID3, bạn đọc có thể tìm hiểu tại đây.
Random Forests
Nhiều người cho rằng mô hình Random Forests là một blackbox, tuy nhiên điều này không đúng. Output của random forests là phiếu bầu đa số của một lượng lớn các decision tree độc lập và mỗi decision tree lại có thể diễn giải một cách rất tự nhiên Hãy đi vào thử một ví dụ cụ thể nhé
Xét bộ dữ liệu Boston housing price dataset bao gồm giá nhà tại ngoại ô Boston với các thuộc tính như chất lượng không khí (NOX), khoảng cách đến trung tâm (DIST),... Ta sẽ xây dựng decison tree với độ sâu là 3 để dự đoán giá nhà. Thường thì mỗi cây có các điều kiện trên mỗi node và giá trị đầu ra trên mỗi lá. Tuy nhiên trong hình dưới, ta bổ sung thêm giá trị tại mỗi mỗi node, đó là giá trị trung bình của response variable tại khu vực đó.
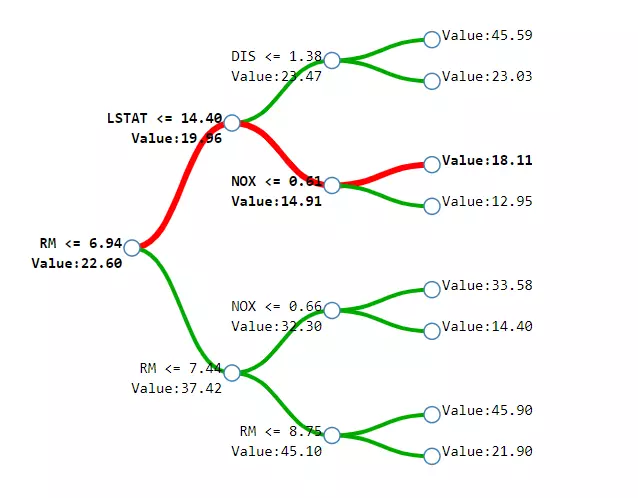
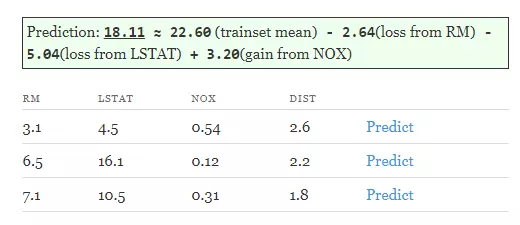
Vậy làm thế nào để chuyển từ decision tree sang random forests. Điều này khá đơn giản vì giá trị dự đoán của 1 forest là giá trị trung bình các dự đoán của các tree của forest đó , trong đó là số lượng tree trong forest.
Kết luận
Bạn có thể thấy rằng các interpretable model đều được form dưới dạng công thức toán học, điều này giúp ta dễ dàng ước lượng được mức độ quan trọng của các feature đầu vào. Tuy nhiên, các mô hình học sâu sẽ không đơn giản như vậy, ta sẽ cùng nhau tìm hiểu trong phần 2 của bài viết nhé
All rights reserved
