Gemma 4: Lý giải kiến trúc Hybrid Attention và chiến lược AI On-device
Link đính kèm:
💡 Nhận xét chung: Model này hướng tới on-device, chạy edge device hơn:
- Bỏ kĩ thuật Altup → không tăng chiều khi tính toán → ổn định hơn khi nén → giảm năng lực
- Bổ sung cơ chế PLE để tăng độ chính xác → tăng dung lượng lưu trữ.
- Hybrid Attention → giảm nhiều memory với kỹ thuật Sliding window → quên context.
- Shared KV Cache→ tăng tốc + giảm VRAM -> giảm độ chính xác
- Đối với Vision → cung cấp nhiều lựa chọn budget token để encode ảnh

Sự xuất hiện của Gemma 4 đánh dấu một bước chuyển mình chiến lược của Google DeepMind trong việc dân chủ hóa AI hiệu năng cao. Không còn chạy theo cuộc đua quy mô thuần túy, Gemma 4 tập trung vào triết lý "intelligence-per-parameter" (trí tuệ trên mỗi tham số), nhằm mang năng lực suy luận của các mô hình frontier (như Gemini 3) xuống các phần cứng dân dụng với hiệu suất "byte-for-byte" tối ưu nhất.
1. Tổng quan Kiến trúc Hệ thống
Mổ xẻ cấu trúc của Gemma 4, chúng ta thấy một hệ thống decoder-only Transformer được tinh chỉnh cực độ để đạt tới giới hạn Pareto giữa độ chính xác và chi phí tính toán. Google cung cấp bốn biến thể chiến lược của Gemma:

- Dense Models: Bao gồm 31B (mô hình chủ lực), E4B và E2B. Trong đó, ký tự "E" (Effective Parameters) ám chỉ việc sử dụng Per-Layer Embeddings để duy trì memory footprint thấp nhất có thể trong khi vẫn đạt năng lực tương đương các model lớn.
- Mixture-of-Experts (MoE): Biến thể 26B A4B (với 3.8B tham số kích hoạt - Active Parameters) là một minh chứng cho khả năng tối ưu độ trễ, cung cấp tri thức của model 26B nhưng với tốc độ thực thi của model 4B.
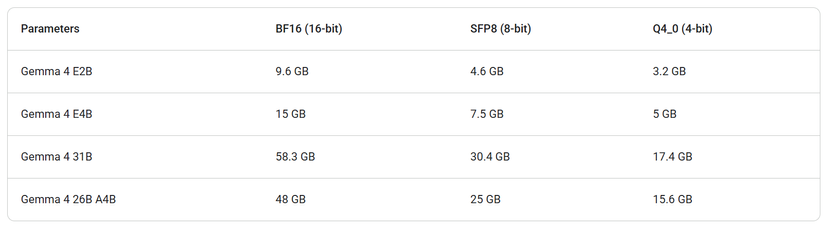
- Khi Inference thì sẽ tiêu tốn khoảng:
Sơ đồ Pipeline xử lý thông tin:
- Input Stage: Tiếp nhận đồng thời Text, Image (tỷ lệ khung hình biến thiên) hoặc Audio (trên các dòng E).
- Embedding & PLE: Chuyển đổi input thành vector thông qua bảng vocab 262K và hệ thống Per-Layer Embeddings (PLE).
- Attention Blocks: Xử lý qua các lớp Attention lai (Hybrid Attention).
- Output Stage: Sinh văn bản hoặc thực thi các Agentic Workflows (Function Calling).
Sự cải tiến này không chỉ nằm ở số lượng lớp mà còn ở cách hệ thống quản lý luồng thông tin thông qua cơ chế Attention lai để cân bằng giữa khả năng ghi nhớ và tốc độ.
2. Cơ chế Attention lai (Hybrid Attention Mechanism)
📌 Paper về cơ chế Sliding Window nền tảng tại đây.
Đánh giá về hiệu suất dài hạn, Gemma 4 giải quyết bài toán "bùng nổ bộ nhớ" bằng cách xen kẽ các lớp Local Sliding Window Attention và Global Full-Context Attention. Hình dưới đây thuộc file config.json của model google/gemma-4-E2B-it trên Hugging Face:

- Local Sliding Window: Các model nhỏ sử dụng cửa sổ 512 tokens, trong khi model 31B và 26B MoE sử dụng 1024 tokens. Điều này giúp mô hình tập trung vào các liên kết ngữ cảnh tiệm cận với chi phí .
💡 Sliding Window Attention (SWA)
- Cơ chế: Tại các lớp Local, một token chỉ được phép "nhìn" về quá khứ trong một phạm vi cố định (512 hoặc 1024 tokens).
- Bản chất toán học: Thay vì tính toán ma trận tương quan toàn phần , nó chỉ tính toán trên . Điều này biến độ phức tạp tính toán từ lũy thừa về tuyến tính .
- Hiệu ứng truyền tin: Dù mỗi lớp chỉ nhìn ngắn, nhưng nhờ cấu trúc nhiều lớp chồng lên nhau, thông tin từ token 1 vẫn truyền được đến token 10.000 thông qua các lớp SWA kế tiếp (Receptive Field mở rộng dần theo chiều sâu).
- Global Full-Context: Đảm bảo khả năng nhận thức sâu bằng cách truy xuất toàn bộ ngữ cảnh. Đáng chú ý, lớp decoder cuối cùng luôn là Global, đóng vai trò như một "phễu tổng hợp" thông tin trước khi đưa ra dự đoán.
💡 Global Full-Context
- Cơ chế: Xen kẽ giữa các cụm lớp Local là một lớp Global. Lớp này thực hiện Attention trên toàn bộ chiều dài văn bản (Full Context).
- Vai trò: Nó đóng vai trò như một điểm kiểm soát, thu thập các thông tin "bị bỏ sót" từ các cửa sổ trượt của lớp Local để đảm bảo mô hình không mất đi tính nhất quán dài hạn.
- Đặc biệt, lớp cuối cùng luôn là Global để đảm bảo từ được sinh ra đã xét toàn bộ đầu vào.
So với Gemma 2/3 hoặc các đối thủ như Llama 3 và Mistral vốn thường sử dụng Full Attention thuần túy hoặc Sliding Window cố định, cấu trúc lai của Gemma 4 giúp giảm đáng kể KV Cache, từ đó cho phép xử lý các tài liệu khổng lồ mà không làm giảm tốc độ suy luận. Cơ chế này đòi hỏi một phương pháp mã hóa vị trí tinh vi hơn để đảm bảo sự đồng nhất.
3. Mã hóa Vị trí và Xử lý Ngữ cảnh dài (Positional Encoding & Long Context)
Việc mở rộng Context Window lên đến 256K tokens (trên model 31B và 26B A4B) là một bước đi chiến lược phục vụ các Agent. Để đạt được điều này mà không cần huấn luyện lại từ đầu với chi phí khổng lồ, Google triển khai cơ chế Dual RoPE:
- Standard RoPE (Source): Áp dụng cho các lớp cửa sổ trượt (sliding window) để xử lý thông tin cục bộ.
- Proportional RoPE (p-RoPE): Đây là "vũ khí bí mật" cho các lớp global, cho phép mô hình nội suy vị trí chính xác hơn khi context kéo dài, tránh hiện tượng nhiễu thông tin.
💡 Đây là phần quan trọng nhất để Hybrid Attention hoạt động mà không bị "loạn" thứ tự từ. Cách vận hành:
- Standard RoPE (cho lớp Local): Dùng các hàm sin/cos với tần số cố định để mã hóa khoảng cách giữa các từ trong phạm vi nhỏ. Nó cực kỳ chính xác cho các quan hệ gần (như ngữ pháp,…).
- Proportional RoPE (cho lớp Global): Khi xử lý context dài (ví dụ 128k tokens), khoảng cách vị trí vượt xa những gì mô hình thấy lúc training. Proportional RoPE sẽ "nén" (scale) các bước sóng vị trí lại theo tỉ lệ chiều dài văn bản, giúp mô hình hiểu rằng "thông tin này nằm ở rất xa" mà không làm mất đi định hướng không gian.
🗒️ So với Llama 3.1: Llama 3.1 xử lý 128k bằng cách thay đổi một thông số gọi là
rope_theta(từ 10.000 lên 500.000). Cách này đơn giản nhưng đôi khi làm mô hình "quên" các chi tiết nhỏ ở gần.
- Gemma 4 thông minh hơn: nó giữ nguyên độ sắc nét ở gần (Standard RoPE) và chỉ dùng p-RoPE khi cần nhìn xa.
Minh chứng thực tế từ benchmark MRCR v2 (8 needle 128k) cho thấy Gemma 4 vượt trội so với thế hệ trước về khả năng truy xuất "kim đáy bể", một yếu tố then chốt cho việc phân tích mã nguồn hoặc tài liệu pháp lý phức tạp. Khả năng này được bổ trợ mạnh mẽ bởi các thành phần tối ưu tham số bên trong lớp Feed-Forward.
4. Thành phần Feed-Forward và Các kỹ thuật Tối ưu hóa (FFN & Optimization)
Giải mã sự hiệu quả của Gemma 4, chúng ta không thể bỏ qua kỹ thuật Per-Layer Embeddings (PLE) và Shared KV Cache.
a. Per-Layer Embeddings (PLE)
Trong Transformer truyền thống (như Llama 3,...), một từ (token) chỉ được biến thành vector 1 lần duy nhất ở lớp đầu vào (Input Embedding). Vector này phải "gồng gánh" mọi thông tin để đi qua 40-80 lớp tiếp theo. PLE giúp giải quyết vấn đề "bottleneck" ở lớp đầu vào, nó hoạt động như sau:
- Parallel: PLE tạo ra một luồng dữ liệu phụ, kích thước nhỏ hơn (low-dimensional) chạy song song với luồng chính.
- Tạo tín hiệu tại mỗi lớp: Đối với mỗi token, tại mỗi lớp decoder, nó sẽ tính toán một vector đặc biệt dựa trên sự kết hợp của:
- Thành phần Định danh (Token-identity): Tra cứu từ một bảng embedding riêng (biết token đó là chữ gì).
- Thành phần Ngữ cảnh (Context-aware): Được tạo ra bằng cách chiếu (projection) từ chính vector hiện tại của luồng chính.
- Modulation: Vector nhỏ này sau đó được "bơm" vào trạng thái ẩn (hidden states) thông qua một khối residual nhẹ ngay sau khi Attention và Feed-forward kết thúc.
- Kết quả: Thay vì nén vào 1 vector ở input, mỗi lớp bây giờ có một "kênh riêng" để nhận thông tin về token đó ngay khi thông tin đó trở nên quan trọng đối với lớp đó.
💡 Lưu ý về Đa phương thức (Multimodal):
- Vì PLE dựa trên Token ID (mã số của chữ), mà hình ảnh hay âm thanh khi vào model sẽ bị biến thành các "soft tokens" (mất ID).
- Giải pháp: Gemma 4 dùng ID của pad token làm định danh cho các vị trí đa phương thức, tạo ra một tín hiệu "trung tính" cho ảnh và âm thanh.
b. Shared KV Cache (Across Layers)
Khi AI tạo ra văn bản dài, nó phải lưu lại các giá trị Key (K) và Value (V) của tất cả các từ trước đó để "nhớ" ngữ cảnh. Đây là thứ tốn bộ nhớ VRAM nhất.
- Cắt giảm phép tính: Trong lớp cuối cùng của mô hình (gọi là
num_kv_shared_layers), mô hình không thực hiện các phép chiếu (projections) để tạo ra và mới. - Cơ chế tái sử dụng: Các lớp này sẽ lấy trực tiếp các tensor và đã được tính toán từ lớp không chia sẻ (non-shared layer) gần nhất có cùng kiểu Attention (cùng là Local hoặc cùng là Global).
- Hiệu quả: Việc này làm giảm cả khối lượng tính toán và dung lượng bộ nhớ cần thiết trong quá trình suy luận (inference).
💡 Theo file
config.jsoncủa modelgoogle/gemma-4-E2B-itthì: num_kv_shared_layers: 20
💡 Đánh giá: Google cho biết việc này có tác động cực kỳ nhỏ đến chất lượng đầu ra nhưng lại làm cho mô hình chạy cực kỳ mượt mà trên các thiết bị cá nhân (on-device) và hỗ trợ Context Window dài (Long Context) tốt hơn nhiều.
Pseudo-code mô phỏng logic Shared KV Cache:
# Logic tái sử dụng KV Cache trong Gemma 4
def forward_layer(layer_idx, hidden_states, past_kv_cache):
if layer_idx < (total_layers - num_kv_shared_layers):
# Lớp tiêu chuẩn: Tính toán K, V mới
K, V = compute_kv_projections(hidden_states)
past_kv_cache[layer_idx] = (K, V)
else:
# Lớp chia sẻ: Tái sử dụng K, V từ lớp non-shared cuối cùng
last_non_shared_idx = total_layers - num_kv_shared_layers - 1
K, V = past_kv_cache[last_non_shared_idx]
# Thực hiện Attention với KV đã chọn
attention_output = apply_attention(hidden_states, K, V)
return attention_output
Đặc biệt, Gemma 4 đã loại bỏ các tính năng phức tạp như Altup để ưu tiên tính ổn định và khả năng tương thích. Các thành phần như RMSNorm và SwiGLU vẫn được duy trì như những trụ cột của kiến trúc Transformer hiện đại.
💡
- Việc loại bỏ Altup giúp triệt tiêu các điểm đột biến (outliers), tạo ra dải dữ liệu "sạch" và ổn định hơn. Điều này giúp Gemma 4 tối ưu hóa tuyệt đối cho việc nén; các bản nén 4-bit như GGUF hay EXL2 giờ đây có thể duy trì độ thông minh gần như bản gốc ngay cả khi chạy trên các card đồ họa dân dụng.
- Thay vì dùng "cơ bắp" Altup, Google bù đắp bằng PLE để tiếp tế thông tin cho từng tầng. Kết hợp cùng RMSNorm và SwiGLU, kiến trúc này đạt sự cân bằng lý tưởng: đủ mạnh mẽ để xử lý tác vụ khó, nhưng đủ đơn giản để tương thích "native" với mọi phần cứng mà không cần tùy chỉnh phức tạp.
5. Cơ chế Tokenization hỗ trợ đa ngôn ngữ và Kiến trúc Đa phương thức
- Vocab size khổng lồ (262K): Hầu hết các mô hình cũ (như Llama 2) chỉ có 32K tokens. Với 262K, Gemma 4 có thể chứa hầu hết các từ vựng phổ biến của 140 ngôn ngữ và hàng ngàn đoạn mã code dưới dạng một token duy nhất.
- Hiệu ứng nén: Thay vì một từ tiếng Việt phức tạp phải chia làm 3-4 tokens (đánh vần từng chữ), Gemma 4 có thể xử lý nó chỉ trong 1 token. điều này giúp:
- Tốc độ nhanh hơn: Xử lý ít token hơn trên cùng một đoạn văn bản.
- Hiểu sâu hơn: Mô hình nắm bắt ý nghĩa của cả từ/cụm từ thay vì ghép nối các mảnh vụn.
- Sự kết hợp với PLE: Khi xử lý ảnh/âm thanh (không có ID), mô hình dùng mã của "pad token" để PLE vẫn có thể bơm tín hiệu vào từng lớp, giúp duy trì sự đồng nhất về mặt kiến trúc cho cả dữ liệu text và multimodal.
- Gemma 4 theo đuổi chiến lược Native Multimodal, tích hợp encoder đa phương thức trực tiếp vào sequence thay vì sử dụng các wrapper rời rạc.
- Vision Encoder (2D RoPE & Flexible Budgets)
- Multidimensional RoPE (2D RoPE): Thay vì đánh số vị trí từ 1 đến , nó gán cho mỗi mảnh ảnh (patch) một tọa độ . Khi thực hiện cơ chế Attention, thay vì chỉ xoay vector theo 1 chiều (thời gian/thứ tự), nó sử dụng RoPE đa chiều để xoay vector theo cả trục tung và trục hoành.
- Visual Token Budget (Linh hoạt): Đây là điểm rất hay. Thông thường, một ảnh sẽ bị nén thành một số lượng token cố định (ví dụ 256). Gemma 4 cho phép thay đổi "ngân sách" này từ 70 đến 1120 tokens.
- How: Sử dụng các lớp Learned Pooling hoặc Resampler. Nếu bạn cần quét nhanh (phân loại ảnh), nó nén ảnh thành 70 tokens. Nếu bạn cần đọc một tờ hóa đơn (OCR), nó sẽ dùng 1120 tokens để giữ lại mọi chi tiết sắc nét.
- Audio Encoder: Gemma 4 có thể "nghe" trực tiếp âm thanh dài tới 30 giây mà không cần chuyển thành văn bản trước.
- USM-style Conformer: Đây là kiến trúc kết hợp giữa Transformer (để hiểu ngữ cảnh dài) và CNN (để bắt các đặc trưng âm thanh nhanh như âm tiết, tông giọng).
- Bản chất: Nó quét sóng âm thanh và biến các đặc trưng sóng (spectrogram) thành một chuỗi các vector (soft tokens). Các vector này sau đó được trộn lẫn (interleaved) với các token văn bản.
- Fusion::
-
Gemma 4 coi mọi thứ là Sequence of Vectors (Chuỗi các vector): chữ = Text Tokens, ảnh = Visual Tokens, âm thanh = Audio Tokens. Tất cả được xếp hàng cùng nhau, lớp Attention sẽ không phân biệt đây là chữ hay ảnh, nó chỉ tính toán: "Vector ảnh này có liên quan gì đến từ ngữ đứng trước nó không?".
-
PLE với Đa phương thức (Cực kỳ quan trọng):
- Vấn đề: Như đã nói, PLE cần Token ID để "nhắc bài". Nhưng ảnh/tiếng là các "soft tokens" (vector thô, không có ID).
- Giải pháp (How): Gemma 4 gán toàn bộ các vị trí chứa ảnh/âm thanh bằng ID của [PAD] token.
- Bản chất: Điều này tạo ra một tín hiệu "trung tính" cho PLE ở các lớp đa phương thức, giúp mô hình không bị lỗi logic khi đang xử lý từ ngữ (có ID cụ thể) bỗng dưng gặp một mảng ảnh (không có ID).
-
- Vision Encoder (2D RoPE & Flexible Budgets)
💡 Tóm tắt luồng xử lý:
- Output: AI trả lời bạn bằng văn bản hoặc mã code.
- Processing: Đi qua các lớp Hybrid Attention (nhìn xa - nhìn gần) và được PLE hỗ trợ tín hiệu từng tầng.
- Fusion: Tất cả đan xen vào nhau thành một hàng dài.
- Encoding: - Vision Encoder dùng 2D RoPE cắt ảnh thành các tọa độ không gian. - Audio Encoder dùng Conformer bắt lấy nhịp điệu tiếng nói. - Tokenizer biến câu hỏi thành các 262K Vocab IDs.
- Input: Bạn đưa vào 1 ảnh, 1 đoạn voice và 1 câu hỏi.
6. Kỹ thuật Trainning model Gemma 4
- Quy trình huấn luyện Gemma 4 sử dụng dữ liệu cập nhật đến tháng 1 năm 2025, bao gồm Web, Code, Toán học và dữ liệu đa phương thức quy mô lớn.
- Google áp dụng quy trình căn chỉnh (Alignment) ba lớp: SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) và DPO (Direct Preference Optimization). Để đảm bảo an toàn, các bộ lọc CSAM và dữ liệu nhạy cảm được triển khai nghiêm ngặt, giúp giảm tỷ lệ từ chối vô lý (unjustified refusals) trong khi vẫn duy trì hàng rào đạo đức AI vững chắc.
- Gemma 4 chứng minh sự thay đổi về tư duy kiến trúc thông qua các tính năng nhắm trực tiếp vào người dùng chuyên nghiệp:
- Thinking Mode (Chế độ tư duy): Kích hoạt qua token
<|think|>. Mô hình sẽ suy luận từng bước trong kênh<|channel>thought.- Lưu ý kỹ thuật: Đối với model 31B và 26B MoE, khi tắt chế độ tư duy, mô hình vẫn sinh ra các tag nhưng với một khối thinking rỗng (
<|channel>thought\n<channel|>). Đây là chi tiết cực kỳ quan trọng khi xử lý luồng output của model.
- Lưu ý kỹ thuật: Đối với model 31B và 26B MoE, khi tắt chế độ tư duy, mô hình vẫn sinh ra các tag nhưng với một khối thinking rỗng (
- Native System Prompt: Hỗ trợ vai trò "System" chính thức, cho phép định hình hành vi mô hình một cách nhất quán hơn.
- Function Calling: Hỗ trợ gọi hàm bản địa và xuất định dạng JSON chính xác, tối ưu cho các agentic workflows.
- Thinking Mode (Chế độ tư duy): Kích hoạt qua token
7. Hiệu năng thực tế và Triển khai On-device (Efficiency & Deployment)
- Nhờ sự kết hợp của MoE, PLE và Shared KV Cache, Gemma 4 định nghĩa lại khả năng AI On-device. Biến thể 26B A4B (MoE) đạt được sweet spot khi chỉ kích hoạt 3.8B tham số, cho tốc độ phản hồi tức thì trên laptop GPUs.
- Mô hình có khả năng tương thích hoàn hảo với
llama.cpp,transformers.js, vàMLX, chạy mượt mà trên Android (thông qua AICore), Raspberry Pi và NVIDIA Jetson Orin Nano. Điều này mở ra kỷ nguyên AI đa phương thức hoàn toàn ngoại tuyến (offline), bảo vệ quyền riêng tư tuyệt đối. - So sánh Kiến trúc và Triết lý Thiết kế: Triết lý của Google với Gemma 4 là sự minh bạch và hiệu quả tuyệt đối dưới giấy phép Apache 2.0.
| Tiêu chí | Gemma 4 (31B) | Gemma 3 (27B) | Llama 3 (70B) | Mistral (Large 2) |
|---|---|---|---|---|
| Context Window | 256K | 128K | 128K | 128K |
| Multimodality | Native (Text/Img/Audio) | Text/Img | Text only | Text only |
| Active Params | 31B | 27B | 70B | 123B |
| Cơ chế Attention | Hybrid (Sliding/Global) | Global | Global | Sliding/Global |
| Thinking Mode | Có (Native) | Không | Không | Không |
- Sample triển khai:
from transformers import pipeline
pipe = pipeline("any-to-any", model="google/gemma-4-e2b-it")
# Pass in images and text as follows
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/thailand.jpg",
},
{"type": "text", "text": "Do you have travel advice going to here?"},
],
}
]
output = pipe(messages, max_new_tokens=100, return_full_text=False)
output[0]["generated_text"]
# Based on the image, which appears to show a magnificent, ornate **Buddhist temple or pagoda**, likely in Southeast Asia (such as Thailand, Myanmar, or Cambodia), here is some general travel advice..
# Inferring with videos, you can include the audio track
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/thailand.jpg",
},
{"type": "text", "text": "Do you have travel advice going to here?"},
],
}
]
output = pipe(messages, max_new_tokens=100, return_full_text=False)
output[0]["generated_text"]
# Based on the image, which appears to show a magnificent, ornate **Buddhist temple or pagoda**, likely in Southeast Asia (such as Thailand, Myanmar, or Cambodia), here is some general travel advice..
8. Finetune google/gemma-4-E2B-it (Text)
📌 Link code fine-tune tham khảo của Unsloth: Source
Data sample cho text: <bos><|turn>user Bạn là trợ lý ảo chuyên nghiệp của FashionShop. Bạn nắm rõ thông tin về ERP, quy trình vận hành và định vị thương hiệu. Hãy trả lời dựa trên bối cảnh công ty đã cung cấp. Cho anh hỏi bên mình ai là người chịu trách nhiệm chính về việc đối soát doanh thu và quản lý kho vận vậy?> <turn|>
<|turn>model Dạ, theo sơ đồ tổ chức của FashionShop, người chịu trách nhiệm đầu-cuối cho quy trình này là Head of Operations (Trưởng phòng Vận hành) ạ. Anh ấy quản lý các phân hệ Đơn hàng, Kho và Tài chính trên ERP để đảm bảo việc đối soát và giao nhận diễn ra trơn tru.<turn|>
Kết luận: Gemma 4 không chỉ là một bản nâng cấp, mà là một lời khẳng định về khả năng tối ưu hóa kiến trúc đỉnh cao. Việc kết hợp giữa năng lực suy luận sâu (Thinking Mode), đa phương thức bản địa và hiệu suất thực thi trên thiết bị cá nhân biến Gemma 4 trở thành cột mốc quan trọng nhất trong hệ sinh thái mô hình mở năm 2026.
All Rights Reserved
