Batch Processing và Stream Processing: Khám phá hai phương pháp xử lý dữ liệu chủ lực
Bài đăng này đã không được cập nhật trong 2 năm
Trong thế giới ngày càng phụ thuộc vào dữ liệu như hiện nay, hai phương pháp xử lý dữ liệu chủ lực là Batch Processing và Stream Processing đang chứng tỏ mức độ quan trọng và tác động mạnh mẽ của mình. Hãy cùng mình tìm hiểu thêm về hai phương pháp này, các công cụ hỗ trợ, và các ứng dụng thực tế.
1. Batch Processing: Cơ bản và ứng dụng
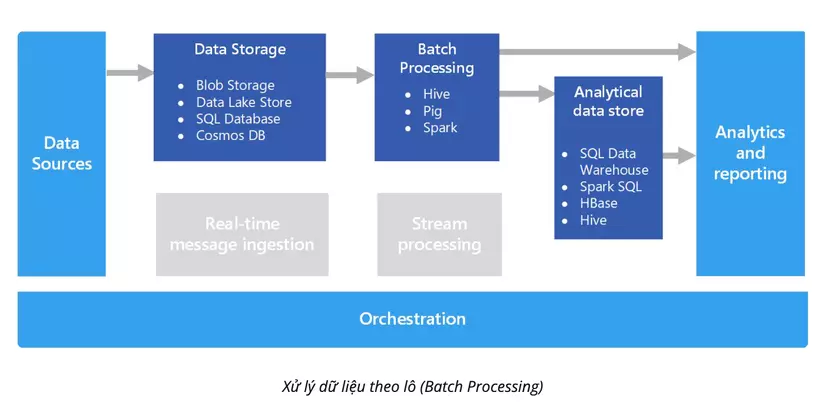
Batch Processing, hay xử lý dữ liệu theo lô, là việc xử lý một tập dữ liệu lớn mà không cần tương tác người dùng trong quá trình xử lý. Điều này thường được thực hiện với những tác vụ đòi hỏi thời gian xử lý lớn, chẳng hạn như phân tích dữ liệu lớn, xử lý hóa đơn hàng loạt, hoặc thậm chí là xử lý giao dịch ngân hàng hàng loạt.
Công cụ hỗ trợ
Hadoop, Spark, Hive và MapReduce là những công cụ hàng đầu hỗ trợ Batch Processing.
1. Hadoop:
Hadoop là một framework mã nguồn mở được thiết kế để lưu trữ và xử lý dữ liệu lớn trên một cụm máy tính với phần cứng chuẩn. Hadoop gồm hai thành phần chính: Hadoop Distributed File System (HDFS) để lưu trữ dữ liệu và Hadoop MapReduce để xử lụy dữ liệu. Hadoop cho phép chúng ta xử lý dữ liệu hàng loạt bằng cách phân chia công việc xử lý trên nhiều máy tính trong cụm.
2. Spark:
Apache Spark là một hệ thống xử lý dữ liệu phân tán mã nguồn mở, tối ưu cho tốc độ, sự dễ dùng, và tính linh hoạt. Spark có thể xử lý dữ liệu hàng loạt và dữ liệu theo dòng (streaming), hỗ trợ một loạt các tác vụ, từ phân tích dữ liệu đến học máy. Spark thường nhanh hơn Hadoop MapReduce, đặc biệt khi thực hiện nhiều tác vụ xử lý trên cùng một tập dữ liệu.
3. Hive:
Apache Hive là một dự án mã nguồn mở được phát triển bởi Apache và cung cấp một giao diện SQL-like để truy vấn dữ liệu lưu trữ trong các hệ thống phân tán như Hadoop. Hive giúp đơn giản hóa việc phân tích dữ liệu hàng loạt với Hadoop bằng cách cung cấp ngôn ngữ HiveQL giống SQL, thuận tiện cho những người đã quen thuộc với SQL.
4. MapReduce:
MapReduce là mô hình lập trình cho việc xử lý và tạo ra dữ liệu hàng loạt. MapReduce là một thành phần cốt lõi của Hadoop. Nó tách quá trình xử lý thành hai pha: pha Map và pha Reduce. Trong pha Map, dữ liệu đầu vào được chia thành các tập hợp nhỏ và được xử lý đồng thời. Sau đó, kết quả của pha Map được tổng hợp và xử lý trong pha Reduce để tạo ra kết quả cuối cùng.
Tất cả các công cụ trên đều hỗ trợ xử lý dữ liệu hàng loạt, nhưng chúng có những đặc điểm và lợi ích riêng biệt. Lựa chọn công cụ phù hợp sẽ phụ thuộc vào nhu cầu cụ thể của dự án và tập dữ liệu của bạn.
-
Hadoop thường được chọn cho các tác vụ yêu cầu xử lý dữ liệu hàng loạt lớn và phức tạp trên cụm máy tính phân tán. Nó cho phép bạn mở rộng quy mô cụm theo nhu cầu, và cung cấp độ tin cậy cao bằng cách sao lưu dữ liệu trên nhiều máy tính.
-
Spark thì lại nhanh hơn Hadoop và có thể xử lý cả dữ liệu hàng loạt và dữ liệu dòng (streaming). Spark cũng cung cấp các thư viện mạnh mẽ cho học máy và khoa học dữ liệu, làm cho nó trở thành một lựa chọn tốt cho các tác vụ phân tích dữ liệu nâng cao.
-
Hive là công cụ phù hợp cho những người đã quen với SQL và muốn áp dụng kỹ năng SQL của mình để phân tích dữ liệu hàng loạt trên Hadoop. Hive cũng hữu ích khi bạn cần chuyển đổi dữ liệu lớn từ Hadoop vào cơ sở dữ liệu SQL.
-
MapReduce là một mô hình lập trình hữu ích khi bạn muốn tạo các ứng dụng phân tán từ đầu. MapReduce đòi hỏi một chút hiểu biết về lập trình Java, nhưng nó cho phép bạn tận dụng toàn bộ sức mạnh của Hadoop.
Đây chỉ là khái quát, mỗi công cụ cung cấp một loạt các tính năng và tùy chỉnh, vì vậy việc tìm hiểu kỹ hơn về từng công cụ sẽ giúp bạn đưa ra quyết định phù hợp nhất với nhu cầu cụ thể của mình.
Ứng dụng thực tế
Batch Processing thường được sử dụng trong các ứng dụng yêu cầu xử lý dữ liệu lớn mà không cần đến kết quả tức thì, như phân tích dữ liệu quy mô lớn, thống kê, dự báo, hoặc xử lý giao dịch hàng loạt.
1. Phân tích dữ liệu quy mô lớn: Do không yêu cầu sự tương tác người dùng trong quá trình xử lý, Batch Processing rất phù hợp với việc phân tích tập dữ liệu lớn. Các doanh nghiệp và tổ chức thường sử dụng Batch Processing để phân tích lưu lượng truy cập web, thông tin khách hàng, kết quả bán hàng, và nhiều hơn nữa. Ví dụ, một công ty có thể dùng Batch Processing vào cuối mỗi ngày để tổng hợp và phân tích dữ liệu bán hàng.
2. Xử lý giao dịch ngân hàng: Các ngân hàng và tổ chức tài chính thường sử dụng Batch Processing để xử lý hàng loạt các giao dịch, như chuyển tiền, rút tiền, và thanh toán hóa đơn. Những giao dịch này thường được tổng hợp vào cuối ngày và được xử lý như một batch.
3. Thống kê và dự báo: Batch Processing thường được sử dụng trong việc thống kê và dự báo. Dữ liệu từ nhiều nguồn khác nhau được tổng hợp và xử lý hàng loạt để tạo ra các dự báo về thị trường, xu hướng tiêu dùng, hoặc các dự báo khác.
4. Xử lý hóa đơn hàng loạt: Các doanh nghiệp thường sử dụng Batch Processing để xử lý hóa đơn hàng loạt. Điều này bao gồm việc tạo, gửi, và theo dõi hóa đơn cho hàng trăm hoặc thậm chí hàng nghìn khách hàng cùng một lúc.
5. Xử lý dữ liệu trên hệ thống máy chủ: Một số tác vụ như sao lưu dữ liệu, cập nhật phần mềm, hoặc chạy các công việc lịch biểu thường được thực hiện như các quá trình Batch Processing, thường xuyên vào thời điểm nào đó trong ngày khi tải hệ thống thấp.
Như vậy, Batch Processing là một phương pháp mạnh mẽ cho việc xử lý dữ liệu lớn mà không yêu cầu sự tương tác người dùng, điều này cung cấp hiệu quả và tiết kiệm thời gian đáng kể.
2. Stream Processing: Cơ bản và ứng dụng
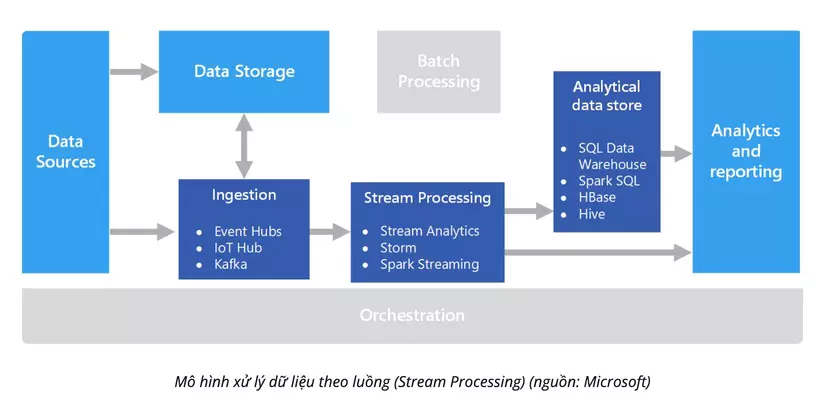
Khác với Batch Processing, Stream Processing là quá trình xử lý dữ liệu gần như ngay lập tức sau khi nó được tạo ra. Điều này đặc biệt hữu ích khi cần xử lý và phân tích dữ liệu theo thời gian thực.
Công cụ hỗ trợ
Apache Kafka, Apache Flink, Storm và Google Cloud Dataflow là những công cụ hàng đầu hỗ trợ Stream Processing.
1. Apache Kafka:
Apache Kafka là một hệ thống phân tán mã nguồn mở được thiết kế để xử lý luồng dữ liệu theo thời gian thực. Kafka được thiết kế để xử lý luồng dữ liệu quy mô lớn, đáng tin cậy, và có khả năng mở rộng linh hoạt. Kafka thường được sử dụng trong các hệ thống vận hành theo thời gian thực, như theo dõi hoạt động người dùng trực tuyến, phân tích luồng dữ liệu từ các cảm biến IoT, hoặc làm hệ thống trung gian cho việc truyền dữ liệu giữa các hệ thống khác nhau.
2. Apache Flink:
Apache Flink là một framework mã nguồn mở cho việc xử lý dữ liệu theo dòng (streaming) và hàng loạt (batch) với độ trễ thấp và quy mô lớn. Flink được thiết kế để chạy trên các cụm máy tính phân tán và cung cấp khả năng xử lý dữ liệu theo thời gian thực, khả năng khôi phục sau khi lỗi và mô hình lập trình dễ sử dụng.
3. Storm:
Apache Storm là một hệ thống xử lý dữ liệu theo thời gian thực mã nguồn mở. Storm cho phép bạn xử lý dữ liệu theo thời gian thực bằng cách sử dụng các luồng dữ liệu không giới hạn, và cung cấp khả năng xử lý sự cố, mở rộng, và cân đối tải. Storm thích hợp cho nhiều ứng dụng, từ xử lý luồng dữ liệu IoT cho đến phân tích dữ liệu theo thời gian thực.
4. Google Cloud Dataflow:
Google Cloud Dataflow là một dịch vụ xử lý dữ liệu theo thời gian thực và hàng loạt được quản lý hoàn toàn trên Google Cloud Platform. Dataflow tự động điều chỉnh quy mô tài nguyên dựa trên yêu cầu công việc, giúp bạn xử lý lượng dữ liệu lớn mà không cần quan tâm đến việc quản lý cơ sở hạ tầng. Dataflow cung cấp mô hình lập trình đơn giản, giúp bạn tập trung vào việc viết mã mà không phải quan tâm đến chi tiết của hệ thống.
Những công cụ này đều mang lại những lợi ích riêng biệt:
-
Apache Kafka có khả năng xử lý luồng dữ liệu lớn và đáng tin cậy, giúp nó trở thành lựa chọn hàng đầu cho việc theo dõi dữ liệu trong thời gian thực và truyền dữ liệu giữa các hệ thống khác nhau.
-
Apache Flink có khả năng xử lý cả dữ liệu theo dòng (streaming) và hàng loạt (batch), cho phép bạn lựa chọn phương pháp xử lý phù hợp nhất với nhu cầu của mình.
-
Storm cung cấp khả năng xử lý dữ liệu theo thời gian thực mạnh mẽ, cho phép bạn xử lý luồng dữ liệu không giới hạn và cân đối tải hiệu quả.
-
Google Cloud Dataflow cung cấp một dịch vụ quản lý hoàn toàn, giúp bạn tập trung vào việc viết mã mà không phải quan tâm đến việc quản lý cơ sở hạ tầng.
Như vậy, việc lựa chọn công cụ phù hợp sẽ phụ thuộc vào yêu cầu cụ thể của dự án, quy mô và loại dữ liệu bạn cần xử lý, cũng như nguồn lực và kỹ năng có sẵn.
Ứng dụng thực tế
Stream Processing thường được sử dụng trong các ứng dụng yêu cầu thời gian thực, như giám sát hệ thống, phân tích dữ liệu trực tuyến, phân tích mạng xã hội, phân tích hành vi người dùng và xử lý dữ liệu từ các cảm biến IoT.
1. Phân tích dữ liệu theo thời gian thực: Stream Processing giúp các tổ chức phân tích dữ liệu ngay lập tức khi dữ liệu được tạo ra, cho phép họ có cái nhìn tức thì về hoạt động kinh doanh. Ví dụ, các công ty thương mại điện tử có thể dùng Stream Processing để theo dõi hành vi mua hàng của khách hàng theo thời gian thực và tạo ra các gợi ý sản phẩm phù hợp.
2. Giám sát và cảnh báo: Stream Processing cung cấp khả năng phát hiện và phản ứng nhanh chóng với các sự kiện quan trọng. Ví dụ, các hệ thống giám sát giao thông có thể dùng Stream Processing để phát hiện và cảnh báo ngay lập tức về các vụ tai nạn giao thông.
3. Xử lý dữ liệu từ thiết bị IoT: Các thiết bị IoT (Internet of Things) thường tạo ra luồng dữ liệu liên tục. Stream Processing giúp xử lý và phân tích dữ liệu này theo thời gian thực, cho phép các tổ chức dự đoán và phản ứng nhanh chóng với các sự kiện. Ví dụ, hệ thống giám sát chất lượng không khí trong một thành phố có thể dùng Stream Processing để theo dõi mức độ ô nhiễm không khí và cảnh báo ngay lập tức khi mức độ ô nhiễm vượt quá ngưỡng cho phép.
4. Quảng cáo theo thời gian thực: Stream Processing cho phép các công ty quảng cáo cung cấp quảng cáo theo thời gian thực dựa trên hành vi người dùng. Điều này có thể bao gồm việc hiển thị quảng cáo dựa trên trang web mà người dùng đang xem hoặc dựa trên vị trí địa lý của họ.
5. Phân tích truyền thông xã hội: Stream Processing giúp các công ty phân tích dữ liệu từ các nền tảng truyền thông xã hội theo thời gian thực, cho phép họ theo dõi xu hướng và phản ứng nhanh chóng với các sự kiện. Ví dụ, các công ty marketing có thể sử dụng Stream Processing để theo dõi các hashtag trên Twitter và phản ứng nhanh chóng với các chủ đề đang hot.
6. Phát trực tuyến: Stream Processing rất quan trọng trong việc xử lý dữ liệu video và âm thanh trực tuyến. Các công ty như Netflix và Spotify sử dụng Stream Processing để cung cấp dịch vụ streaming chất lượng cao cho khách hàng của họ.
7. Thị trường tài chính: Trong thị trường tài chính, Stream Processing được sử dụng để theo dõi dữ liệu thị trường trong thời gian thực, bao gồm giá cả, giao dịch, và tin tức, giúp các nhà đầu tư và trader phản ứng nhanh chóng với các biến đổi của thị trường.
8. Xử lý dữ liệu máy móc: Stream Processing giúp xử lý dữ liệu máy móc trong thời gian thực, bao gồm dữ liệu từ cảm biến và log hệ thống. Điều này giúp tăng cường hiệu suất, khả năng dự báo lỗi, và quản lý hiệu quả hơn.
Có thể thấy rằng, Stream Processing là một công nghệ mạnh mẽ giúp các tổ chức xử lý dữ liệu theo thời gian thực và tận dụng dữ liệu ngay lập tức. Bằng cách xử lý dữ liệu ngay khi nó được tạo ra, Stream Processing giúp cải thiện hiệu quả, tăng tốc độ phản hồi, và mở ra cơ hội mới cho phân tích dữ liệu.
Kết luận
Mỗi phương pháp đều có ưu điểm và nhược điểm riêng. Trong khi Batch Processing phù hợp với các tác vụ đòi hỏi xử lý lượng dữ liệu lớn và không cần kết quả ngay lập tức, Stream Processing lại cung cấp sự linh hoạt trong việc phân tích và xử lý dữ liệu theo thời gian thực.
Quyết định sử dụng phương pháp nào phụ thuộc vào nhu cầu cụ thể của từng dự án. Một số dự án cần xử lý dữ liệu hàng loạt để tạo ra báo cáo tổng hợp hàng ngày, trong khi những dự án khác lại cần xử lý dữ liệu theo thời gian thực để có thể đưa ra quyết định tức thì. Đôi khi, các công ty cũng kết hợp cả hai phương pháp để đáp ứng đủ nhu cầu của họ.
Điều quan trọng là hiểu rõ về mỗi phương pháp, cách chúng hoạt động, và cách chúng có thể được áp dụng vào các tình huống cụ thể. Công nghệ ngày càng tiến bộ, và việc xử lý dữ liệu sẽ ngày càng trở nên phức tạp hơn. Tuy nhiên, bằng cách hiểu rõ và sử dụng đúng các công cụ và phương pháp, chúng ta có thể tận dụng tối đa giá trị từ dữ liệu.
Cuối cùng, cần lưu ý rằng công nghệ không bao giờ thay thế được quá trình tư duy, phân tích, và đưa ra quyết định của con người. Công cụ và phương pháp chỉ là hỗ trợ để chúng ta có thể làm việc hiệu quả hơn, những việc đưa ra quyết định cuối cùng về cách sử dụng dữ liệu vẫn phụ thuộc vào chúng ta.
All rights reserved
