Boruta - Một thuật toán mạnh mẽ cho lựa chọn đặc trưng
Feature selection là một bước cơ bản trong các Machine learning pipeline. Ta có trong tay một đống "thập cẩm" các feature, công việc bây giờ là chọn những feature quan trọng và bỏ những feature không cần thiết đi. Mục tiêu là đơn giản hóa vấn đề bằng cách xóa đi các feature có thể dẫn đến nhiễu không cần thiết.
Boruta là một thuật toán hiệu quả được thiết kế để tự động thực hiện feature selection trên một tập dữ liệu. Ban đầu thuật toán này được đóng gói trên ngôn ngữ R. Sau này phiên bản Boruta cho Python được phát triển và ta chỉ việc import và sử dụng thoai 
Trong bài viết này, chúng ta sẽ tìm hiểu tường tận thuật toán này hoạt động ra sao và cách implement nó như thế nào. Thay vì chỉ import thư viện, việc cài đặt lại từ đầu sẽ giúp ta hiểu rõ ràng về thuật toán này hơn 
Bắt đầu với dữ liệu
Để xem thuật toán hoạt động như nào, ta sẽ bắt đầu với bộ dữ liệu giả định với 3 feature (age, height và weight) cùng với một biến mục tiêu (income). Bộ dữ liệu này gồm 5 mẫu.
import pandas as pd
### make X and y
X = pd.DataFrame({'age': [25, 32, 47, 51, 62],
'height': [182, 176, 174, 168, 181],
'weight': [75, 71, 78, 72, 86]})
y = pd.Series([20, 32, 45, 55, 61], name = 'income')
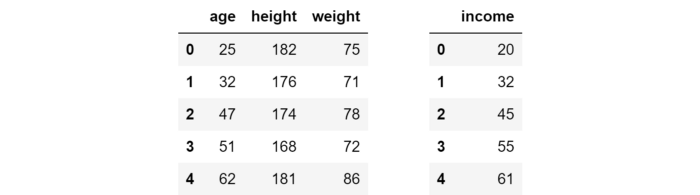
Mục tiêu là dự đoán thu nhập của một người dựa vào tuổi, chiều cao và cân nặng. Nghe có vẻ sai sai và không có ý nghĩa gì nhỉ (ít nhất là trên lý thuyết: Trên thực tế, chiều cao đã được chứng minh là có liên quan đến mức thu nhập của một người link), nhưng nói chung, bạn không nên bị ảnh hưởng bởi sự thiên vị của suy nghĩ
Trong tình huống thực tế, ta thường phải làm việc với nhiều feature hơn (thường là hàng trăm đến hàng nghìn feature). Vì vậy, sẽ là không khả thi khi ta phải duyệt thủ công từng feature một và quyết định xem có nên giữ feature này hay không. Ngoài ra, có những mối quan hệ giữa feature và biến mục tiêu (mối quan hệ phi tuyến tình, interaction) mà ta rất khó để có thể nhìn ra dễ dàng, kể cả khi sử dụng các phân tích.
Lý tưởng nhất, chúng ta muốn tìm một thuật toán có thể tự quyết định xem bất kỳ feature nào đã cho của X có mang một giá trị dự đoán nào đó về y hay không.
Tại sao lại là Boruta?
Một thuật toán phổ biến cho feature selection là sklearn.feature_selection.SelectFromModel. Cơ bản, bạn chọn một model có khả năng nắm bắt các mối quan hệ và interaction phi tuyến tính, ví dụ: random forest và ta sẽ fit model này trên X và y. Sau đó, ta trích xuất mức độ quan trọng của từng feature từ model này và chỉ giữ các feature có mức độ quan trọng trên ngưỡng threshold.
Điều này nghe có vẻ hợp lý, nhưng điểm yếu của cách tiếp cận như vậy là rất rõ ràng: Làm cách nào để chọn được threshold một cách chính xác? Việc chọn threshold đều rất ngẫu nhiên và vô căn cứ.
Boruta giải quyết vấn đề này với 2 ý tưởng cốt lõi.
Shadow feature
Trong thuật toán Boruta, các feature không cạnh tranh với nhau, chúng cạnh tranh với chính phiên bản ngẫu nhiên của chúng.
Đầu tiên, ta tạo một dataframe mới bằng cách xáo trộn ngẫu nhiên mỗi feature trong X. Hoán vị các feature này được gọi là shadow feature. Sau đó, shadow feature được gắn vào dataframe ban đầu để có được dataframe mới (ta gọi là X_boruta), có số cột gấp đôi X.
import numpy as np
### make X_shadow by randomly permuting each column of X
np.random.seed(42)
X_shadow = X.apply(np.random.permutation)
X_shadow.columns = ['shadow_' + feat for feat in X.columns]
### make X_boruta by appending X_shadow to X
X_boruta = pd.concat([X, X_shadow], axis = 1)
X_boruta sẽ như sau:
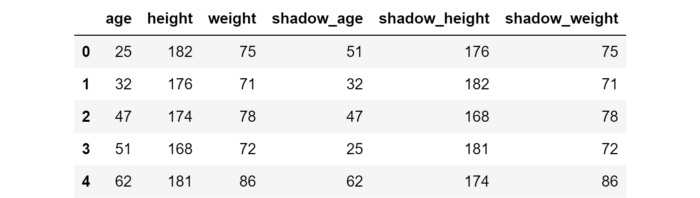
Okay! Giờ ta sẽ fit model Random forest vào X_boruta và y.
Bước tiếp theo ta sẽ lấy mức độ quan trọng của mỗi feature gốc và so sánh với một threshold. Threshold ở đây được định nghĩa là giá trị mức độ quan trọng lớn nhất có được từ các shadow feature. Ý tưởng ở đây là một feature được coi là hữu ích nếu như mức độ quan trọng của feature này có giá trị lớn hơn threshold. Khi mức độ quan trọng của một feature lớn hơn threshold, ta gọi đó là "hit".
Nghe hơi khó hiểu đúng không? Xem đoạn code dưới là hiểu ngay thôi
from sklearn.ensemble import RandomForestRegressor
### fit a random forest (suggested max_depth between 3 and 7)
forest = RandomForestRegressor(max_depth = 5, random_state = 42)
forest.fit(X_boruta, y)
### store feature importances
feat_imp_X = forest.feature_importances_[:len(X.columns)]
feat_imp_shadow = forest.feature_importances_[len(X.columns):]
### compute hits
hits = feat_imp_X > feat_imp_shadow.max()
Ta có kết quả như sau:

Threshold ở đây có giá trị 14% (giá trị lớn nhất trong 3 giá trị 11%, 14% và 8%). Vậy 2 feature tạo hit là age (39%) và height (19%), trong đó weight (8%) có giá trị nhỏ hơn threshold.
Tuy nhiên, làm sao để ta có thể tin tưởng được giá trị threshold này. Liệu đây có phải là một sự hên xui khi chọn age và height là feature hữu ích và bỏ feature weight. Ý tưởng thứ 2 giúp ta giải quyết vấn đề này
Binomial distribution
Để tăng mức độ tin cậy, một cách rất tự nhiên là ta sẽ lặp lại các thử nghiệm. 20 lần lặp chắc chắn sẽ đáng tin cậy hơn 1 lần lặp Ví dụ dưới đây sẽ minh họa cách làm đó
### initialize hits counter
hits = np.zeros((len(X.columns)))
### repeat 20 times
for iter_ in range(20):
### make X_shadow by randomly permuting each column of X
np.random.seed(iter_)
X_shadow = X.apply(np.random.permutation)
X_boruta = pd.concat([X, X_shadow], axis = 1)
### fit a random forest (suggested max_depth between 3 and 7)
forest = RandomForestRegressor(max_depth = 5, random_state = 42)
forest.fit(X_boruta, y)
### store feature importance
feat_imp_X = forest.feature_importances_[:len(X.columns)]
feat_imp_shadow = forest.feature_importances_[len(X.columns):]
### compute hits for this trial and add to counter
hits += (feat_imp_X > feat_imp_shadow.max())
Ta có kết quả sau:

Bây giờ, làm thế nào để chúng ta thiết lập một tiêu chí quyết định? Đây là ý tưởng tuyệt vời thứ hai có trong Boruta.
Ta thử xét một feature bất kỳ và giả sử rằng hoàn toàn không biết liệu nó có hữu ích hay không. Xác suất mà ta sẽ giữ nó là bao nhiêu? Mức độ không chắc chắn tối đa về feature được thể hiện bằng xác suất 50%, giống như tung đồng xu. Vì mỗi thử nghiệm độc lập có thể cho một kết quả nhị phân (hit hoặc không hit), một chuỗi n thử nghiệm tuân theo binomial distribution.
Trong python, hàm khối xác suất của binomial distribution được tính như sau:
import scipy as sp
trials = 20
pmf = [sp.stats.binom.pmf(x, trials, .5) for x in range(trials + 1)]
Giá trị của nó sẽ giống như một cái chuông như hình dưới
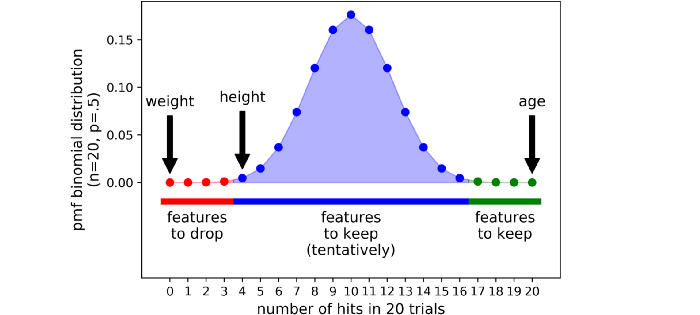
Trong Boruta, không có một threshold cứng giữa vùng nhận và không nhận. Thay vào đó ta có 3 vùng sau:
- Vùng từ chối (màu đỏ): Các feature nằm ở đây được coi là nhiễu, vì vậy chúng bị loại bỏ
- Vùng lưỡng lự, thăm dò (khu vực màu xanh lam): Boruta do dự về các feature trong khu vực này
- Vùng chấp nhận (khu vực màu xanh lá cây): các feature ở đây được coi là hữu ích, vì vậy chúng được giữ lại.
Các vùng được xác định bằng cách chọn hai phần cực đoan nhất của phân phối được gọi là các phần đuôi của phân phối (trong ví dụ trên, mỗi phần đuôi chiếm 0,5% của phân phối).
Ta đã thực hiện 20 lần lặp lại dữ liệu và kết thúc với một số kết luận có cơ sở thống kê:
- Để dự đoán thu nhập của một người, feature age là quan trọng và được giữ lại, weight chỉ là noise và nên bỏ đi
- Boruta không rõ ràng về feature height: Sự lựa chọn là tùy thuộc vào chúng ta, nhưng nếu là một người cẩn thận, bạn có thể giữ feature này
Sử dụng Boruta trong Python
Cài đặt Boruta qua pip
!pip install boruta
Ta sử dụng thư viện này như sau
from boruta import BorutaPy
from sklearn.ensemble import RandomForestRegressor
import numpy as np
###initialize Boruta
forest = RandomForestRegressor(
n_jobs = -1,
max_depth = 5
)
boruta = BorutaPy(
estimator = forest,
n_estimators = 'auto',
max_iter = 100 # number of trials to perform
)
### fit Boruta (it accepts np.array, not pd.DataFrame)
boruta.fit(np.array(X), np.array(y))
### print results
green_area = X.columns[boruta.support_].to_list()
blue_area = X.columns[boruta.support_weak_].to_list()
print('features in the green area:', green_area)
print('features in the blue area:', blue_area)
Feature được lưu trong boruta.support_ là những feature nằm trong vùng chấp nhận, do vậy ta có thể thêm vào model của mình. Các feature được lưu trong boruta.support_weak_ nằm trong vùng từ chối hoặc lưỡng lự và lựa chọn thêm vào model hay không là tùy chúng ta phụ thuộc mục đích sử dụng.
Kết luận
Feature selection là một phần quyết định của quá trình học máy: Quá thận trọng sẽ dẫn đến sử dụng những feature noise không cần thiết, trong khi quá lạc quan lại loại bỏ những thông tin hữu ích. Trong bài viết này, chúng ta đã xem cách sử dụng Boruta để thực hiện lựa chọn feature mạnh mẽ, có căn cứ về mặt thống kê trên tập dữ liệu. Thật vậy, việc đưa ra các quyết định về các feature là rất quan trọng để đảm bảo sự thành công của mô hình dự đoán của bạn.
All rights reserved
